








-
The service-oriented computing (SOC) paradigm uses services to support the development of rapid, low-cost, interoperable, evolvable, and massively distributed applications. Services are considered autonomous, platform-independent entities that can be described, published, discovered, and loosely coupled in novel ways[1]. Service composition, i.e., the ability to generate new, more useful services from existing ones, is an active field of research in the SOC area and has been actively investigated for over two decades.
Particularly interesting in this context is the so-called Roman Model[2−4] where services are conversational, i.e., have an internal state and are procedurally described as finite transition systems (TS), where at each state the service offers a certain set of actions, and each action changes the state of the service in some way. The designer is interested in generating a new service, called target, which is described as the other service; however, it is virtual in the sense that no code is associated with its actions. So, for executing the target, one has to delegate each of its actions to some of the available services by suitably orchestrating the services, considering the current state of the target and the current states of the available services. Service composition amounts to synthesizing a controller that can suitably orchestrate the executions of the available services to guarantee that the target actions are always delegated to some service that can actually execute them in its current state.
Recently, a renewed interest in service composition à la Roman Model has emerged from its potential applications in smart manufacturing. In particular, through digital twins technology, manufacturing devices can export their behaviour as transition systems, and hence be orchestrated in very much the same way as services did back in the early 2000s[5−7].
These technological trends align with the vision of smart manufacturing, which advocates the need for flexible, modular, and interoperable system architectures. Modern manufacturing systems often consist of heterogeneous components, ranging from robotic workstations to cyber-physical subsystems, that communicate through standardized APIs. In such settings, each component can be naturally abstracted as a service. Consequently, adopting the Service-Oriented Architectures (SOAs) approach enables the dynamic composition and coordination of such services, leveraging their exposed behaviors while maintaining loose coupling and scalability.
In this context, service composition à la Roman Model provides a useful abstraction for orchestrating device behavior toward achieving temporally extended goals. By treating each device or software module as a service with internal dynamics, and expressing high-level objectives via Linear Temporal Logic on finite traces (ʟᴛʟf), our framework bridges declarative specification with executable orchestration.
Interestingly, these new applications are also pointing out several variations that are not typically considered in earlier literature on services. First, they advocate for considering a stochastic behaviour of services, such as those studied in Yadav et al.[8] and Brafman et al.[9]. Unlike the classical model, in which the target specification can either be satisfied or not with no middle ground, in the stochastic setting, it is possible to define a notion of 'approximate solution' in case an exact one does not exist. Second, the notion of goal-oriented target specification is increasingly championed [5,6,10]. That is, instead of having the target specified as a transition system, it is specified as a (possibly temporally extended) goal that the composition has to fulfill. Of particular interest are specifications in ʟᴛʟf [11], which are at the base of declarative process specification in Business Process Management (BPM) through the so-called declare paradigm[12−14]. Third, apart from satisfying the target, it is of interest to also minimize the cost coming from the service utilization[15−17]. This concern, together with the satisfaction of the target, calls for resorting to Multi-Objective Optimization for computing a solution.
A first attempt to do so may resort to Multi-Objective MDPs (MOMDPs)[18]. One common solution is to reduce the multi-objective reward/cost optimization to a single reward optimization via a linear weighting of different sources of rewards/costs. However, this means that the two objectives, namely the maximization of target rewards and the minimization of cost uses, are blurred into one scalar value, which hides precious information from the agent. Instead, the maximization of the target objective has the highest priority. Among those strategies that maximize the first objective, we aim to find those strategies that achieve the minimum utilization cost. In the literature of multi-objective optimization, the setting in which there is a strict preference order among objectives is called lexicographic multi-objective optimization[19−22]. It is known that, in general, single Markovian rewards cannot capture certain multi-objective tasks, such as ones with lexicographic preferences[23]; hence, such problems cannot be easily reduced to standard techniques on MDPs[24].
Among related works, one of the earliest attempts at combining stochastic planning models with service composition is a study by Gao et al.[25]. There are works based on Markov-HTN Planning[26], multi-objective optimization[27,28], and lexicographic optimization[29], helpful to model the stochastic behavior as well as complex QoS preferences. However, in all cases, either there are no stateful services, no high-level declarative specification of the desired solution, or no strict preference among objectives.
1.1. Contributions
-
In this paper, we address the three above requirements and study goal-oriented stochastic service composition, where, as goals, we adopt arbitrary ʟᴛʟf specifications, under process-traces semantics, where only a single action is executed at a time, as commonly done in reasoning about business processes in the declare framework[12]. Specifically, we are given a goal specification, and we want to synthesize an orchestrator that, on the one hand, proactively chooses actions to form a sequence that satisfies the goal and, on the other hand, delegates each action to an available service in such a way that at the end of the sequence, all services are in their final states. The key contribution of this work extends the findings of De Giacomo et al.[30], including both reachability and safety tasks, introducing a novel reduction technique for safety specification. The composition problem consists of maximizing the satisfaction probability of the ʟᴛʟf objective, and conditioned on this, minimizing the expected cost of utilization of the services.
We consider two variants of the ʟᴛʟf stochastic service composition problem. In the first variant of the problem, as the first objective, we aim to maximize the probability of satisfying at least once an ʟᴛʟf formula
$ \varphi $ $ t_{<k} $ $ t $ $ t_{<k} \models \varphi $ $ \varphi $ $ t_{<k} $ $ t $ $ t_{<k} \models \varphi $ Observe that our reachability and safety ʟᴛʟf properties are conceptually similar to those formalized in studies by Aminof et al.[33,34], where they use
$ \exists \varphi $ $ \forall \varphi $ $ \varphi $ The solution technique for both variants of the composition problem relies on solving a bi-objective lexicographic optimization[35] over a special MDP, allowing for minimizing the services' utilization costs while guaranteeing maximum probability of goal satisfaction. We point out that although this paper has mainly a foundational nature, it also has a significant applicative interest since it gives the foundations and solution techniques of goal-oriented compositions, which are indeed envisioned in the current literature on smart manufacturing where the notion of goal-oriented target specification is increasingly championed[5−7,10].
This paper presents an approach for stochastic service composition to find orchestrators that maximize the probability of satisfying the reachability and safety ʟᴛʟf tasks and, among such orchestrators, find those who also minimize a cost utilization function. We extended our previous work[30] by (i) generalizing the framework so as to encompass both variants of stochastic service composition, one for reachability and the other for safety ʟᴛʟf tasks; (ii) including a new section regarding the composition under ʟᴛʟf safety tasks; (iii) discussed in more detail a case study as a conceptual validation of our framework.
1.2. Outline
-
The rest of the paper is structured as follows. Section 2 explains the theoretical concepts on which the paper is based. Section 3 introduces the service composition framework in stochastic settings. Section 4 studies the stochastic composition problem in the case of the reachability task and provides a solution by reducing the problem to a bi-objective lexicographic optimization on MDPs[35]. Section 5 studies the stochastic composition problem in the case of a safety task and provides reduction to bi-objective lexicographic optimization on MDPs[35]; the reduction is analogous to the reachability case, but with several technical differences that require a deeper analysis. Section 6 shows the conceptual validation of the formal framework to an industrial case study of an electric motor assembly process, describing in detail the manufacturing goal and the manufacturing actors. Finally, Section 7 concludes the paper with final remarks and future work.
-
ʟᴛʟf is a variant of Linear Temporal Logic (ʟᴛʟ) interpreted over finite traces, instead of infinite ones[11]. Given a set
$ {\cal{P}} $ $ \varphi $ $ \varphi :: = {tt} \mid p \mid \lnot \varphi \mid \varphi \wedge \varphi \mid \bigcirc\varphi \mid \varphi \;{\cal{U}}\; \varphi $ where
$ {tt} $ $ p $ $ {\cal{P}} $ $ \bigcirc$ $ \;{\cal{U}}\; $ $ \Diamond \varphi \equiv true \;{\cal{U}}\; \varphi $ $ \square \varphi \equiv \lnot \Diamond \lnot \varphi $ $ {\LARGE \bullet } \varphi \equiv \lnot {\bigcirc} \lnot\varphi $ $ \lnot {\bigcirc} \varphi $ $ {\bigcirc} \lnot \varphi $ $ \varphi_1 \;{\cal{W}}\; \varphi_2 \equiv (\varphi_1 \;{\cal{U}}\; \varphi_2 \lor \Box \varphi_1) $ $ \varphi_1 $ $ \varphi_2 $ $ {\cal{P}} $ $ a = a_0 \dots a_{l-1} $ $ a_i\in {\cal{P}} $ $ l $ $ \epsilon $ Given a finite (possibly empty) trace
$ a $ $ \varphi $ $ a $ $ i\in\{0, \dots, l-1\} $ $ a,i\models\varphi $ ●
$ a,i\models {tt} $ ●
$ a,i \models p $ $ a_i = p $ ●
$ a,i\models\lnot\varphi $ $ a, i \not\models \varphi $ ●
$ a, i \models \varphi_1 \wedge\varphi_2 $ $ a, i \models \varphi_1 $ $ a, i \models \varphi_2 $ ●
$ a, i \models {\bigcirc} \varphi $ $ i<l-1 $ $ a, i + 1 \models \varphi $ ●
$ a, i \models \varphi_1 \;{\cal{U}}\; \varphi_2 $ $ j $ $ i \ge j \lt l $ $ a, j \models \varphi_2 $ $ k $ $ i \le k \lt j $ $ a, k \models \varphi_1 $ Whenever
$ a,0\models\varphi $ $ a $ $ \varphi $ $ a $ $ \varphi $ $ a\models\varphi $ $ a,0\models\varphi $ A deterministic finite automaton (dfa) is a tuple
$ {\cal{A}} = \langle {\cal{P}}, Q, q_0, F, \delta\rangle $ $ {\cal{P}} $ $ Q $ $ q_0 $ $ F\subseteq Q $ $ \delta:Q\times {\cal{P}} \to Q $ $ \varphi $ $ a $ $ {\rm{DFA}}$ $ {\cal{A}} $ $ q_0,\dots,q_l $ $ Q $ $ q_{i+1}\in\delta(q_i,a_i) $ $ i = 0,\dots,l-1 $ $ q_l\in F $ $ {\cal{L}}( {\cal{A}}) $ $ {\cal{A}} $ ${\rm{LTL}} _f $ $ {\cal{A}}_\varphi $ 2.2. Markov Decision Process (MDP)
-
A Markov Decision Process (MDP) is a tuple M = (S, A, P, s0), where: (i) S is a finite set of states, (ii) s0 is the initial state, (iii) A is a finite set of actions, and (iv)
$ P : (S \times A) \to \Delta(S) $ $ d $ $ \rho \in (S \times A)^\omega $ $ \rho = s_0a_1s_1a_2 \dots $ $ s_i \in S $ $ a_{i+1} \in A $ $ s_{i+1}\in {\text{Supp}}(P(s_i,a_{i+1})) $ $ i \in {\mathbb{N}} $ $ \rho \in (S \times A)^* \times S $ $ \rho = s_0a_1s_1a_2 \dots a_{m}s_m $ $ \rho $ $ j $ $ i \leq j $ $ \rho[i: j] $ $ s_ia_{i+1}s_{i+1}a_{i+2} \dots a_{j}s_j $ $ {\text{last}}(\rho) = s_m $ $ \rho $ $ {\text{Paths}}_ {\cal{M}}^\omega = (S \times A)^\omega $ $ {\text{Paths}}_ {\cal{M}} = (S \times A)^* \times S $ $ \pi : {\text{Paths}}_ {\cal{M}} \rightarrow A $ $ \rho \in {\text{Paths}}_ {\cal{M}} $ $ a\in A $ $ {\text{Paths}}_{ {\cal{M}}_\pi} $ $ {\cal{M}} $ $ \pi $ $ \rho = s_0a_1 \dots a_ms_m $ $ \rho $ $ {\text{Paths}}_{ {\cal{M}}}^\omega(\rho) $ $ \rho $ $\sigma$ $ {\cal{M}} $ $ \pi $ $\sigma$ $ {\text{Paths}}_{ {\cal{M}}_\pi}^\omega(\rho)$ $\rho \in {\text{Paths}}_{ {\cal{M}}_\pi}$ $s$ $S$ $ {\mathbb{P}}_{ {\cal{M}}_\pi,s}( {\text{Paths}}^\omega_{ {\cal{M}}_\pi}(s_0 a_1 s_1 \dots a_m s_m)) = \prod_{k = 0}^{m-1} P(s_{k+1}|s_k,a_{k+1}) $ $ s_0 = s $ $ k $ $ a_{k+1} = \pi(\rho[0: k]) $ $ 0 $ $ {\mathbb{P}}_{ {\cal{M}}_\pi,s}( {\text{Paths}}^\omega_{ {\cal{M}}_\pi}(s)) = 1$ $ {\mathbb{P}}_{ {\cal{M}}_\pi,s}( {\text{Paths}}^\omega_{ {\cal{M}}_\pi}(s')) = 0$ $s'\neq s$ $ {\mathbb{P}}_{ {\cal{M}}_\pi,s}$ $\sigma$ $ {\cal{R}} \subseteq {\text{Paths}}_{ {\cal{M}}_\pi}$ $ {\mathbb{P}}_{ {\cal{M}}_\pi,s}(\bigcup_{\rho \in {\cal{R}}} {\text{Paths}}^\omega_{ {\cal{M}}_\pi}(\rho)) = \sum_{\rho \in {\cal{R}}} {\mathbb{P}}_{ {\cal{M}}_\pi,s}( {\text{Paths}}^\omega_{ {\cal{M}}_\pi}(\rho)) $ $ {{\mathbb{E}}}_{ {\cal{M}}_{\pi},s}[X] $ $ X $ $ {\mathbb{P}}_{ {\cal{M}}_{\pi},s} $ -
In this section, we present our service composition framework in stochastic settings.
