-
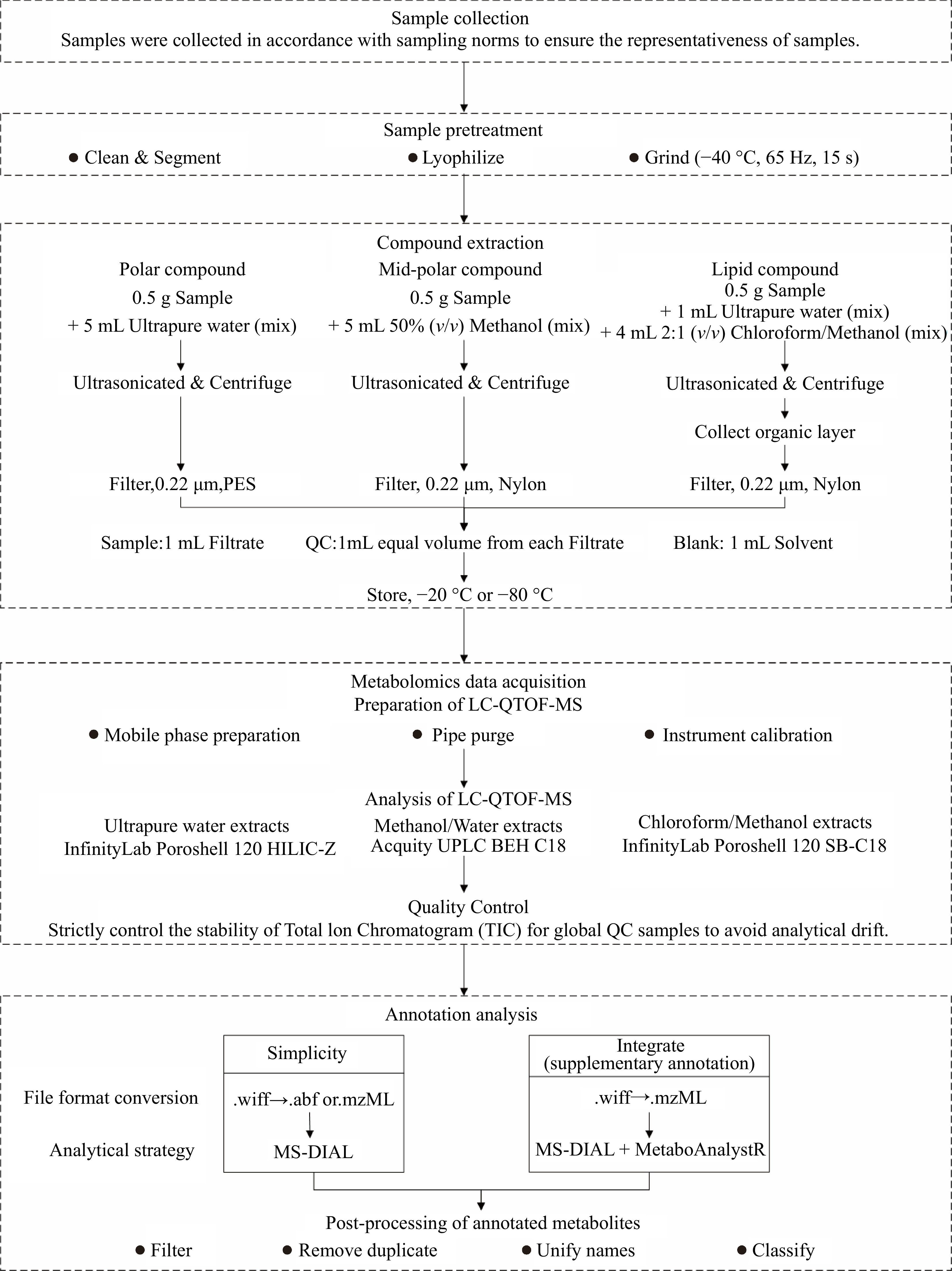
Figure 1.
Flowchart of metabolomics analysis for high annotation coverage of metabolites in fruits, vegetables, and their products.
