-
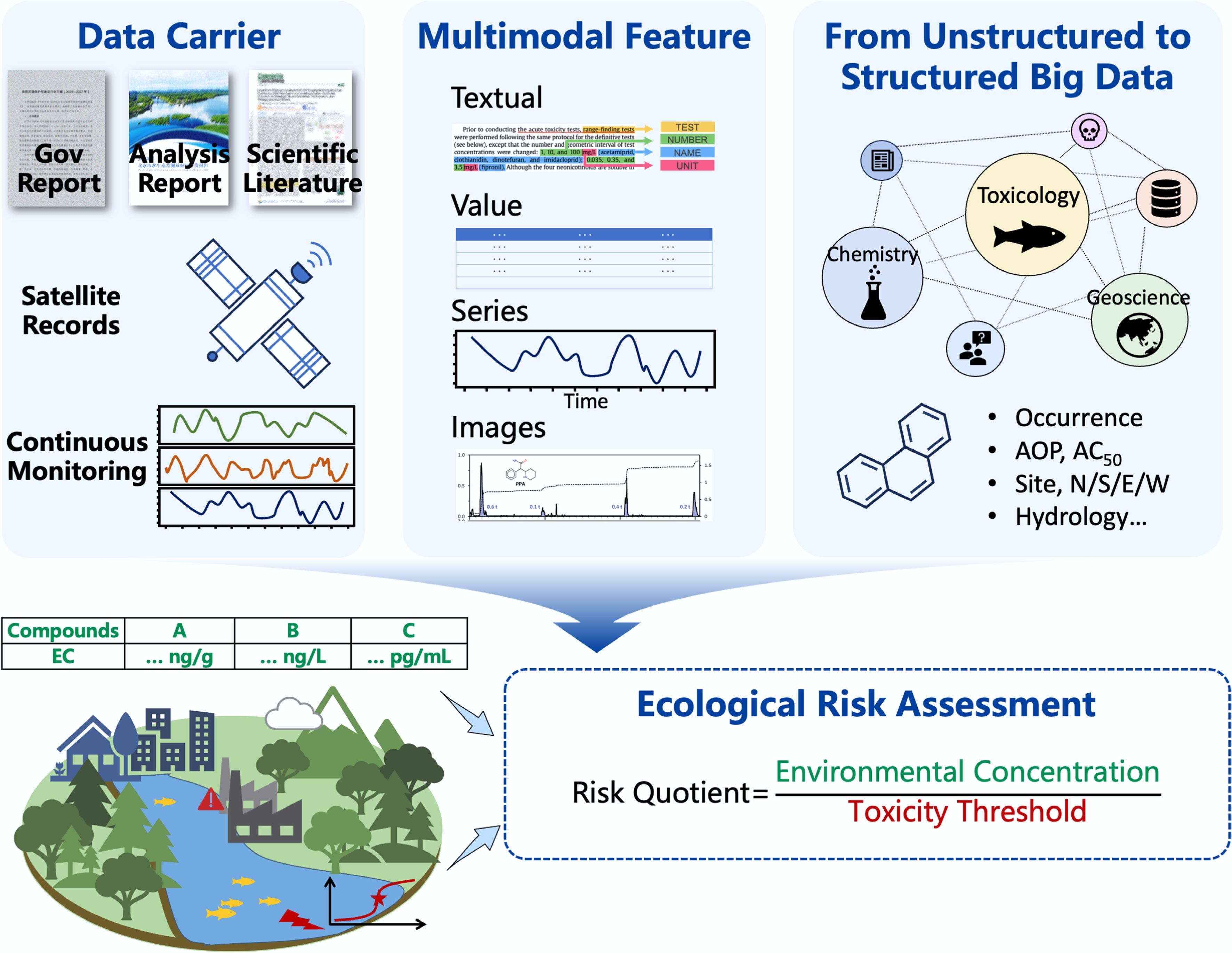
Figure 1.