A (stochastic) service is a tuple
$ {\cal{S}} = \langle \Sigma, A, \sigma_{0}, F, P, C\rangle $ $ \Sigma $ $ A $ $ \sigma_0\in \Sigma $ $ F\subseteq \Sigma $ $ P: \Sigma \times A \to \Delta(\Sigma) $ $ \sigma $ $ a $ $ C: \Sigma \times A \to {\mathbb{R}}^+ $ $ \sigma\in\Sigma $ $ a\in A $ $ | {\text{Supp}}(\sigma, a)|>0 $ $ {\cal{C}} = \{ {\cal{S}}_1,\dots, {\cal{S}}_n \} $ $ {\cal{C}} $ $ t = (\sigma_{10}\dots\sigma_{n0}),(a_1,o_1),\dots $ $ \sigma_{i0} $ $ {\cal{S}}_i $ $ k\ge 1 $ $ \sigma_{ik} \in \Sigma_i $ $ i \in \{1,\dots,n\} $ $ o_k \in \{1,\dots, n\} $ $ k $ $ a_k \in A $ $ i $ $ \sigma_{ik}\in {\text{Supp}}(P_i(\sigma_{i,k-1},a_{ik})) $ $ o_k = i $ $ \sigma_{ik} = \sigma_{i,k-1} $ $ {\cal{C}} $ $ {\cal{C}} $ $ h $ $ |h| = m $ $ h $ $ (\sigma_{1m}\dots\sigma_{nm}) $ $ {\text{last}}(h) $ $ t $ $ {\text{states}}(t) $ $ t $ $ {\text{states}}(t) = (\sigma_{10}\dots\sigma_{n0}), $ $ (\sigma_{11}\dots\sigma_{n1}),\cdots $ $ t $ $ {\text{choices}}(t) $ $ t $ $ {\text{choices}}(t) = (a_1,o_1),(a_m,o_m), \dots $ $ {\cal{C}} $ $ t $ $ {\text{actions}}(t) $ $ {\text{choices}}(t) $ $ A $ $ {\text{states}} $ $ {\text{choices}} $ $ {\text{actions}} $ $ h $ $ {\text{choices}}(h) $ $ {\text{actions}}(h) $ $ h = (\sigma_{10}\dots\sigma_{n0}) $ An orchestrator is a function
$ {\gamma}: (\Sigma_1\times\cdots\times\Sigma_n)^* \to A\times \{1\dots n\} $ $ (\sigma_{10}\dots\sigma_{n0})\dots(\sigma_{1m}\dots\sigma_{nm}) $ $ a \in A $ $ t $ $ {\text{prefixes}}(t) $ $ t $ $ t $ $ {\gamma} $ $ {\cal{C}} $ $ k\ge 0 $ $ (a_{k+1},o_{k+1}) = {\gamma}((\sigma_{10}\dots\sigma_{n0})\dots(\sigma_{1k}\dots\sigma_{nk})) $ $ {\cal{T}}_{ {\gamma}, {\cal{C}}} $ $ h\in {\text{prefixes}}(t) $ $ t\in {\cal{T}}_{ {\gamma}, {\cal{C}}} $ $ h $ $ {\gamma} $ $ {\cal{C}} $ $ {\cal{H}}_{ {\gamma}, {\cal{C}}} $ $ {\gamma} $ $ {\cal{C}} $ $ h $ $ {\gamma} $ $ {\cal{C}} $ $ {\cal{T}}_{ {\gamma}, {\cal{C}}}(h) $ $ t\in {\cal{T}}_{ {\gamma}, {\cal{C}}} $ $ h\in {\text{prefixes}}(t) $ $ \sigma $ $ {\gamma} $ $ {\cal{C}} $ $ \sigma $ $ {\cal{T}}_{ {\gamma}, {\cal{C}}}(h) $ $ h $ $ {\mathbb{P}}_{ {\gamma}, {\cal{C}}}(h) = \prod\limits_{k = 1}^{|h|} P_{o_k}(\sigma_{o_k,k} \mid \sigma_{o_k,k-1}, a_{k}) $ (1) where
$ a_k = {\gamma}((\sigma_{10}\dots\sigma_{n0}),\dots(\sigma_{1k}\dots\sigma_{nk})) $ $ {\mathbb{P}}_{ {\gamma}, {\cal{C}}}( {\cal{T}}_{ {\gamma}, {\cal{C}}}(\langle(\sigma_{10}\dots\sigma_{n0})\rangle)) = 1 $ Example 1 This example is inspired by the 'garden bots system' scenario[8]. In this environment, the garden bots can:
$ {clean} $ $ {water} $ $ {pluck} $ $ {\cal{B}}_1, {\cal{B}}_2, {\cal{B}}_3 $ $ \langle {action}, {prob}, {reward}\rangle $ 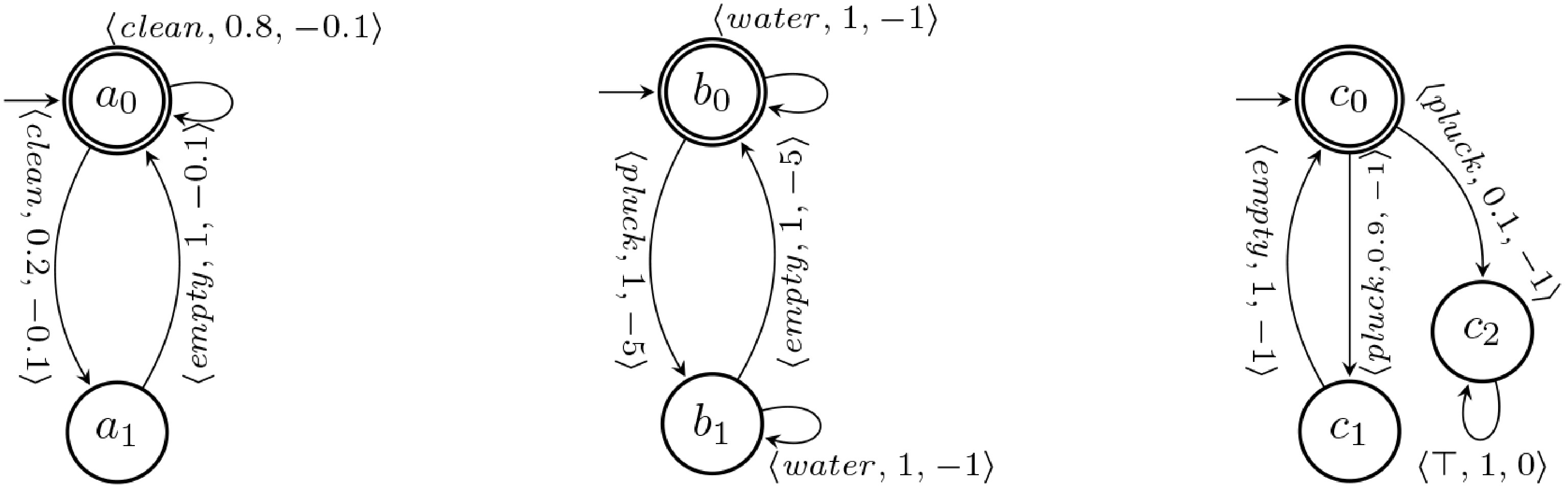
Figure 1.
The garden bot systems and the DFA of the ʟᴛʟf reachability task.
We consider an orchestrator
$ \gamma $ $ {\cal{B}}_1 $ $ a_0 $ $ {clean} $ $ a_1 $ $ {empty} $ $ h_1 = (a_0,b_0,c_0),({clean}, {\cal{B}}_1), (a_0,b_0,c_0) $ $ {\gamma} $ $ {\mathbb{P}}_{ {\gamma}, {\cal{C}}}(h_1) = 0.8 $ $ a_0\xrightarrow[]{{clean}}a_0 $ $ h_1 = (a_0,b_0,c_0),({clean}, {\cal{B}}_1), (a_1,b_0,c_0) $ $ {\mathbb{P}}_{ {\gamma}, {\cal{C}}}(h_1) = 0.2 $ $ a_0\xrightarrow[]{{clean}}a_1 $ -
In this section, we present our service composition framework in stochastic settings where the goal is to maximize the probability of satisfying the ʟᴛʟf reachability task of
$ \varphi $ $ \varphi $ Formally, we consider a ʟᴛʟf formula
$ \varphi $ $ A $ $ n $ $ {\cal{C}} = \{ {\cal{S}}_1, \dots, {\cal{S}}_n\} $ $ A_i\subseteq A $ $ h $ $ {\cal{C}} $ $ \varphi $ $ {\text{successful}}_{ {\cal{C}},\varphi}(h) $ $ h'\in {\text{prefixes}}(h) $ $ {\text{actions}}(h')\models\varphi $ $ \sigma_i \in {\text{last}}( {\text{states}}(h')) $ $ \sigma_i\in F_i $ $ t\in {\cal{T}}_{ {\gamma}, {\cal{C}}} $ $ h\in {\text{prefixes}}(t) $ $ {\text{successful}}_{ {\cal{C}},\varphi}(h) $ $ \varphi $ $ t $ $ \varphi $ $ {\gamma} $ ${\rm{LTL}} _f $ $ \varphi $ $ {\cal{C}} $ $ t\in {\cal{T}}_{ {\gamma}, {\cal{C}}} $ $ t $ $ \varphi $ $ {\cal{C}} $ $ \varphi $ $ {\text{successful}}_{ {\cal{C}},\varphi} $ $ {\text{successful}} $ Example 2 Continuing example 1, we consider the following sequential task:
$ {clean} $ $ {water} $ $ {pluck} $ $ {clean} $ $ {water} $ $ {pluck} $ ${\rm{LTL}} _f $ $ \varphi = {clean} \wedge {\bigcirc}({clean} \;{\cal{U}}\;(({water}\land {\bigcirc}{pluck})\lor({pluck}\land {\bigcirc}{water}))) $ A successful execution is
$ \begin{array}{l} h_1 = \langle (a_0,b_0,c_0), ({clean}, {\cal{B}}_1), (a_0, b_0, c_0), ({water}, {\cal{B}}_2), (a_0, b_0, c_0),\\ \;\;\;\;\;\;\;\; ({pluck}, {\cal{B}}_2), (a_0, b_1, c_0),({empty}, {\cal{B}}_2), (a_0, b_0, c_0)\rangle \end{array} $ Note that, before the action
$ ''{empty}'' $ $ \varphi $ $ {\cal{B}}_2 $ $ ''{empty}'' $ $ {\cal{B}}_2 $ $ \begin{array}{l} h_2 = \langle (a_0,b_0,c_0), ({clean}, {\cal{B}}_1), (a_0, b_0, c_0), ({pluck}, {\cal{B}}_3), (a_0, b_0, c_1), \\ \;\;\;\;\;\;\;\;\;({empty}, {\cal{B}}_3), (a_0, b_0, c_0), ({water}, {\cal{B}}_2), (a_0, b_0, c_0)\rangle \end{array} $ On the other hand, any extension of the execution
$ h_3 = \langle(a_0,b_0,c_0), ({clean}, {\cal{B}}_1), (a_0, b_0, c_0), ({pluck}, {\cal{B}}_3), (a_0, b_0, c_2)\rangle $ will not be successful since service
$ {\cal{B}}_3 $ $ c_2 $ The satisfaction probability of the reachability task
$ \varphi $ $ {\gamma} $ $ {\cal{C}} $ $ {\cal{P}}_{ {\cal{C}},\varphi}^ {\text{reach}}( {\gamma}) = {\mathbb{P}}_{ {\gamma}, {\cal{C}}}\bigg(\big\{t \in {\cal{T}}_{ {\gamma}, {\cal{C}}} \,\big\vert\, {\text{successful}}(t)\big\}\bigg) $ (2) Intuitively,
$ {\cal{P}}_{ {\cal{C}},\varphi}^ {\text{reach}}( {\gamma}) $ $ {\mathbb{P}}_{ {\gamma}, {\cal{C}}} $ $ {\gamma} $ $ {\cal{C}} $ Moreover, we define the (conditioned) expected utilization cost of services as the expected cost an orchestrator incurs in its successful executions, i.e.:
$ {\cal{J}}^{ {{\text{cost}}}}_{ {\cal{C}},\varphi} ( {\gamma}) = {\mathbb{E}}_{h\sim {\mathbb{P}}_{ {\gamma}, {\cal{C}}}}\Bigg[ \sum\limits_{k = 1}^{|h|} C_{o_k}(\sigma_{o_k,k-1},a_{k}) \bigg\vert\ {\text{successful}}(h) \Bigg] $ (3) Let
$ \Gamma( {\cal{C}}) $ $ {\cal{C}} $ $ f: \Gamma( {\cal{C}}) \to {\mathbb{R}} $ $ {\gamma}\in\Gamma( {\cal{C}}) $ $ f $ $ f( {\gamma}) = \sup_{\tau\in \Gamma( {\cal{C}})} f(\tau) $ $ \Gamma_f $ $ f $ Finally, we define our optimization problem. We want to compute an orchestrator
$ {\gamma} $ $ {\gamma}\in\Gamma_{ {\cal{P}}_{ {\cal{C}},\varphi}^ {\text{reach}}} \text{ and } {\cal{J}}^{ {{\text{cost}}}}_{ {\cal{C}},\varphi}( {\gamma}) = \inf\limits_{ {\gamma}'\in\Gamma_{ {\cal{P}}_{ {\cal{C}},\varphi}^ {\text{reach}}}} {\cal{J}}^{ {{\text{cost}}}}_{ {\cal{C}},\varphi}( {\gamma}') $ (4) Intuitively, we fix a lexicographic order on the objective functions
$ {\cal{P}}_{ {\cal{C}},\varphi}^ {\text{reach}} $ $ {\cal{J}}^{ {{\text{cost}}}}_{ {\cal{C}},\varphi} $ First, let
$ {\cal{H}}^{\varphi}_{ {\gamma}, {\cal{C}}} $ $ h $ $ {\gamma} $ $ {\cal{C}} $ $ \sigma_{10}\dots\sigma_{n0} $ $ {\text{successful}}(h) $ $ h'\in {\text{prefixes}}(h) $ $ {\text{successful}}(h') $ $\begin{split} {\cal{H}}^{\varphi}_{ {\gamma}, {\cal{C}}} =\;& \{ h\in {\cal{H}}_{ {\gamma}, {\cal{C}}}: {\text{successful}}(h) \wedge \not\exists h'\in {\text{prefixes}}(h) \text{ s.t. } h'\\\neq\;& h \wedge {\text{successful}}(h) \}\end{split} $ (5) Intuitively, such a set only contains the finite executions