-
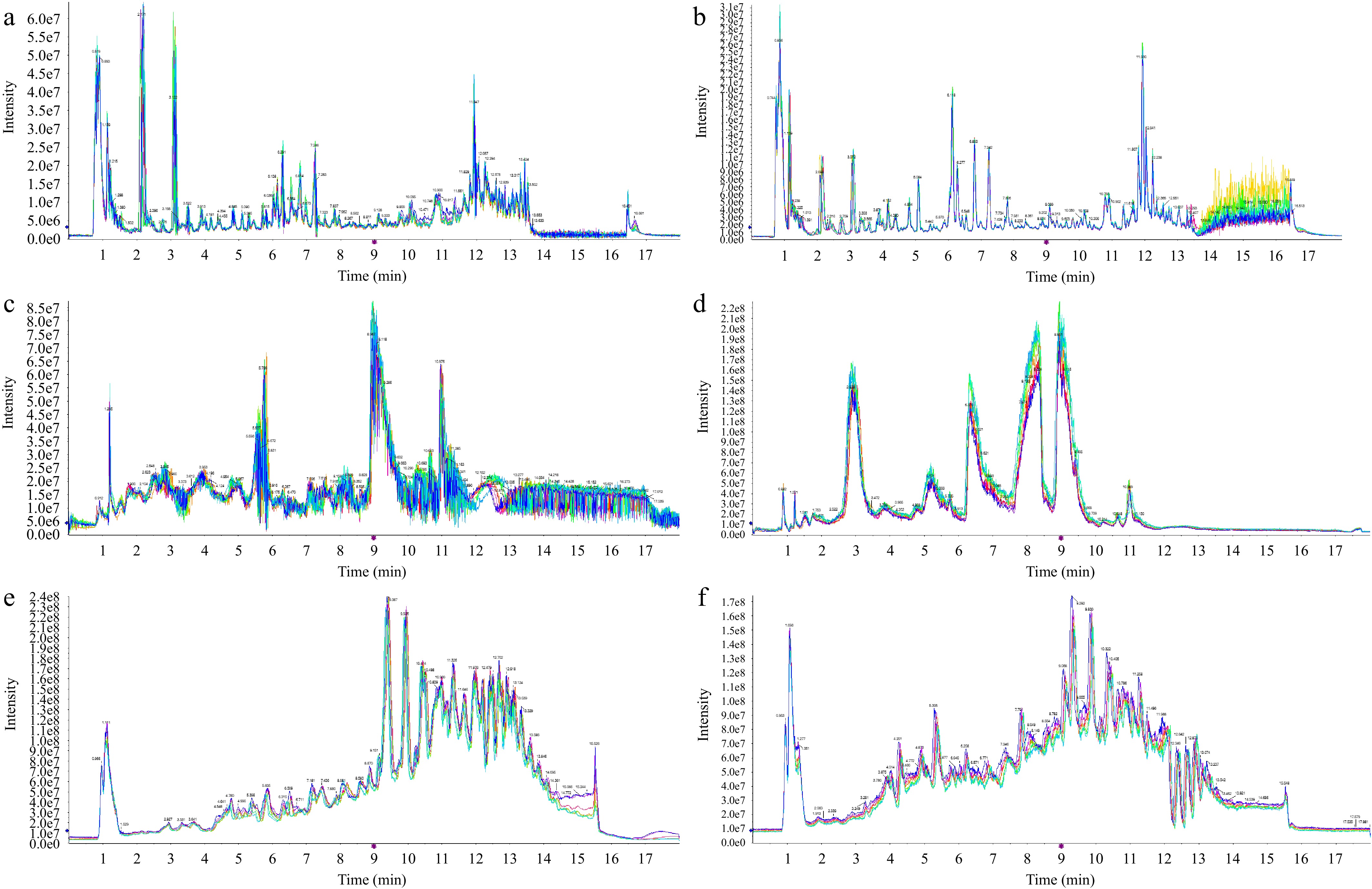
Figure 2.
TIC plot of QC samples. (a) Methanol-C18 group, acquired in positive ion mode. (b) Methanol-C18 group, acquired in negative ion mode. (c) Water-HILIC group, acquired in positive ion mode. (d) Water-HILIC group, acquired in negative ion mode. (e) Lipid-C18 group, acquired in positive ion mode. (f) Lipid-C18 group, acquired in negative ion mode.