Potential use of large language models (LLMs) in aquatic ecological risk assessment. The LLMs are expected to transform unstructured multimodal environmental data into structured data and then serve aquatic ecological risk assessment.
-
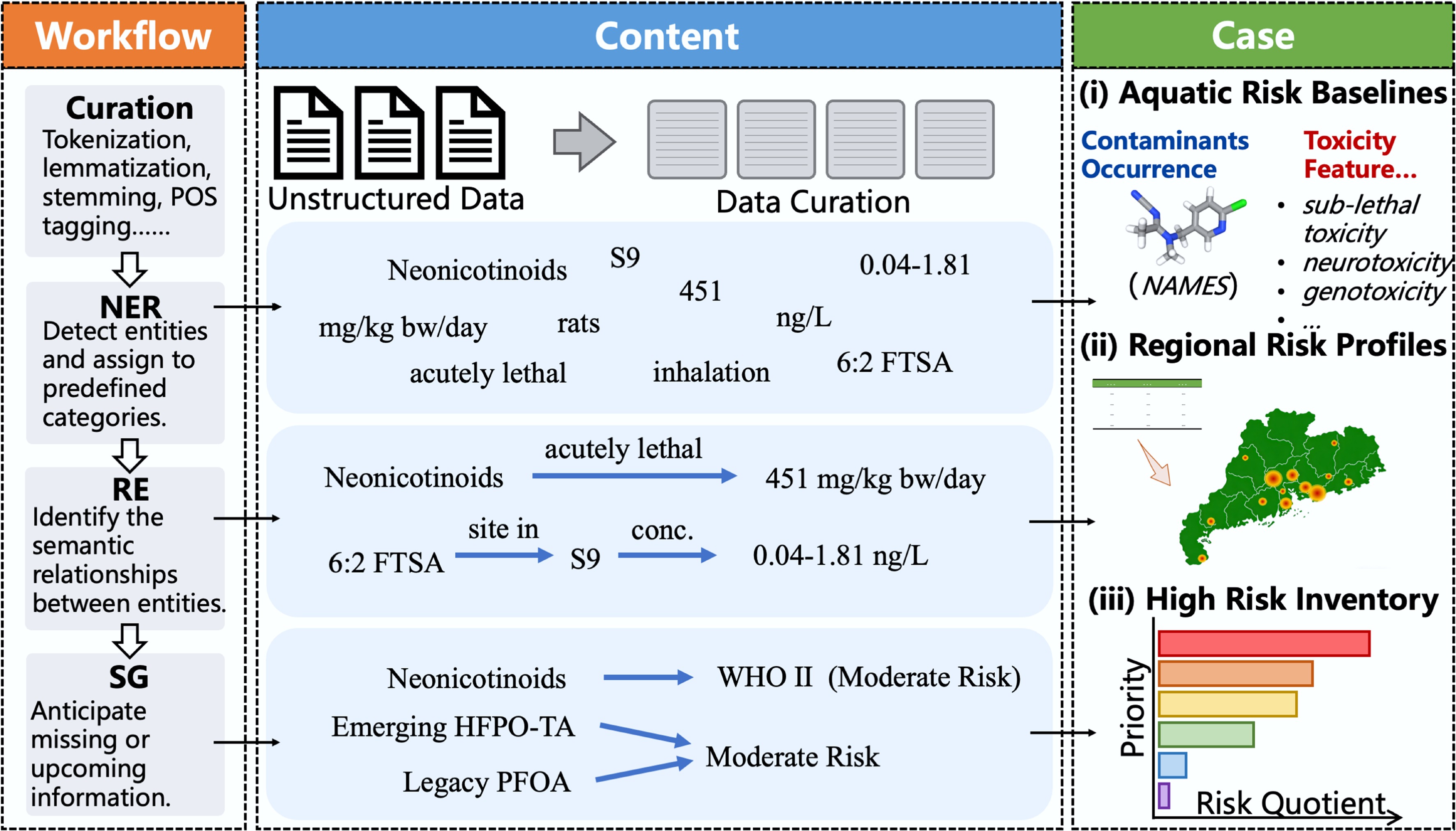
Figure 2.