$ h $ $ \varphi $ $ {\cal{H}}^\varphi_{ {\gamma}, {\cal{C}}} $ $ h\in {\cal{H}}^\varphi_{ {\gamma}, {\cal{C}}} $ $ {\text{successful}}(h) $ Lemma 1 The following equality holds:
$ \big\{t \in {\cal{T}}_{ {\gamma}, {\cal{C}}} \,\big\vert\, {\text{successful}}(t)\big\} = \bigcup\limits_{h\in {\cal{H}}^{\varphi}_{ {\gamma}, {\cal{C}}}} {\cal{T}}_{ {\gamma}, {\cal{C}}}(h) $ Proof We prove the two set inclusions (i)
$ \subseteq $ $ \supseteq $ (i) if
$ t\in {\cal{T}}_{ {\gamma}, {\cal{C}}} $ $ {\text{successful}}(t) $ $ h\in {\text{prefixes}}(t) $ $ h $ $ h' $ $ h" $ $ h' $ $ {\cal{H}}^{\varphi}_{ {\gamma}, {\cal{C}}} $ $ h'\in {\cal{H}}^{\varphi}_{ {\gamma}, {\cal{C}}} $ $ t $ $ {\gamma} $ $ {\cal{C}} $ $ h' $ $ {\cal{T}}_{ {\gamma}, {\cal{C}}} $ $ t\in {\cal{T}}_{ {\gamma}, {\cal{C}}}(h') $ (ii) let
$ t\in\bigcup_{h\in {\cal{H}}^{\varphi}_{ {\gamma}, {\cal{C}}}} {\cal{T}}_{ {\gamma}, {\cal{C}}}(h) $ $ h\in {\cal{H}}^{\varphi}_{ {\gamma}, {\cal{C}}} $ $ t\in {\cal{H}}^{\varphi}_{ {\gamma}, {\cal{C}}} $ $ {\cal{H}}^{\varphi}_{ {\gamma}, {\cal{C}}} $ $ {\text{successful}}(h) $ $ {\text{successful}} $ $ h\in {\text{prefixes}}(t) $ $ {\text{successful}}(t) $ $ {\cal{T}}_{ {\gamma}, {\cal{C}}}(h)\subseteq {\cal{T}}_{ {\gamma}, {\cal{C}}} $ □ It is crucial to observe that since by definition of
$ {\cal{H}}^{\varphi}_{ {\gamma}, {\cal{C}}} $ $ h',h"\in {\cal{H}}^{\varphi}_{ {\gamma}, {\cal{C}}}(h) $ $ h'\in {\text{prefixes}}(h") $ $ {\cal{T}}_{ {\gamma}, {\cal{C}}}(h) $ $ h\in {\cal{H}}^{\varphi}_{ {\gamma}, {\cal{C}}} $ $ {\cal{P}}_{ {\cal{C}},\varphi}^ {\text{reach}}( {\gamma}) $ Lemma 2 If
$ {\gamma} $ $ \varphi $ $ {\cal{C}} $ $ \bigcup_{h\in {\cal{H}}^{\varphi}_{ {\gamma}, {\cal{C}}}} {\cal{T}}_{ {\gamma}, {\cal{C}}}(h) = {\cal{T}}_{ {\gamma}, {\cal{C}}}(\langle(\sigma_{10}\dots\sigma_{n0})\rangle) $ Proof We prove (i)
$ \bigcup_{h\in {\cal{H}}^{\varphi}_{ {\gamma}, {\cal{C}}}} {\cal{T}}_{ {\gamma}, {\cal{C}}}(h) \subseteq {\cal{T}}_{ {\gamma}, {\cal{C}}}(\langle(\sigma_{10}\dots\sigma_{n0})\rangle) $ $ \bigcup_{h\in {\cal{H}}^{\varphi}_{ {\gamma}, {\cal{C}}}} {\cal{T}}_{ {\gamma}, {\cal{C}}}(h) \supseteq {\cal{T}}_{ {\gamma}, {\cal{C}}}(\langle(\sigma_{10}\dots\sigma_{n0})\rangle) $ $ \sigma_{10}\dots\sigma_{n0} $ $ t\in {\cal{T}}_{ {\gamma}, {\cal{C}}}(\langle(\sigma_{10}\dots\sigma_{n0})\rangle) $ $ h'\in {\text{prefixes}}(h) $ $ h" $ $ h $ $ h"\in {\cal{H}}^{\varphi}_{ {\gamma}, {\cal{C}}} $ $ t\in {\cal{T}}_{ {\gamma}, {\cal{C}}}(h") $ $ t\in\bigcup_{h"\in {\cal{H}}^{\varphi}_{ {\gamma}, {\cal{C}}}} {\cal{T}}_{ {\gamma}, {\cal{C}}}(h") $ □ Theorem 1 Let
$ {\cal{C}} $ $ \varphi $ $ {\gamma} $ $ \varphi $ $ {\cal{C}} $ $ {\cal{P}}_{ {\cal{C}},\varphi}^ {\text{reach}}( {\gamma}) = 1 $ Proof (
$ \Rightarrow $ $ {\gamma} $ $ \varphi $ $ t\in {\cal{T}}_{ {\gamma}, {\cal{C}}} $ $ t\in \bigcup_{h\in {\cal{H}}^{\varphi}_{ {\gamma}, {\cal{C}}}} {\cal{T}}_{ {\gamma}, {\cal{C}}}(h) $ $ {\cal{T}}_{ {\gamma}, {\cal{C}}}(\langle(\sigma_{10}\dots \sigma_{n0})\rangle) $ $ {\text{Supp}}( {\mathbb{P}}_{ {\gamma}, {\cal{C}}}) \subseteq $ $ {\cal{T}}_{ {\gamma}, {\cal{C}}}(\langle(\sigma_{10}\dots\sigma_{n0})\rangle) $ $ {\cal{P}}_{ {\cal{C}},\varphi}^ {\text{reach}}( {\gamma}) = {\mathbb{P}}_{ {\gamma}, {\cal{C}}}(\bigcup_{h\in {\cal{H}}^{\varphi}_{ {\gamma}, {\cal{C}}}} {\cal{T}}_{ {\gamma}, {\cal{C}}}(h)) = {\mathbb{P}}_{ {\gamma}, {\cal{C}}}( {\cal{T}}_{ {\gamma}, {\cal{C}}}(\langle(\sigma_{10}\dots \sigma_{n0})\rangle)) = 1 $ (
$ \Leftarrow $ $ {\gamma} $ $ {\cal{P}}_{ {\cal{C}},\varphi}^ {\text{reach}}( {\gamma}) = 1 $ $ t\in {\text{Supp}}( {\mathbb{P}}_{ {\gamma}, {\cal{C}}}) \subseteq $ ${\cal{T}}_{ {\gamma}, {\cal{C}}}(\langle(\sigma_{10}\dots\sigma_{n0})\rangle) $ $ \gamma $ $ h\in {\text{prefixes}}(t) $ $ h\in {\cal{H}}^{\varphi}_{ {\gamma}, {\cal{C}}} $ $ t\in {\cal{T}}_{ {\gamma}, {\cal{C}}}(h) $ □ Theorem 2 Assume the reachability task
$ \varphi $ $ {\gamma} $ $ \varphi $ Proof Since by assumption the reachability task
$ \varphi $ $ {\gamma}' $ $ {\cal{P}}_{ {\cal{C}},\varphi}^ {\text{reach}}( {\gamma}') $ $ 1 $ $ {\gamma} \in \Gamma_{ {\cal{P}}_{ {\cal{C}},\varphi}^ {\text{reach}}} $ $ {\cal{P}}_{ {\cal{C}},\varphi}^ {\text{reach}}( {\gamma}) = 1 $ $ {\gamma} $ $ \varphi $ □ Finally, we formally state the stochastic version of our problem:
Problem 1 (Stochastic Composition for ʟᴛʟf Reachability Tasks). Given the pair
$ ( {\cal{C}}, \varphi) $ $ \varphi $ $ A $ $ {\cal{C}} $ $ n $ $ {\cal{C}} = \{ {\cal{S}}_1,\dots, {\cal{S}}_n\} $ Interestingly, Theorems 1 and 2 show that one can find an orchestrator even in a non-stochastic setting by considering arbitrary services' probability distributions for
$ P_i(\sigma_i,a) $ $ \sigma_i $ $ a $ $ \delta_i $ $ \max_ {\gamma} {\cal{P}}_{ {\cal{C}},\varphi}^ {\text{reach}}( {\gamma}) = 1 $ Example 3 Continuing example 2, we aim to find a composition of the available bots
$ {\cal{B}}_1, {\cal{B}}_2, {\cal{B}}_3 $ $ \varphi $ $ {clean} $ $ {\cal{B}}_1 $ $ {pluck} $ $ {\cal{B}}_2 $ $ {\cal{B}}_3 $ $ {\cal{B}}_3 $ $ {\cal{B}}_2 $ $ {\cal{B}}_3 $ $ 0.1 $ $ c_2 $ $ {\cal{B}}_3 $ 4.1. Solution technique
-
The solution technique is based on finding an optimal policy for a bi-objective lexicographic optimization on a specifically built MDP. In particular, we consider a variant of the framework introduced in study by Busatto-Gaston et al.[35]: while as the second objective they considered the expected number of steps to a target, here we consider the expected cost. Given an instance of the reachability composition problem
$ ( {\cal{C}},\varphi) $ ${\rm{LTL}} _f $ $ {\cal{A}}_\varphi $ $ {\cal{A}}_\varphi $ $ {\cal{A}}_{\varphi} $ $ {\cal{C}} $ $ {\cal{M}}' $ $ \pi $ $ {\cal{M}}' $ $ {\gamma} $ $ \pi $ Step 1. The dfa of an ʟᴛʟf formula can be computed by exploiting a well-known correspondence between ʟᴛʟf formulas and automata on finite words[11]. That is, we can compute a dfa
$ {\cal{A}}_\varphi = (A, Q, q_0, F, \delta) $ $ \varphi $ Step 2. Next, we define the Composition MDP
$ {\cal{M}}' = (S', A', P', s'_0) $ ●
$ S' = Q\times\Sigma_1\times\cdots\times \Sigma_n $ ●
$ A' = A\times \{1\dots n\} $ ●
$ s'_0 = (q_0,\sigma_{10}\dots\sigma_{n0}) $ ●
$ P'(q',\sigma'_1\dots\sigma'_i\dots\sigma'_n|q,\sigma_1\dots \sigma_i\dots \sigma_n, (a,i)) = P_i(\sigma'_i|\sigma_i, a) $ $ \delta(q,a) = q' $ $ \sigma'_{j} = \sigma_j $ $ j\neq i $ $ 0 $ Moreover, let the composition cost function
$ C': S'\times A' \to {\mathbb{R}}^+ $ $ C'((q,\sigma_1\dots\sigma_i\dots\sigma_n), (a,i)) = C_i(\sigma_i, a) $ We are interested in computing optimal policies for
$ {\cal{M}}' $ $ T $ $ T = \{(q,\sigma_1,\dots,\sigma_n) \mid (q,\sigma_1,\dots,\sigma_n)\in S' \wedge q\in F \wedge \forall i = 1,\dots,n\,: \sigma_i \in F_i\} $ Intuitively,