-
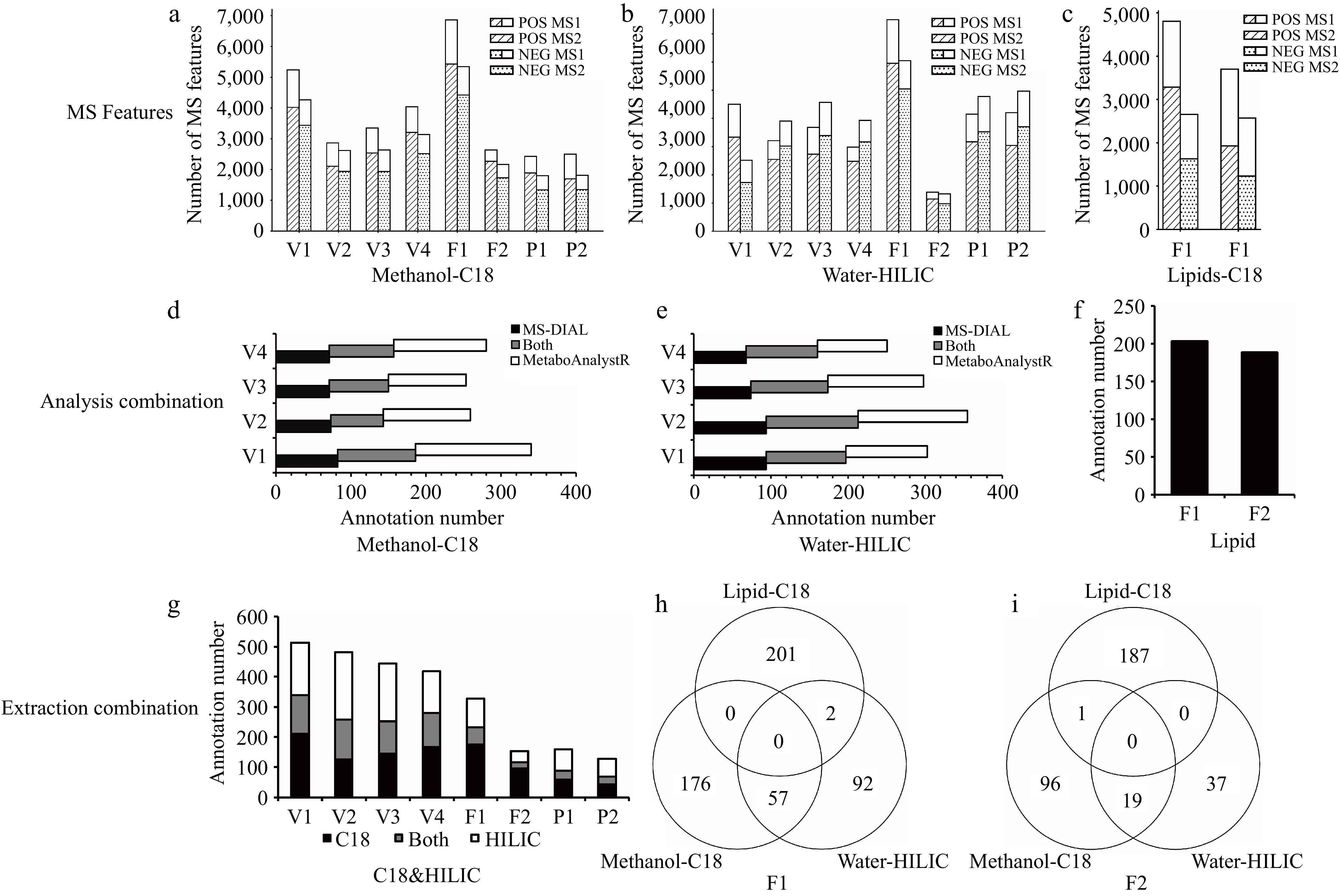
Figure 3.
Strategy evaluation results. MS features of all samples in positive (POS) and negative (NEG) ion modes: (a) Methanol-C18 group, (b) Water-HILIC group, and (c) Lipid-C18 group. Combination of annotation results from different analysis tools (merge positive and negative ion modes) (d) Combination of annotation results from MS-DIAL and MetaboAnalystR in the Methanol-C18 group, (e) combination of annotation results from MS-DIAL and MetaboAnalystR in the Water-HILIC group, and (f) annotation results from MS-DIAL (lipidomics module) in the Lipid-C18 group. Combination of annotation results from different extraction groups: (g) combination of annotation results from Methanol-C18 group and Water-HILIC group, (h), (i) Venn plots of annotated metabolites extracted by three methods for two types of fruit.
-
import pandas as pd import requests import time lotus_cache = {} pubchem_cache = {} def process_inchikey(inchikey): if inchikey[-4] == 'N': return inchikey[:-4] + 'S' + inchikey[-3:] return inchikey def get_lotus_name(inchikey): inchikey = process_inchikey(inchikey) if inchikey in lotus_cache: return lotus_cache[inchikey] url = f" https://lotus.naturalproducts.net/api/search/simple?query={inchikey} "max_retries = 3 for attempt in range(max_retries): try: response = requests.get(url) if response.status_code == 200: data = response.json() if 'naturalProducts' in data and len(data['naturalProducts']) > 0: product = data['naturalProducts'][0] if 'traditional_name' in product: lotus_cache[inchikey] = product['traditional_name'] return product['traditional_name'] except requests.exceptions.RequestException as e: print(f"Request error for {inchikey}: {e}") time.sleep(3) lotus_cache[inchikey] = "Not Found" return "Not Found" def get_pubchem_name(inchikey): inchikey = process_inchikey(inchikey) if inchikey in pubchem_cache: return pubchem_cache[inchikey] url = f" https://pubchem.ncbi.nlm.nih.gov/rest/pug/compound/inchikey/{inchikey}/synonyms/JSON "max_retries = 3 for attempt in range(max_retries): try: response = requests.get(url) if response.status_code == 200: data = response.json() if 'InformationList' in data and 'Information' in data['InformationList'] and len(data['InformationList']['Information']) > 0: info = data['InformationList']['Information'][0] if 'Synonym' in info and len(info['Synonym']) > 0: pubchem_cache[inchikey] = info['Synonym'][0] return info['Synonym'][0] except requests.exceptions.RequestException as e: print(f"Request error for {inchikey}: {e}") time.sleep(3) pubchem_cache[inchikey] = "Not Found" return "Not Found" xls = pd.ExcelFile("your input path") with pd.ExcelWriter("your output path") as writer: for sheet_name in xls.sheet_names: df = pd.read_excel(xls, sheet_name=sheet_name) if 'InchiKey' in df.columns: df['Lotus Name'] = df['InChiKey'].apply(get_lotus_name) df['Pubchem Name'] = df['InChiKey'].apply(get_pubchem_name) time.sleep(1) df.to_excel(writer, sheet_name=sheet_name, index=False) Table 1.