Schematic diagram of a workflow for ecological risk assessment (ERA) based on natural language processing (NLP). Left panel shows a workflow of NLP, which converts unstructured text into structured data through sequential stages, including Data Curation, Named Entity Recognition (NER), Relation Extraction (RE), and Semantic Generation (SG). Middle panel shows structured output content. Taking texts from a publication in the field of ERA as an example, this section illustrates the NLP corpus preprocessing step. Right panel presents a case in ERA to explain a proposed end-to-end process, in which an environmental risk assessment of emerging contaminants (e.g., neonicotinoids) in the Pearl River was conducted. Through data extraction and information correlation, aquatic risk baselines, including occurrence and toxicity features of these contaminants, were obtained. Subsequent risks were profiled in the region, ultimately leading to the prioritization of a high-risk inventory.
-
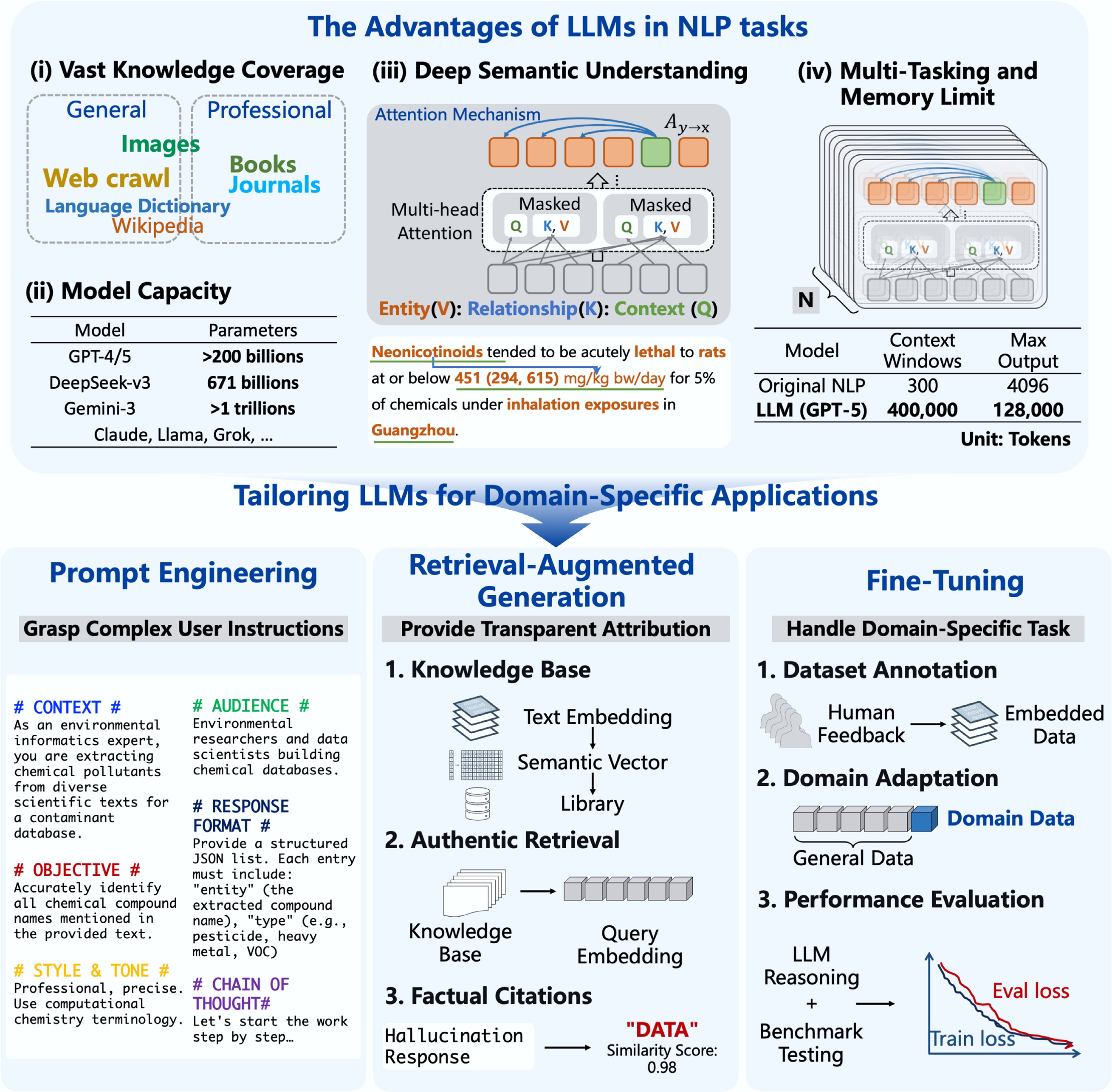
Figure 3.