$ T\subseteq S' $ $ {\cal{M}}' $ $ {\cal{A}} $ $ q $ $ {\cal{S}}_i $ $ \sigma_i $ $ {\cal{S}}_i $ $ {\cal{M}}' $ $ T $ $ s\in S' $ $ \pi $ $ {\cal{M}}' $ $ {\mathbb{P}}_{ {\cal{M}}'_\pi,s}(\lozenge T) $ $ \Pi_{ {\cal{M}}',s}(\lozenge T) $ $ T $ $ \arg\max_\pi {\mathbb{P}}_{ {\cal{M}}'_\pi,s}(\lozenge T) $ $ \rho $ $ T $ $ {\text{cost}}_{T}(\rho) = \sum_{k = 0}^{i} C'(s'_k, a'_k) $ $ \rho[i]\in T $ $ j \lt i $ $ \rho[j] \not\in T $ $ {\cal{M}}' $ $ \pi $ $ {\mathbb{E}}_{\rho\sim {\cal{M}}'_{\pi'},s'_0}[ {\text{cost}}_{T}(\rho) | \lozenge T] $ $ \Pi_{ {\cal{M}}',s'_0}(\lozenge T) $ $ {\mathbb{P}}_{ {\cal{M}}'_\pi,s'_0}(\lozenge T) $ $ \pi\in \Pi_{ {\cal{M}}',s_0}(\lozenge T) \text{ and } \pi\in\arg\min\limits_{\pi'} {\mathbb{E}}_{\rho\sim {\cal{M}}'_\pi,s'_0}\big[ {\text{cost}}_T(\rho) | \lozenge T\big] $ (6) Step 3. The solution technique we will use is based on the work[35], where the authors propose a two-stage technique to find an optimal policy for a bi-objective lexicographic function in the form of Eq. (6). First, we compute the set of policies (in the form of a set of optimal actions for each state) that maximize the probability of reaching the target states; however, this set of policies also contains the 'deferral' policies, i.e. policies that defer the actual reaching of the target states indefinitely, but in such a way that the target can still be reached with maximum probability at any moment. Then, we consider a 'pruned MDP' in which (i) only optimal action can be taken, and (ii) only states from which the target can be reached are kept. The new MDP is used to find policies that minimize the expected cost of reaching the target. By construction, the optimal policy of the pruned MDP guarantees the target is always reached since any deferral policy will incur an infinite cost. The difference between our scenario and Busatto-Gaston et al.[35] is that they consider the length of the path, rather than its cost, as the second objective function. Nevertheless, it is easy to see that their approach works if, instead of considering the expected length of successful paths, we consider their expected total costs (i.e., minimizing path length can be seen as minimizing costs with each transition having unitary cost). Note that the techniques used to find the solutions are standard: the first stage requires solving the maximal reachability probability problem[38] on the composition MDP with the accepting end components as the set of states
$ T $ Step 4. Once an optimal policy is found, we can obtain its equivalent
$ {\gamma} $ $ \rho = (q_0,\sigma_{10}\dots\sigma_{n0}), (a_1,o_1),\dots(a_m,o_m), (q_m,\sigma_{1m}\dots\sigma_{nm}),\dots $ $ {\gamma}((\sigma_{10}\dots\sigma_{n0}) \dots(\sigma_{1m}\dots\sigma_{nm})) = (a_{m+1},o_{m+1}) $ $ \pi(\rho) = (a_{m+1}, o_{m+1}) $ Now we aim to establish a relationship between optimal orchestrators according to Eq. (4), and optimal policies for
$ {\cal{M}}' $ $ \rho = (q_0,\sigma_{10}\dots\sigma_{n0}),(a_1,o_1)\dots $ $ t = {\tilde \tau}_{\varphi, {\cal{C}}}(\rho) = (\sigma_{10}\dots\sigma_{n0}),(a_1,o_1),\dots $ $ \rho $ $ t $ In the following, we are going to prove a sequence of lemmata. Lemma 3 shows that, once fixed a policy
$ \pi $ $ {\cal{M}}' $ $ \rho $ $ {\cal{M}}' $ $ \pi $ $ t\in {\cal{T}}_{ {\gamma}, {\cal{C}}} $ $ \pi $ $ {\gamma} $ $ T $ $ {\text{Paths}}_{T, {\cal{M}}'_\pi} $ $ {\cal{H}}_{ {\gamma}, {\cal{C}}}^\varphi $ Lemma 3 Let
$ \pi $ $ {\cal{M}}' $ $ {\gamma} $ $ \rho\in {\text{Paths}}_{{ {\cal{M}}'}_\pi}^\omega $ $ t $ $ t = {\tilde \tau}_{\varphi, {\cal{C}}}(\rho) $ $ \rho\in {\text{Paths}}_{ {\cal{M}}'_\pi}^\omega(\langle s'_0 \rangle) $ $ t\in {\cal{T}}_{ {\gamma}, {\cal{C}}}(\langle (\sigma_{10}\dots\sigma_{n0})\rangle) $ Proof Let the infinite path
$ \rho\in {\text{Paths}}_{ {\cal{M}}'_{\pi}}^\omega(\langle s'_0 \rangle) $ $ t = {\tilde \tau}_{\varphi, {\cal{C}}}(\rho)) $ Base case: we have the claim holds for position
$ 0 $ $ \rho[0] = (q_0,\sigma_{10}\dots\sigma_{n0}) $ $ h[0] = \sigma_{10}\dots\sigma_{n0} $ $ \langle h[0]\rangle $ $ {\gamma} $ $ s'_0\in S' $ Inductive case: assume the claim holds up to position
$ k\ge 0 $ (
$ \Rightarrow $ $ (k+1) $ $ \pi $ $ \pi(\rho[0: k]) = (a_{k+1}, o_{k+1}) $ $ \rho[k+1] = (q_{k+1}, \sigma_{1,k+1}, \dots, \sigma_{n,k+1}) $ $ h = t[0:k] $ $ {\gamma} $ $ t = {\tilde \tau}_{\varphi, {\cal{C}}}(\rho) $ $ h' = t[0:k],(a_{k+1}, o_{k+1}), (\sigma_{1,k+1},\dots,\sigma_{n,k+1}) $ $ h $ $ {\gamma} $ $ {\cal{M}}' $ $ \sigma_{i,k+1}\in \Sigma_i $ $ o_{k+1}\in\{1\dots n\} $ $ a_{k+1}\in A $ $ j = 1,\dots,n $ $ \sigma_{j,k+1}\in {\text{Supp}}(P_{j}(\sigma_{j,k},a_{k+1})) $ $ j = o_{k+1} $ $ \sigma_{j,k+1} = \sigma_{j,k} $ $ P' $ $ \rho $ $ {\cal{M}}' $ $ {\gamma} $ $ (a_{k+1}, o_{k+1}) = $ ${\gamma}( {\text{states}}(t[0: k])) $ $ h' = t[0: k], (a_{k+1},o_{k+1}),(\sigma_{1,k+1}\dots\sigma_{n,k+1}) $ $ {\gamma} $ (
$ \Leftarrow $ $ {\gamma} $ $ h = t[0:k] $ $ h' = t[0:k],(a_{k+1},o_{k+1}),(\sigma_{1,k+1}\dots\sigma_{n,k+1}) $ $ \rho[0:k+1] $ $ {\cal{M}}' $ $ \pi $ $ k $ $ (k+1) $ $ (a_{k+1}, o_{k+1}),(q_{k+1}, \sigma_{1,k+1}\dots\sigma_{n,k+1}) $ $ q_{k+1} $ $ \rho[0:k] $ $ \pi $ $ \pi(\rho[0:k]) = {\gamma}( {\text{states}}(h')) = (a_{k+1}, o_{k+1}) $ $ (q_{k+1}, \sigma_{1,k+1}\dots\sigma_{n,k+1})\in {\text{Supp}}(P') $ $ q_{k+1} = \delta(q_k,a_{k+1}) $ By induction, the claim also holds for any arbitrary position, and therefore
$ \rho\in {\text{Paths}}_{ {\cal{M}}'_\pi}^\omega(\langle s'_0 \rangle) $ $ t\in {\cal{T}}_{ {\gamma}, {\cal{C}}}(\langle (\sigma_{10}\dots\sigma_{n0})\rangle) $ □ Lemma 4 Let
$ \pi $ $ {\cal{M}}' $ $ {\gamma} $ $ \rho = s'_0a_1\dots s'_m\in {\text{Paths}}_{ {\cal{M}}'_\pi}(s'_0) $ $ {\cal{M}}' $ $ h = {\tilde \tau}_{\varphi, {\cal{C}}}(\rho) $ $ {\mathbb{P}}_{ {\cal{M}}'_\pi,s'_0}( {\text{Paths}}_{ {\cal{M}}'_\pi}^\omega(\rho)) = {\mathbb{P}}_{ {\gamma}, {\cal{C}}}( {\cal{T}}_{ {\gamma}, {\cal{C}}}(h)) $ Proof
$ {\mathbb{P}}_{ {\cal{M}}'_\pi,s'_0}( {\text{Paths}}_{ {\cal{M}}'_\pi}^\omega(\rho)) = \prod\limits_{k = 1}^{m} P'(s'_{k} \mid s'_{k-1},(a_k,o_k)) $ (7) $ = \prod\limits_{k = 1}^m P_{o_k}(\sigma_{o_k,k} \mid \sigma_{o_k,k-1}, (a_k,o_k)) $ (8) $ = {\mathbb{P}}_{ {\gamma}, {\cal{C}}}( {\cal{T}}_{ {\gamma}, {\cal{C}}}(h)) $ (9) where step 7 is by definition of the probability of a cylinder set, step 8 by definition of
$ P' $ $ {\cal{M}}' $ □ Lemma 5 Let
$ \rho = s_0a_1\dots s_m\in {\text{Paths}}_{ {\cal{M}}'_\pi} $ $ {\cal{M}}'_\pi $ $ \pi $ $ h = {\tilde \tau}_{\varphi, {\cal{C}}}(\rho) $ $ {\text{successful}}(h) $ $ k\in [0,m] $ $ s_k\in T $ Proof Let
$ k $ $ 0 $ $ m $ $ {\cal{M}}' $ $ s_k = (q_k,\sigma_{1k}\dots\sigma_{nk})\in T $ $ (a) $ $ q_k\in F $ $ (b) $ $ i = 1,\dots,n $ $ \sigma_{ik}\in F_i $ $ r = q_0,\dots,q_k $ $ {\cal{A}}_\varphi $ $ {\text{actions}}(h') = a_1,\dots a_{k} $ $ h' = h[0:k] $ $ {\text{actions}}(h')\in {\cal{L}}( {\cal{A}}_\varphi) $ $ {\cal{A}}_\varphi $ $ {\text{actions}}(h')\models \varphi $ $ h'\in {\text{prefixes}}(h) $ $ {\text{actions}}(h')\models\varphi $ $ {\text{successful}}(h) $ Conversely, assume
$ {\text{successful}}(h) $ $ h' = h[0:k] $ $ {\text{actions}}(h')\models\varphi $ $ \sigma_{ik}\in F_i $ $ i = 1,\dots,n $ $ {\cal{A}}_\varphi $ $ {\text{actions}}(h')\models\varphi $ $ {\text{actions}}(h')\in {\cal{L}}( {\cal{A}}_\varphi) $ $ r = q_0,\dots,q_k $ $ {\cal{A}}_\varphi $ $ q_k\in F $ $ \rho[k] = s_k = (q_k,\sigma_{1k}\dots\sigma_{nk})\in T $ $ T $ □ Let