The script for the unification of compound names.
-
import pandas as pd import requests import time def process_inchikey(inchikey): if inchikey[-4] == 'N': return inchikey[:-4] + 'S' + inchikey[-3:] return inchikey def get_classification_info(inchikey): inchikey = process_inchikey(inchikey) url = f" http://classyfire.wishartlab.com/entities/{inchikey}.json "max_retries = 5 for attempt in range(max_retries): try: response = requests.get(url) if response.status_code == 200: classification = response.json() subclass = (classification.get('subclass') or {}).get('name', 'Not available') class_ = (classification.get('class') or {}).get('name', 'Not available') superclass = (classification.get('superclass') or {}).get('name', 'Not available') return subclass, class_, superclass except requests.exceptions.RequestException as e: print(f"Request error for {inchikey}: {e}") time.sleep(3) return "Error", "Error", "Error" xls_named = pd.ExcelFile("your input path") with pd.ExcelWriter("your output path") as writer: for sheet_name in xls_named.sheet_names: df = pd.read_excel(xls_named, sheet_name=sheet_name) if ' InChiKey ' in df.columns: df[['Subclass', 'Class', 'Superclass']] = df['InChiKey'].apply(lambda x: pd.Series(get_classification_info(x))) time.sleep(1) df.to_excel(writer, sheet_name=sheet_name, index=False) Table 2.
The script for the classification of metabolites.
-
Problem Possible reason Solution The compounds have the wrong adduction. Database may contain non-standard adduct ion forms, leading to adduct misassignment in the annotation information of MS-DIAL. The exact mass is calculated from the molecular formula and compared to the average m/z detected, and the correct adduct ion is modified to match the difference between the exact mass and the average m/z. The script for batch calculation of exact mass is given in Algorithm 3. Compounds are annotated repeatedly. Deconvolution algorithms may not be able to accurately separate the signals of complex mixtures, resulting in the signal of one compound being separated into multiple features and annotated by the database. Select the perfect one with the highest matching score (refer to total score, dot product score, etc.) and response intensity for comprehensive judgment. The searched compound names show 'Not Found', or don't correspond to the name given by the analysis tools (not the same substance). The InChiKey or compound name of the compounds recorded in the database is incorrect. For compounds that could not be matched or matched incorrectly, manually search on PubChem and modify the InChiKey or metabolite names. Common error in Python script. The column name does not contain a character matching 'InChiKey' (for Algorithm 1 and 2) or 'Formula' (for Algorithm 3).
The file path is incorrect.
The corresponding package is not installed.Check the correctness of column names and file paths, and install the corresponding packages. Table 1.
Troubleshooting table.
-
import pandas as pd import re from pyteomics import mass def calculate_monoisotopic_mass(chemical_formula): if not isinstance(chemical_formula, str): return None pattern = r'([A-Z][a-z]*)(\d*)' monoisotopic_mass = 0 for symbol, count in re.findall(pattern, chemical_formula): count = int(count) if count else 1 monoisotopic_mass += count * mass.nist_mass[symbol][0][0] return monoisotopic_mass file_path = ' your path' sheets = pd.ExcelFile(file_path) sheet_names = sheets.sheet_names writer = pd.ExcelWriter(file_path, mode='a', engine='openpyxl', if_sheet_exists='replace') for sheet_name in sheet_names: sheet_df = pd.read_excel(file_path, sheet_name=sheet_name) formula_columns = [col for col in sheet_df.columns if 'Formula' in col] for formula_col in formula_columns: exact_mass_col = f'Exact Mass ({formula_col})' sheet_df[exact_mass_col] = sheet_df[formula_col].apply(calculate_monoisotopic_mass) sheet_df.to_excel(writer, sheet_name=sheet_name, index=False) writer.close() Table 3.
The script for the calculation of exact mass.
Figures
(3)
Tables
(4)