The architecture and optimized strategies of LLMs. Compared to original NLP methods, LLMs were trained on extensive corpora, feature parameter scales in the billions, and were capable of deep semantic understanding, multi-task handling, and long-context retention. To adapt LLMs to domain-specific tasks, three primary optimization techniques are commonly employed, including prompt engineering, retrieval-augmented generation (RAG), and fine-tuning.
-
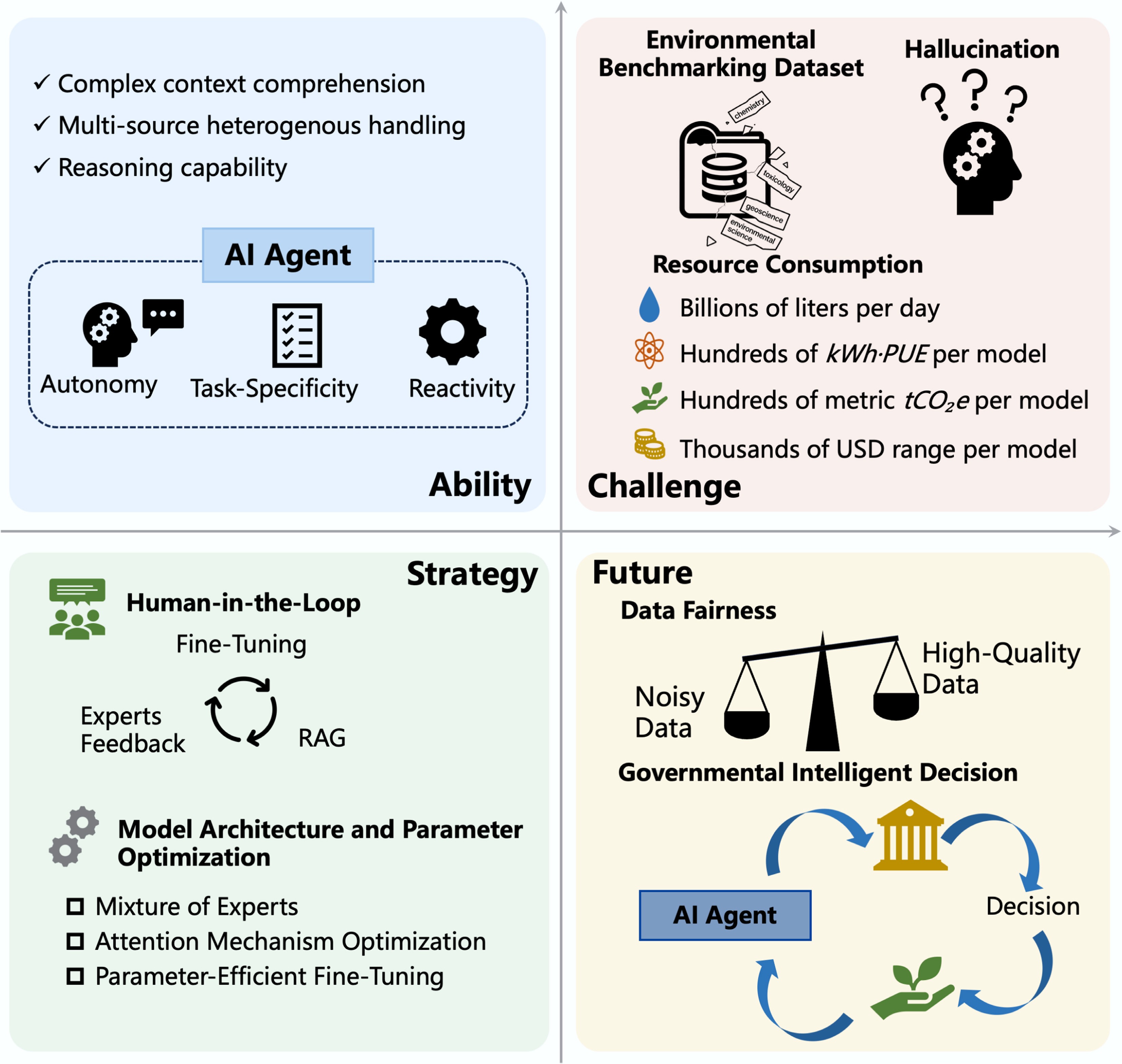
Figure 4.
The ability, challenge, strategy, and future of LLMs. AI agents enable the integration of multiple LLMs, thereby enhancing the level of task automation. LLMs still face challenges such as insufficient environmental data, hallucinations, and high resource consumption. Human-in-the-loop strategies can guide model learning and improve output reliability. Optimizing model architecture and parameters remains a conventional yet effective method for performance enhancement. In the future, greater attention should be directed toward improving data quality, ensuring data fairness, and leveraging AI agents to build intelligent systems that support governmental decision-making.
-
Tasks Category Performance Ref. Oxidative stress inventory extraction NER Through optimization of prompt engineering on GPT-4, the values of 0.91, 0.81, and 0.86 were achieved for precision, recall, and F1 score, respectively. [9] Host-dopant extraction NER, RE Llama-2 (precision = 0.836, recall = 0.807, F1 = 0.821) outperforms MatBERT-Proximity (precision = 0.377, recall = 0.403, F1 = 0.390) in terms of overall performance. [8] Note information extraction NER, RE GENIE (F1 = 0.837, accuracy = 0.912) outperforms cTAKES (F1 = 0.182, accuracy = 0.748). [11] Object detection and waterbody extraction RE, SG WaterGPT achieves an accuracy of 0.96 on simple tasks and 0.90 on complex tasks. [24] MOFs prediction and generation SG The accuracy analysis reports 96.9% and 95.7% for the search and prediction tasks, respectively. [31] Expert-level question answering SG GPT-4 achieves a relevance of 0.644 and a factuality of 0.791. [36] Molecular property prediction SG In classification tasks within the field of physiology, the AUC-ROC improved from the previous state-of-the-art of 74.53% to 76.60%; in biophysics classification tasks, the average AUC-ROC reached 79.10; for regression tasks in physical chemistry, the average RMSE was 1.54; and in quantum mechanics tasks, the average MAE was 5.8233, representing a 48.2% improvement over the baseline. [39] Modeling complex toxicity pathways and predicting steroidogenesis SG In the classification task for target inhibitors, MolBART achieved an AUC above 0.85 and an F1 score over 0.7; in the task of predicting IC50 values, it attained an R2 over 0.7, with an MAE below 0.5 and an RMSE under 0.8. [40] Table 1.
The applications and performance of large language models (LLMs) in data mining and information extraction tasks
Figures
(4)
Tables
(1)