$ {\text{Paths}}_{T, {\cal{M}}'_\pi}(s'_0) $ $ \pi $ $ {\cal{M}}' $ $ s'_0 $ $ T $ $ {\text{Paths}}_{T, {\cal{M}}'_\pi}(s'_0) = ((S' \setminus T ) \times A)^*T \cap {\text{Paths}}_{ {\cal{M}}'_\pi}(s'_0) $ Lemma 6
$ \rho\in {\text{Paths}}_{T, {\cal{M}}'_\pi}(s'_0) $ $ {\tilde \tau}_{\varphi, {\cal{C}}}(\rho)\in {\cal{H}}^{\varphi}_{ {\gamma}, {\cal{C}}} $ Proof By Lemma 5,
$ \rho\in {\text{Paths}}_{T, {\cal{M}}'_\pi} $ $ h = {\tilde \tau}_{\varphi, {\cal{C}}}(\rho) $ $ \rho $ $ T $ $ {\text{Paths}}_{T, {\cal{M}}'_\pi}\subseteq {\text{Paths}}_{ {\cal{M}}'_\pi} $ $ \rho\in {\text{Paths}}_{T, {\cal{M}}'_\pi} $ $ h $ $ {\gamma} $ $ \rho' $ $ m $ $ \rho $ $ \rho'[m] \not\in T $ $ h' = {\tilde \tau}_{\varphi, {\cal{C}}}(\rho') $ $ h'\in {\text{prefixes}}(h) $ $ h'\neq h $ $ h' $ $ {\cal{H}}^{\varphi}_{ {\gamma}, {\cal{C}}} $ □ This result shows the correctness of our technique:
Theorem 3 Let
$ ( {\cal{C}}, \varphi) $ $ {\cal{M}}' $ $ {\cal{C}} $ $ \varphi $ $ \pi $ $ {\gamma} $ Proof First, we show that
$ \pi = \arg\max_{\pi'} {\mathbb{P}}_{ {\cal{M}}_\pi',s'_0}(\lozenge T) $ $ {\gamma} = \arg\max_{ {\gamma}'} {\cal{P}}_{ {\cal{C}},\varphi}^ {\text{reach}}( {\gamma}') $ $ \pi $ $ {\gamma} $ $ {\mathbb{P}}_{\pi,s'_0}(\lozenge T) = \sum\limits_{\rho_T\in {\text{Paths}}_{T,\pi}(s'_0)} {\mathbb{P}}_{ {\cal{M}}'_{\pi},s'_0}( {\text{Paths}}_{ {\cal{M}}'_\pi}^\omega(\rho_T)) $ (10) $ = \sum\limits_{h\in {\cal{H}}^{\varphi}_{ {\gamma}, {\cal{C}}}} {\mathbb{P}}_{ {\gamma}, {\cal{C}}}( {\cal{T}}_{ {\gamma}, {\cal{C}}}(h)) $ (11) $ = {\mathbb{P}}_{ {\gamma}, {\cal{C}}}\bigg(\bigcup_{h\in {\cal{H}}^{\varphi}_{ {\gamma}, {\cal{C}}}} {\cal{T}}_{ {\gamma}, {\cal{C}}}(h) \bigg) $ (12) $ = {\cal{P}}_{ {\cal{C}},\varphi}^ {\text{reach}}( {\gamma}) $ (13) where step 10 is by definition of probabilistic reachability, step 11 is by Lemma 4 and 6, step 12 is by disjointness of all
$ {\cal{T}}_{ {\gamma}, {\cal{C}}}(h) $ $ h\in {\cal{H}}^{\varphi}_{ {\gamma}, {\cal{C}}} $ $ \pi^* = \arg\max_{\pi'} {\mathbb{P}}_{ {\cal{M}}_{\pi'},s'_0}(\lozenge T) $ $ {\gamma}^* = \arg\max_{ {\gamma}'} {\cal{P}}_{ {\cal{C}},\varphi}^ {\text{reach}}( {\gamma}') $ It remains to prove that
$ \pi $ $ {\gamma} $ $ \begin{array}{l} {\mathbb{E}}_{\rho\sim {\cal{M}}'_\pi,s'_0} [ {\text{cost}}_T(\rho) \mid \lozenge T] = \\ \;\;\;\;\;\;\;\;\;\; = \sum\limits_{\rho_T\in {\text{Paths}}_{T,\pi}(s'_0)} {\mathbb{P}}_{ {\cal{M}}'_{\pi'},s'_0}( {\text{Paths}}_{ {\cal{M}}'_\pi}^\omega(\rho_T)) \cdot \sum\limits_{k = 0}^{|\rho_T|} C'(s'_k,a'_{k+1}) \end{array} $ (14) $ = \sum\limits_{h\in {\cal{H}}^{\varphi}_{ {\gamma}, {\cal{C}}}} {\mathbb{P}}_{ {\gamma}, {\cal{C}}}( {\cal{T}}_{ {\gamma}, {\cal{C}}}(h)) \cdot \sum\limits_{k = 0}^{|h|} C_{o_{k+1}}(\sigma_{o_k,k},a_{k+1}) $ (15) $ = {\mathbb{E}}_{h\sim {\mathbb{P}}_{ {\gamma}, {\cal{C}}}}\Bigg[ \sum\limits_{k = 1}^{|h|} C_{o_k}(\sigma_{o_k,k-1},a_{k}) \bigg\vert\ {\text{successful}}(h) \Bigg] $ (16) $ = {\cal{J}}^{ {{\text{cost}}}}_{ {\cal{C}},\varphi}( {\gamma}) $ (17) where step 14 by definition of total expected cost conditioned on reaching of target states
$ T $ $ {\cal{M}}' $ $ {\gamma} $ $ \pi\in \arg\min_{\pi'} {\mathbb{E}}_{\rho\sim {\cal{M}}'_\pi,s'_0}[ {\text{cost}}_T(\rho) \mid \lozenge T] $ $ {\gamma}\in \arg\min_{ {\gamma}'} {\cal{J}}^{ {{\text{cost}}}}_{ {\cal{C}},\varphi}( {\gamma}') $ □ Computational cost. Theorem 3 guarantees that we can reduce Problem 1 to the problem of finding an optimal policy for the lexicographic bi-objective optimization problem (Eq. [6]) over a composition MDP
$ {\cal{M}}' $ Theorem 4 Problem 1 can be solved in at most double-exponential time in the size of the formula, in at most exponential time in the number of services, and in polynomial time in the size of the services.
This is in line with the classical setting of ʟᴛʟ/ʟᴛʟf synthesis on probabilistic systems[39,40], and analogous to our solution method for the non-stochastic case[41].
-
In this section, we consider the composition problem where the first objective is to maximize the probability of not violating a safety ʟᴛʟf specification, and as second objective, we maximize the expected conditional cost. This means that the notion of successful execution must be revised in order to consider a safety goal rather than a reachability goal.
We say that some infinite execution
$ t\in {\cal{T}}_{ {\gamma}, {\cal{C}}} $ $ {\cal{C}} $ $ \varphi $ $ {\text{legal}}_{ {\cal{C}},\varphi}(h) $ $ h\in {\text{prefixes}}(t) $ $ {\text{actions}}(h)\models\varphi $ $ k $ $ i $ $ \sigma_{i,k}\in F_i $ $ {\text{legal}}_{ {\cal{C}},\varphi}(h) $ $ {{\cal{H}}}^{\varphi,{\text{safe}}}_{ {\gamma}, {\cal{C}}} $ $ {\gamma} $ $ {\cal{C}} $ $ {\gamma} $ $ \varphi $ $ {\cal{C}} $ $ t\in {\cal{T}}_{ {\gamma}, {\cal{C}}} $ $ t $ $ {\cal{C}} $ $ \varphi $ $ {\text{legal}}_{ {\cal{C}},\varphi} $ $ {\text{legal}} $ Example 4 Continuing with example 1, we consider the following
${\rm{LTL}} _f $ $ \Box\lnot{pluck} $ $ {pluck} $ $ a_1 $ $ b_1 $ $ c_2 $ $ {\cal{B}}_1 $ $ {\cal{B}}_2 $ $ {\cal{B}}_3 $ $ {pluck} $ $ c_0 $ The satisfaction probability of the safety task
$ \varphi $ $ {\gamma} $ $ {\cal{C}} $ $ {\cal{P}}^{ {\text{safe}}}_{ {\cal{C}},\varphi}( {\gamma}) = {\mathbb{P}}_{ {\gamma}, {\cal{C}}}\bigg(\big\{t \in {\cal{T}}_{ {\gamma}, {\cal{C}}} \,\big\vert\, {\text{legal}}(t)\big\}\bigg) $ (18) Intuitively,
$ {\cal{P}}_{ {\cal{C}},\varphi}^ {\text{safe}}( {\gamma}) $ $ {\mathbb{P}}_{ {\gamma}, {\cal{C}}} $ $ {\gamma} $ $ {\cal{C}} $ To formally define the second objective, we first define the total cost of horizon
$ m $ $ t = (\sigma_{10}\dots\sigma_{n0}),(a_1,o_1),\dots $ $ {{\text{Cost}}^{{\rm{C}}}_m}(t) = \sum^{m-1}_{i = 0} C_{o_i}(\sigma_{o_i}, a_{i+1}) $ $ {\gamma} $ $ \sigma = (\sigma_1,\dots,\sigma_n) $ $ {\mathbb{E}}_{ {\gamma},\sigma}[MC] = \limsup\limits_{m\to\infty} \frac{1}{m} {\mathbb{E}}_{h\sim {\gamma},\sigma}[ {{\text{Cost}}^{{\rm{C}}}_m}] $ (19) The optimal expected average cost starting from a state
$ \sigma $ $ {\gamma} $ $ {\cal{C}} $ $ \inf_ {\gamma}{\mathbb{E}}_{ {\gamma}, \sigma}[MC] $ $ {\mathbb{E}}_{h\sim\mathbb{P}_{ {\gamma}, {\cal{C}}}}[ {{\text{Cost}}^{{\rm{C}}}_m} \mid {\text{legal}}(h)] $ $ h $ $ {\cal{J}}^{ {{\text{avg}\text-\text{cost}}}}_{ {\cal{C}},\varphi}( {\gamma}) = \limsup\limits_{m\to\infty} \frac{1}{m}{\mathbb{E}}_{h\sim\mathbb{P}_{ {\gamma}, {\cal{C}}}}\Bigg[ {{\text{Cost}}^{{\rm{C}}}_m} \mid {\text{legal}}(h)\Bigg] $ (20) Intuitively,
$ {\cal{J}}^{ {{\text{avg}\text{-}\text{cost}}}}_{ {\cal{C}},\varphi}( {\gamma}) $ Finally, we define our optimization problem. We want to compute an orchestrator
$ {\gamma} $ $ {\gamma}\in\Gamma_{ {\cal{P}}^{ {\text{safe}}}_{ {\cal{C}},\varphi}} \text{ and } {\cal{J}}^{ {{\text{avg}\text-\text{cost}}}}_{ {\cal{C}},\varphi}( {\gamma}) = \inf\limits_{ {\gamma}'\in\Gamma_{ {\cal{P}}^{ {\text{safe}}}_{ {\cal{C}},\varphi}}} {\cal{J}}^{ {{\text{avg}\text-\text{cost}}}}_{ {\cal{C}},\varphi}( {\gamma}') $ (21) Intuitively, we fix a lexicographic order on the objective functions
$ {\cal{P}}^{ {\text{safe}}}_{ {\cal{C}},\varphi} $ $ {\cal{J}}^{ {{\text{avg}\text{-}\text{cost}}}}_{ {\cal{C}},\varphi} $ Now we aim to find a connection between the satisfaction probability and the notion of realizability.
Let us consider the set of finite executions of
$ {\gamma} $ $ {\cal{C}} $ $ \overline{ {\cal{H}}^{\varphi}_{ {\gamma}, {\cal{C}}}} $ $ \overline{ {\cal{H}}^{\varphi}_{ {\gamma}, {\cal{C}}}} = \{ h\in {\cal{H}}_{ {\gamma}, {\cal{C}}} \mid \lnot {\text{legal}}(h) \wedge \forall h'\in( {\text{prefixes}}(h)\setminus\{h\}): {\text{legal}}(h') \} $ (22) Lemma 7 Let
$ t $ $ {\gamma} $ $ {\cal{C}} $ $ t $ $ t\not\in \left(\bigcup_{h\in\overline{ {\cal{H}}^{\varphi}_{ {\gamma}, {\cal{C}}}}} {\cal{T}}_{ {\gamma}, {\cal{C}}}(h) \right) $ Proof
$ (\Rightarrow) $ $ t\in (\bigcup_{h\in\overline{ {\cal{H}}^{\varphi}_{ {\gamma}, {\cal{C}}}}} {\cal{T}}_{ {\gamma}, {\cal{C}}}(h)) $ $ h\in\overline{ {\cal{H}}^{\varphi}_{ {\gamma}, {\cal{C}}}} $ $ t\in {\cal{T}}_{ {\gamma}, {\cal{C}}}(h) $ $ \overline{ {\cal{H}}^{\varphi}_{ {\gamma}, {\cal{C}}}} $ $ \lnot {\text{legal}}(h) $ $ h\in {\text{prefixes}}(t) $ $ {\cal{T}}_{ {\gamma}, {\cal{C}}}(h) $ $ {\text{legal}} $ $ \lnot {\text{legal}}(t) $ $ t $ $ t $ $ (\Leftarrow) $ $ t $ $ h\in {\text{prefixes}}(t) $ $ \lnot {\text{legal}}(h) $ $ h' $ $ \overline{ {\cal{H}}^{\varphi}_{ {\gamma}, {\cal{C}}}} $ $ h\in\overline{ {\cal{H}}^{\varphi}_{ {\gamma}, {\cal{C}}}} $ $ h'\in {\text{prefixes}}(t) $ $ t\in {\cal{T}}_{ {\gamma}, {\cal{C}}}(h') $ □ Observe that, from Lemma 7, the following equality holds:
$ \big\{t \in {\cal{T}}_{ {\gamma}, {\cal{C}}} \,\big\vert\, {\text{legal}}(t)\big\} = {\cal{T}}_{ {\gamma}, {\cal{C}}} \setminus \bigg(\bigcup\limits_{h\in\overline{ {\cal{H}}^{\varphi}_{ {\gamma}, {\cal{C}}}}} {\cal{T}}_{ {\gamma}, {\cal{C}}}(h) \bigg) $ (23) And in turn, from Eq. (23), we have:
$ \begin{split} {\cal{P}}^{ {\text{safe}}}_{ {\cal{C}},\varphi}( {\gamma}) =\;&{\mathbb{P}}_{ {\gamma}, {\cal{C}}}\bigg(\big\{t \in {\cal{T}}_{ {\gamma}, {\cal{C}}}) \,\big\vert\, {\text{legal}}(t)\big\}\bigg)\\ =\;& {\mathbb{P}}_{ {\gamma}, {\cal{C}}}\Bigg( {\cal{T}}_{ {\gamma}, {\cal{C}}} \setminus \bigg(\bigcup_{h\in\overline{ {\cal{H}}^{\varphi}_{ {\gamma}, {\cal{C}}}}} {\cal{T}}_{ {\gamma}, {\cal{C}}}(h) \bigg)\Bigg)\\ =\;& {\mathbb{P}}_{ {\gamma}, {\cal{C}}}( {\cal{T}}_{ {\gamma}, {\cal{C}}}) - {\mathbb{P}}_{ {\gamma}, {\cal{C}}}\Bigg( {\cal{T}}_{ {\gamma}, {\cal{C}}} \cap \bigg(\bigcup_{h\in\overline{ {\cal{H}}^{\varphi}_{ {\gamma}, {\cal{C}}}}} {\cal{T}}_{ {\gamma}, {\cal{C}}}(h) \bigg)\Bigg)\\ =\;& 1 - {\mathbb{P}}_{ {\gamma}, {\cal{C}}}\bigg(\bigcup_{h\in\overline{ {\cal{H}}^{\varphi}_{ {\gamma}, {\cal{C}}}}} {\cal{T}}_{ {\gamma}, {\cal{C}}}(h) \bigg) \end{split} $ (24) The intuitive meaning of the expression in Eq. (24) for
$ {\cal{P}}^{ {\text{safe}}}_{ {\cal{C}},\varphi} $ $ h $ $ \lnot {\text{legal}}(h) $ In case the specification is exactly realizable, the notion of optimal orchestrator according to Eq. (21) coincides with the notion of 'safe realizability', as shown in the following results.
Lemma 8 Orchestrator
$ {\gamma} $ $ \varphi $ $ {\cal{C}} $ $ \overline{ {\cal{H}}^{\varphi}_{ {\gamma}, {\cal{C}}}} = \emptyset $ Proof (
$ \Rightarrow $ $ \overline{ {\cal{H}}^{\varphi}_{ {\gamma}, {\cal{C}}}} \neq \emptyset $ $ h $ $ \overline{ {\cal{H}}^{\varphi}_{ {\gamma}, {\cal{C}}}} $ $ t $ $ h $ $ t\in {\cal{T}}_{ {\gamma}, {\cal{C}}}(h) $ $ {\gamma} $ $ \varphi $ $ {\gamma} $ $ \varphi $ (
$ \Leftarrow $ $ {\gamma} $ $ \varphi $ $ t\in {\cal{T}}_{ {\gamma}, {\cal{C}}} $ $ \lnot {\text{legal}}(t) $ $ t\in {\cal{T}}_{ {\gamma}, {\cal{C}}}(h) $ $ h\in\overline{ {\cal{H}}^{\varphi}_{ {\gamma}, {\cal{C}}}} $ $ \overline{ {\cal{H}}^{\varphi}_{ {\gamma}, {\cal{C}}}}\neq\emptyset $ □ Theorem 5 Let
$ {\cal{C}} $ $ \varphi $ ${\rm{LTL}} _f $ $ {\gamma} $ $ \varphi $ $ {\cal{C}} $ $ {\cal{P}}^{ {\text{safe}}}_{ {\cal{C}},\varphi}( {\gamma}) = 1 $ Proof (
$ \Rightarrow $ $ {\gamma} $ $ \varphi $ $ \overline{ {\cal{H}}^{\varphi}_{ {\gamma}, {\cal{C}}}} = \emptyset $ $ {\mathbb{P}}_{ {\gamma}, {\cal{C}}}(\bigcup_{h\in\overline{ {\cal{H}}^{\varphi}_{ {\gamma}, {\cal{C}}}}} {\cal{T}}_{ {\gamma}, {\cal{C}}}(h)) = 0 $ $ {\cal{P}}^{ {\text{safe}}}_{ {\cal{C}},\varphi} $ $ {\cal{P}}^{ {\text{safe}}}_{ {\cal{C}},\varphi}( {\gamma}) = 1 - {\mathbb{P}}_{ {\gamma}, {\cal{C}}}(\bigcup_{h\in\overline{ {\cal{H}}^{\varphi}_{ {\gamma}, {\cal{C}}}}} {\cal{T}}_{ {\gamma}, {\cal{C}}}(h)) = 1 $ (
$ \Leftarrow $ $ {\cal{P}}^{ {\text{safe}}}_{ {\cal{C}},\varphi}( {\gamma}) = 1 $ $ {\cal{P}}^{ {\text{safe}}}_{ {\cal{C}},\varphi} $ $ {\mathbb{P}}_{ {\gamma}, {\cal{C}}}(\bigcup_{h\in\overline{ {\cal{H}}^{\varphi}_{ {\gamma}, {\cal{C}}}}} {\cal{T}}_{ {\gamma}, {\cal{C}}}(h)) = 0 $ $ {\mathbb{P}}_{ {\gamma}, {\cal{C}}} $ $ \overline{ {\cal{H}}^{\varphi}_{ {\gamma}, {\cal{C}}}} = \emptyset $ □ Theorem 6 Assume ʟᴛʟf safety specification
$ \varphi $ $ {\gamma} $ $ \varphi $ Proof Since by assumption
$ \varphi $ $ {\gamma}' $ $ {\cal{P}}^{ {\text{safe}}}_{ {\cal{C}},\varphi}( {\gamma}') $ $ 1 $ $ {\gamma} \in \Gamma_{ {\cal{P}}^{ {\text{safe}}}_{ {\cal{C}},\varphi}} $ $ {\cal{P}}^{ {\text{safe}}}_{ {\cal{C}},\varphi}( {\gamma}) = 1 $ $ {\gamma} $ $ \varphi $ Finally, we formally state the stochastic version of our problem:
Problem 2 (Stochastic Composition for ltlf Safety Tasks). Given the pair
$ ( {\cal{C}}, \varphi) $ $ \varphi $ $ A $ $ {\cal{C}} $ $ n $ $ {\cal{C}} = \{ {\cal{S}}_1,\dots, {\cal{S}}_n\} $ As in the reachability case of Section 4, Theorems 5 and 6 show that one can find an orchestrator even in a non-stochastic setting by considering arbitrary services' probability distributions for
$ P_i(\sigma_i,a) $ $ \sigma_i $ $ a $ $ \max_ {\gamma} {\cal{P}}^{ {\text{safe}}}_{ {\cal{C}},\varphi}( {\gamma}) = 1 $ 5.1. Solution technique
-
Similarly to the previous case, the solution technique for the safety variant of the composition problem relies on finding an optimal policy for a bi-objective lexicographic optimization on a specifically built MDP. In particular, also for this problem, we consider a variant of the framework introduced in study by Busatto-Gaston et al.[35]; while the second objective they considered was the maximization of the expected conditional mean payoff, here we consider the minimization of the expected conditional mean costs. In general, the technique has a significant overlap with the reachability variant. However, the main difference lies in how we build the automata-based construction: in the reachability case, we are interested in an orchestrator such that, for any (infinite) execution
$ t $ $ t $ $ \varphi $ $ \varphi $ Our technique breaks down into the following steps: (1) first, we translate the
${\rm{LTL}} _f $ $ {\rm{DFA}}$ $ {\cal{A}}_\varphi $ $ {\cal{A}}_\varphi $ $ {\cal{A}}_{\varphi} $ $ {\cal{C}} $ $ {\cal{M}}' $ $ \pi $ $ {\cal{M}}' $ $ {\gamma} $ $ \pi $ Step 1. This step is the same as the previous case: starting from the
${\rm{LTL}} _f $ $ \varphi $ $ {\rm{DFA}}$ $ {\cal{A}}_\varphi = (A, Q, q_0, F, \delta) $ $ \varphi $ Step 2. Then, we define the composition MDP
$ {\cal{M}}' = (S', A', P', s'_0) $ $ C' $ $ {\cal{M}}' $ $ {\text{Bad}} = \{(q,\sigma_1,\dots,\sigma_n) \mid (q,\sigma_1,\dots,\sigma_n)\in S' \wedge (q\not\in F \vee \exists i\in [1,n]\,: \sigma_i \not\in F_i)\} $ In other words,
$ {\text{Bad}}$ $ Q $ $ {\cal{M}}' $ $ {\text{Bad}} $ $ s\in S' $ $ \pi $ $ {\cal{M}}' $ $ {\mathbb{P}}_{ {\cal{M}}'_\pi,s}(\Box \lnot {\text{Bad}}) $ $ \Pi_{ {\cal{M}}',s}(\Box \lnot {\text{Bad}}) $ $ {\text{Bad}} $ $ s $ $ \arg\max_\pi {\mathbb{P}}_{ {\cal{M}}'_\pi,s}(\Box\lnot {\text{Bad}}) $ $ {\mathbb{E}}_{ {\cal{M}}'_\pi,s'_0}[MC \mid \Box\lnot {\text{Bad}}] $ $ {\cal{M}}' $ $ \pi $ $ \limsup_{m\to\infty} \frac{1}{n} {\mathbb{E}}_{ {\cal{M}}'_\pi,s'_0}[ {{\text{Cost}}_m} \mid \Box\lnot {\text{Bad}}] $ $ \Pi_{ {\cal{M}}',s'_0}(\Box\lnot {\text{Bad}}) $ $ {\mathbb{P}}_{ {\cal{M}}'_\pi,s'_0}(\Box\lnot {\text{Bad}}) $ $ \pi\in \Pi_{ {\cal{M}}',s'_0}(\Box\lnot {\text{Bad}}) \text{ and } \pi\in\arg\limits_{\pi'}\inf {\mathbb{E}}_{\rho\sim {\cal{M}}'_{\pi'},s_0}[MC \mid \Box\lnot {\text{Bad}}] $ (25) Step 3. The solution technique we will use is, once again, based on the work[35], where the authors propose a two-stage technique to find an optimal policy for a bi-objective lexicographic function in the form of Eq. (25). First, we compute the set of policies (in the form of a set of optimal actions for each state) that maximize the probability of staying far from the bad set of states
$ {\text{Bad}} $ $ \varphi $ $ Q $ $ {\cal{A}}_\varphi $ Step 4. Once an optimal policy is found, we can obtain its equivalent
$ {\gamma} $ Now we are going to establish a relationship between optimal orchestrators according to Eq. (21), and optimal policies for
$ {\cal{M}}' $ $ {\cal{M}}' $ Let
$ {\text{Paths}}^\omega_{\lnot {\text{Bad}}, {\cal{M}}'_\pi}(s'_0) $ $ \pi $ $ {\cal{M}}' $ $ s'_0 $ $ {\text{Bad}}$ $ {\text{Paths}}^\omega_{\lnot {\text{Bad}}, {\cal{M}}'_\pi}(s'_0) = ((S'\setminus {\text{Bad}}) \times A)^\omega\cap {\text{Paths}}^\omega_{ {\cal{M}}'_\pi}(s'_0) $ $ {\text{Paths}}_{ {\text{Bad}}, {\cal{M}}'_\pi}(s'_0) $ $ \pi $ $ {\cal{M}}' $ $ s'_0 $ $ {\text{Bad}}$ $ {\text{Paths}}_{ {\text{Bad}}, {\cal{M}}'_\pi}(s'_0) = ((S'\setminus {\text{Bad}}) \times A)^* {\text{Bad}}\cap {\text{Paths}}_{ {\cal{M}}'_\pi}(s'_0) $ $ {\text{Paths}}^\omega_{ {\text{Bad}}, {\cal{M}}'_\pi}(s'_0) = \bigcup_{\rho'\in {\text{Paths}}_{ {\text{Bad}}, {\cal{M}}'_\pi}(s'_0)} {\text{Paths}}^\omega_{ {\cal{M}}'_\pi}(\rho') $ $ {\text{Paths}}_{\lnot {\text{Bad}}, {\cal{M}}'_\pi}(s_0') $ $ {\text{Bad}} $ $ {\text{Paths}}^\omega_{\lnot {\text{Bad}}, {\cal{M}}'_\pi}(s'_0) $ $ {\text{Paths}}^\omega_{ {\text{Bad}}, {\cal{M}}'_\pi}(s'_0) $ $ \rho'\in {\text{Paths}}_{ {\text{Bad}}, {\cal{M}}'_\pi}(s'_0) $ $ \rho\in {\text{Paths}}^\omega_{\lnot {\text{Bad}}, {\cal{M}}'_\pi}(s'_0) $ $ {\text{last}}(\rho')\in {\text{Bad}} $ $ \rho $ Lemma 9 The following two propositions hold:
1.
$ {\text{Paths}}^\omega_{\lnot {\text{Bad}}, {\cal{M}}'_\pi}(s'_0) \cap {\text{Paths}}^\omega_{ {\text{Bad}}, {\cal{M}}'_\pi}(s'_0) = \emptyset $ 2.
$ {\text{Paths}}^\omega_{\lnot {\text{Bad}}, {\cal{M}}'_\pi}(s'_0) \cup {\text{Paths}}^\omega_{ {\text{Bad}}, {\cal{M}}'_\pi}(s'_0) = {\text{Paths}}^\omega_{ {\cal{M}}'_\pi}(s'_0) $ Another crucial observation is that
$ {\text{Paths}}_{ {\text{Bad}}, {\cal{M}}'_\pi}(s'_0) $ $ \lnot {\text{Bad}} $ Lemma 10 Let
$ \rho = s_0a_1\dots s_m\in {\text{Paths}}_{ {\cal{M}}'_\pi} $ $ {\cal{M}}'_\pi $ $ \pi $ $ h = {\tilde \tau}_{\varphi, {\cal{C}}}(\rho) $ $ {\text{legal}}(h) $ $ k\in [0,m] $ $ s_k\not\in {\text{Bad}} $ Proof We prove that
$ \lnot {\text{legal}}(h) $ $ \exists k. s_k\in {\text{Bad}} $ $ {\text{Bad}} $ $ s = (q,\sigma_1,\dots,\sigma_n) $ $ q\not\in F $ $ i $ $ \sigma_i\not\in F_i $ $ k $ $ s_k $ $ \rho $ $ s_k $ $ Q $ $ \rho[0:k] $ $ r = q_0,\dots,q_k $ $ {\cal{A}}_\varphi $ $ a_1\dots a_{k} $ $ a_1\dots a_{k}\in {\cal{L}}( {\cal{A}}_\varphi) $ $ {\cal{A}}_\varphi $ $ a_1\dots a_{k}\not\models \varphi $ $ {\tilde \tau} $ $ {\text{actions}}(h')\not\models\varphi $ $ h' = h[0:k] $ $ {\text{legal}} $ $ k $ $ \lnot {\text{legal}}(h) $ □ Lemma 11 Let
$ \pi $ $ {\cal{M}}' $ $ {\gamma} $ $ \rho = s_0a_1s_1\cdots s_m\in {\text{Paths}}_{ {\cal{M}}'_\pi} $ $ {\cal{M}}'_\pi $ $ h = {\tilde \tau}_{\varphi, {\cal{C}}}(\rho) $ $ \rho\in {\text{Paths}}_{ {\text{Bad}}, {\cal{M}}'_\pi} $ $ h\in\overline{ {\cal{H}}^{\varphi}_{ {\gamma}, {\cal{C}}}} $ Proof First, note that by Lemma 3,
$ \rho\in {\text{Paths}}_{ {\cal{M}}'_\pi} $ $ h = {\tilde \tau}_{\varphi, {\cal{C}}}(\rho) $ $ {\gamma} $ $ (\Rightarrow) $ $ \rho[m]\in {\text{Bad}} $ $ \lnot {\text{legal}}(h) $ $ j = 0,\dots,m-1 $ $ \rho[0:j] $ $ {\text{Bad}} $ $ h[0:j]\in {\text{prefixes}}(h) $ $ {\text{legal}}(h[0:j]) $ $ \overline{ {\cal{H}}^{\varphi}_{ {\gamma}, {\cal{C}}}} $ $ h\in\overline{ {\cal{H}}^{\varphi}_{ {\gamma}, {\cal{C}}}} $ $ (\Leftarrow) $ $ h\in\overline{ {\cal{H}}^{\varphi}_{ {\gamma}, {\cal{C}}}} $ $ \overline{ {\cal{H}}^{\varphi}_{ {\gamma}, {\cal{C}}}} $ $ \lnot {\text{legal}}(h) $ $ h'\in {\text{prefixes}}(h) $ $ h'\neq h $ $ {\text{legal}}(h') $ $ j = 0,\dots,m-1 $ $ \rho[0:j] $ $ {\text{Bad}} $ $ k\in[0,m] $ $ \rho[k]\in {\text{Bad}} $ $ k $ $ m $ $ m $ $ \rho $ $ {\text{Bad}} $ $ \rho $ $ {\text{Bad}} $ $ \rho $ $ {\text{Paths}}_{ {\text{Bad}}, {\cal{M}}'_\pi} $ $ \rho\in {\text{Paths}}_{ {\text{Bad}}, {\cal{M}}'_\pi} $ □ Lemma 12 Let
$ \pi $ $ {\cal{M}}' $ $ {\gamma} $ $ \rho = s_0a_1s_1\cdots s_m\in {\text{Paths}}_{ {\cal{M}}'_\pi} $ $ {\cal{M}}'_\pi $ $ h = {\tilde \tau}_{\varphi, {\cal{C}}}(\rho) $ $ \rho\in {\text{Paths}}_{\lnot {\text{Bad}}, {\cal{M}}'_\pi} $ $ h\in {{\cal{H}}^{\varphi,{\text{safe}}}}_{ {\gamma}, {\cal{C}}} $ Proof By definition of
$ {{\cal{H}}^{\varphi,{\text{safe}}}}_{ {\gamma}, {\cal{C}}} $ $ h\in {{\cal{H}}^{\varphi,{\text{safe}}}}_{ {\gamma}, {\cal{C}}} $ $ {\text{legal}}(h) $ $ {\text{legal}}(h) $ $ k = 0\dots m $ $ \rho[k]\not\in {\text{Bad}} $ $ {\text{Paths}}_{\lnot {\text{Bad}}, {\cal{M}}'_\pi} $ $ \rho\in {\text{Paths}}_{\lnot {\text{Bad}}, {\cal{M}}'_\pi} $ □ Theorem 7 Let
$ ( {\cal{C}}, \varphi) $ $ {\cal{M}}' $ $ {\cal{C}} $ $ \varphi $ $ \pi $ $ {\gamma} $ Proof First, we show that
$ \pi = \arg\max_{\pi'} {\mathbb{P}}_{ {\cal{M}}'_\pi,s'_0}(\Box \lnot {\text{Bad}}) $ $ {\gamma} = \arg\max_{ {\gamma}'} {\cal{P}}^{ {\text{safe}}}_{ {\cal{C}},\varphi}( {\gamma}') $ $ \pi $ $ {\gamma} $ $ {\mathbb{P}}_{ {\cal{M}}'_\pi,s'_0}(\Box \lnot {\text{Bad}}) = {\mathbb{P}}_{ {\cal{M}}'_{\pi},s'_0}( {\text{Paths}}^\omega_{\lnot {\text{Bad}}, {\cal{M}}'_\pi}(s'_0)) $ (26) $ = 1 - {\mathbb{P}}_{ {\cal{M}}'_{\pi},s'_0}( {\text{Paths}}^\omega_{ {\text{Bad}}, {\cal{M}}'_\pi}(s'_0)) $ (27) $ = 1 - \sum\limits_{\rho'\in {\text{Paths}}_{ {\text{Bad}}, {\cal{M}}'_\pi}(s'_0)} {\mathbb{P}}_{ {\cal{M}}'_{\pi},s'_0}( {\text{Paths}}^\omega_{ {\cal{M}}'_\pi}(\rho')) $ (28) $ = 1 - \sum\limits_{h\in\overline{ {\cal{H}}^{\varphi}_{ {\gamma}, {\cal{C}}}}} {\mathbb{P}}_{ {\gamma}, {\cal{C}}}( {\cal{T}}_{ {\gamma}, {\cal{C}}}(h)) $ (29) $ = 1 - {\mathbb{P}}_{ {\gamma}, {\cal{C}}}\bigg(\bigcup\limits_{h\in\overline{ {\cal{H}}^{\varphi}_{ {\gamma}, {\cal{C}}}}} {\cal{T}}_{ {\gamma}, {\cal{C}}}(h) \bigg) $ (30) $ = {\cal{P}}^{ {\text{safe}}}_{ {\cal{C}},\varphi}( {\gamma}) $ (31) where step 26 is by definition of probabilistic safety, step 27 is by Lemma 9, step 28 is by disjointness of all finite paths
$ \rho'\in {\text{Paths}}_{ {\text{Bad}}, {\cal{M}}'_\pi} $ $ {\text{Bad}}$ $ {\cal{T}}_{ {\gamma}, {\cal{C}}}(h) $ $ h\in\overline{ {\cal{H}}^{\varphi}_{ {\gamma}, {\cal{C}}}} $ $ {\cal{P}}^{ {\text{safe}}}_{ {\cal{C}},\varphi} $ $ \pi^* = \arg\max_{\pi'} {\mathbb{P}}_{ {\cal{M}}'_\pi,s'_0}(\Box \lnot {\text{Bad}}) $ $ {\gamma}^* = \arg\max_{ {\gamma}'} {\cal{P}}^{ {\text{safe}}}_{ {\cal{C}},\varphi}( {\gamma}') $ It remains to prove that
$ \pi $ $ {\gamma} $ $ {\text{Paths}}^{(m)} $ $ {\cal{M}}' $ $ m $ $ {\mathbb{E}}_{ {\cal{M}}'_\pi,s'_0}[ {{\text{Cost}}_m} \mid \Box\lnot {\text{Bad}}] $ $\begin{split} {\mathbb{E}}_{ {\cal{M}}'_\pi,s'_0}( {{\text{Cost}}_m} \mid \Box\lnot {\text{Bad}}) =\;& \sum\limits_{\rho\in {\text{Paths}}^{(m)}_{ {\cal{M}}'_\pi}} {\mathbb{E}}\left[ {{\text{Cost}}_m} \mid {\text{Paths}}^\omega_{ {\cal{M}}'_\pi}(\rho), \Box\lnot {\text{Bad}}\right]\\& {\mathbb{P}}_{ {\cal{M}}'_\pi}\left( {\text{Paths}}^\omega_{ {\cal{M}}'_\pi}(\rho) \mid \Box\lnot {\text{Bad}}\right)\end{split} $ Intuitively, we are averaging the total costs of all paths of length
$ m $ $ {\text{Bad}} $ $ \pi $ $ {\cal{M}} $ $ {{\text{Cost}}_m} $ $ m $ $ {\mathbb{E}}[ {{\text{Cost}}_m}\mid {\text{Paths}}^\omega_{ {\cal{M}}'_\pi}(\rho), \Box\lnot {\text{Bad}}] = {{\text{Cost}}_m} = \sum_{k = 0}^{m-1} C'(s_k',a_{k+1}) $ $ P(A\mid B) = \frac{P(A\cap B)}{P(B)} $ $ s_0' $ $ 0 $ $ \sum\limits_{\rho\in {\text{Paths}}^{(m)}_{ {\cal{M}}'_\pi}(s_0')} \Bigg(\sum\limits_{k = 0}^{m-1} C'(s_k',a_{k+1})\Bigg) \frac{ {\mathbb{P}}_{ {\cal{M}}'_\pi}\left( {\text{Paths}}^\omega_{ {\cal{M}}'_\pi}(\rho) \cap \Box\lnot {\text{Bad}}\right)} { {\mathbb{P}}_{ {\cal{M}}'_\pi}\left(\Box\lnot {\text{Bad}}\right)} $ Note that the denominator
$ {\mathbb{P}}_{ {\cal{M}}'_\pi,s_0'}(\Box\lnot {\text{Bad}} ) $ $ \Box\lnot {\text{Bad}} $ $ {\mathbb{P}}_{M'_\pi,s_0'}(\Box\lnot {\text{Bad}}) = {\mathbb{P}}( {\text{Paths}}^\omega_{\lnot {\text{Bad}}, {\cal{M}}'_\pi}(s_0')) $ $ \sum\limits_{\rho\in {\text{Paths}}^{(m)}_{ {\cal{M}}'_\pi}(s_0')} \Bigg(\sum\limits_{k = 0}^{m-1} C'(s_k',a_{k+1})\Bigg) \frac{ {\mathbb{P}}_{ {\cal{M}}'_\pi,s_0'}\left( {\text{Paths}}^\omega_{ {\cal{M}}'_\pi}(\rho) \cap {\text{Paths}}^\omega_{\lnot {\text{Bad}}, {\cal{M}}'_\pi}(s_0')\right)}{ {\mathbb{P}}_{ {\cal{M}}'_\pi,s_0'}( {\text{Paths}}^\omega_{\lnot {\text{Bad}}, {\cal{M}}'_\pi}(s_0'))} $ Note that whenever
$ \rho\in( {\text{Paths}}^{(m)}_{ {\cal{M}}'_\pi}(s_0')\setminus {\text{Paths}}_{\lnot {\text{Bad}}, {\cal{M}}'_\pi}) $ $ \sum\limits_{\rho\in {\text{Paths}}^{(m)}_{\lnot {\text{Bad}}, {\cal{M}}'_\pi(s_0')}} \Bigg(\sum\limits_{k = 0}^{m-1} C'(s_k',a_{k+1})\Bigg) \frac{ {\mathbb{P}}_{ {\cal{M}}'_\pi,s_0'}( {\text{Paths}}^\omega_{ {\cal{M}}'_\pi}(\rho))}{ {\mathbb{P}}_{ {\cal{M}}'_\pi,s_0'}( {\text{Paths}}^\omega_{\lnot {\text{Bad}}, {\cal{M}}'_\pi}(s_0'))} $ By Lemma 12, there is a bijection between paths in
$ \rho\in {\text{Paths}}^{(m)}_{ {\cal{M}}'_\pi}(s_0') $ $ h\in {{\cal{H}}^{\varphi,{\text{safe}}}}_{ {\gamma}, {\cal{C}}} $ $ |h| = m $ $ \rho $ $ h $ $ {\cal{M}}' $ $ k = 0,\dots,m-1 $ $ C'(s_k',a_{k+1}) $ $ C_{o_{k+1}}(\sigma_{o_{k+1},k}, a_{k+1}) $ $ a_{k+1} $ $ o_{k+1} $ $ {\mathbb{P}}_{ {\cal{M}}'_\pi,s_0'}(\Box\lnot {\text{Bad}}) = {\cal{P}}^{ {\text{safe}}}_{ {\cal{C}},\varphi}( {\gamma}) $ $ {\cal{M}} $ $ t $ $ {\cal{C}} $ $ \begin{split}& \sum\limits_{h\in {{\cal{H}}^{\varphi,{\text{safe}}}}_{ {\gamma}, {\cal{C}}}: |h| = m} \Bigg(\sum\limits_{k = 0}^{m-1} C_{o_{k+1}}(\sigma_{o_{k+1},k},a_{k+1})\Bigg) \frac{ {\mathbb{P}}_{ {\cal{M}}'_\pi,s_0'}( {\cal{T}}_{ {\gamma}, {\cal{C}}}(h))}{ {\cal{P}}^{ {\text{safe}}}_{ {\cal{C}},\varphi}( {\gamma})}\\ =\;& {\mathbb{E}}_{h\sim {\mathbb{P}}_{ {\gamma}, {\cal{C}}}}\Bigg[ {{\text{Cost}}^{{\rm{C}}}_m} \vert\ {\text{legal}}(t) \Bigg] \end{split} $ From the above, it follows that
$\begin{split} {\cal{J}}^{ {{\text{avg}\text-\text{cost}}}}_{ {\cal{C}},\varphi}( {\gamma}) =\;& \limsup\limits_{m\to\infty} \frac{1}{m}{\mathbb{E}}_{h\sim\mathbb{P}_{ {\gamma}, {\cal{C}}}}\Bigg[ {{\text{Cost}}^{{\rm{C}}}_m} \bigg\vert {\text{legal}}(h)\Bigg] \\=\;& \limsup\limits_{m\to\infty} \frac{1}{m} {\mathbb{E}}_{\rho\sim {\cal{M}}'_{\pi},s'_0}(MC \mid \Box\lnot {\text{Bad}}), \end{split}$ since we are taking the limit of equal terms. Therefore,
$ \pi\in\arg\inf_{\pi'} \limsup\limits_{m\to\infty} \frac{1}{m} {\mathbb{E}}_{\rho\sim {\cal{M}}'_{\pi'},s'_0}(MC \mid \Box\lnot {\text{Bad}}) $ $ {\gamma}\in \arg\inf_{ {\gamma}'} {\cal{J}}^{ {{\text{avg}\text{-}\text{cost}}}}_{ {\cal{C}},\varphi}( {\gamma}') $ □ Computational cost. Theorem 7 guarantees that we can reduce Problem 2 to the problem of finding an optimal policy for the lexicographic bi-objective optimization problem (Eq. [6]) over the composition MDP
$ {\cal{M}}' $ As explained above, the two-stage technique requires solving a planning problem over MDPs. Since it is known that both steps require polynomial time complexity in the number of states and actions of the MDP[24] and that our Composition MDP has a state space that is a single-exponential in the size of the goal specification, we get this result:
Theorem 8: Problem 2 can be solved in at most double-exponential time in the size of the formula, in at most exponential time in the number of services, and in polynomial time in the size of the services.
-
To demonstrate how the proposed approach can be instantiated and applied in a smart manufacturing scenario, we consider a representative production process: the assembly of an electric motor a widely used component in various applications such as industrial machinery, electric vehicles, household appliances, and many others[17]. To function properly, electric motors require certain materials that possess specific electrical and magnetic properties. Therefore, before the manufacturing processes start, the raw materials (i.e., copper, steel, aluminium, magnets, insulation materials, bearings) must be extracted and refined to obtain essential metals and polymers for electric motor parts manufacturing. When the materials are in the manufacturing facility, the effective manufacturing process can start. For the sake of brevity, in the following, we focus on the main aspects of the manufacturing process, skipping the provisioning, but the formalization can be easily extended to cover more details.
Goal: Fig. 2 depicts the declare formalization[12] of the electric motor manufacturing process. The main components of an electric motor are the stator, the rotor, and, in the case of alternate current motors with direct current power (e.g., in the case of electric cars). These three components are built or retrieved in any order (no precedence declare constraints between these tasks) and then eventually assembled to build a motor (alternate succession constraint between Build/Retrieve tasks and the Assemble Motor task). After the motor is assembled, a running-in test must be performed (alternate succession constraint between the Assemble Motor task and the Running In task), and at most one (not coexistence constraint) between an electric test and a full static test (the latter comprises the former). In addition, the motor can be painted optionally. The Painting, Electric Test and Static Test tasks optionally follow the Assemble Motor task (alternate precedence constraints). The process depicts the manufacturing tasks involved in producing a single motor as indicated by the existence constraints. Machines and/or human operators can perform all these operations. Each declare pattern can be transformed into an ʟᴛʟf formula[42]. Therefore, the entire process can be encoded into an ʟᴛʟf formula
$ \varphi $ $ \varphi $ 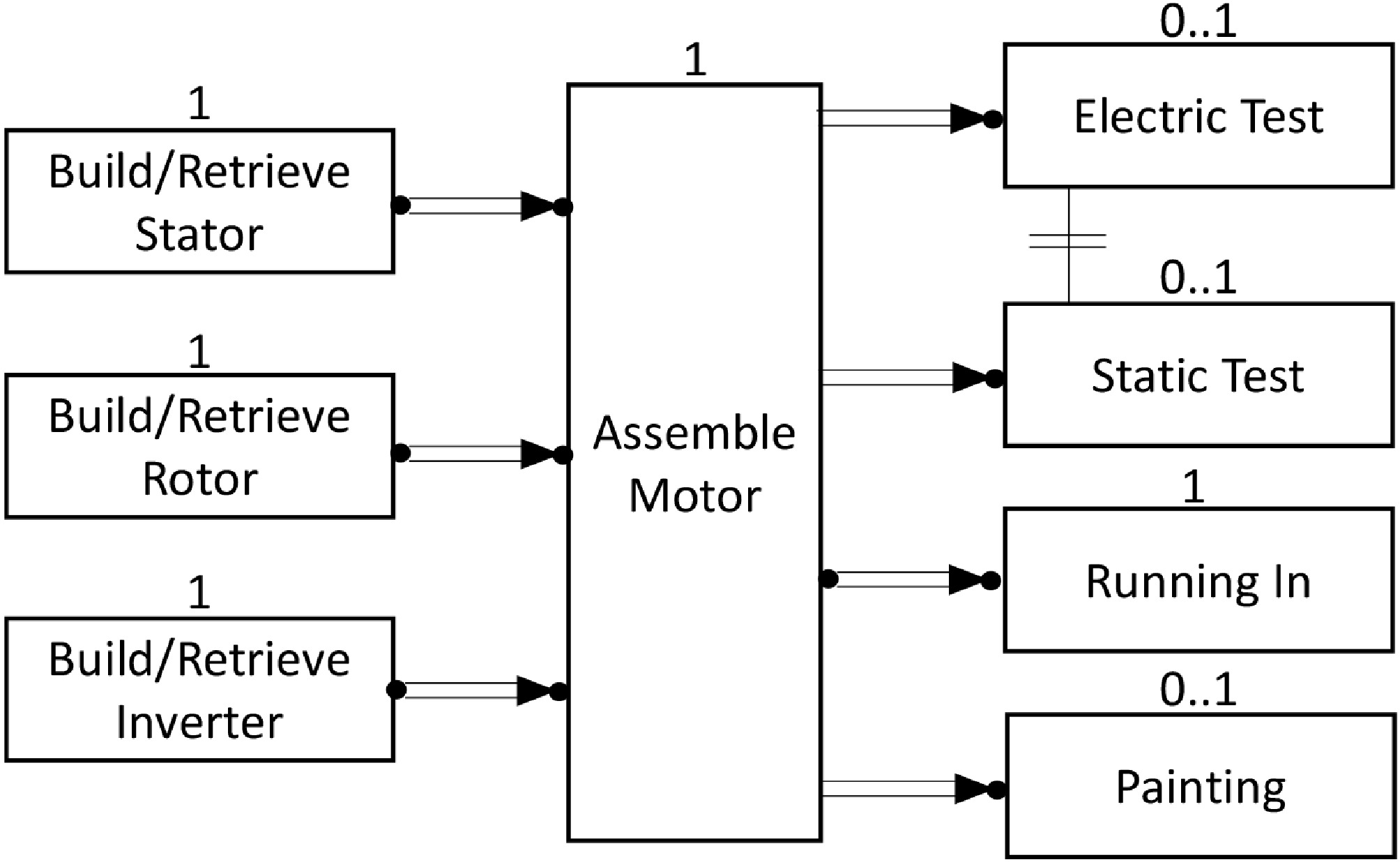
Figure 2.
The electric motor manufacturing process represented using declare.
Services: The behaviour of each process actor can be described as a stochastic service, i.e., a state machine with a probabilistic behaviour used to model two types of actors involved in the manufacturing process, namely machines and human operators, shown in Fig. 3. Each transition edge has a label which indicates the operation, the probability of transition and the associated cost. Figure 3a depicts a simple stochastic service of human workers. Such services have an initial accepting state in which they are READY and accept operations, and a sink failure state from where no action can be taken. The transition triggered by the
$ [OP] $ $ p^s $ $ 1-p^s $ $ c_{i}^{[Op]} $ $ - $ $ p_i^u $ $ 1 - p_i^u $ $ c_i^{[Op]} $ $ i $ $ p_i^b $ $ c_i^{Bad[Op]} $ $ c_i^r $ 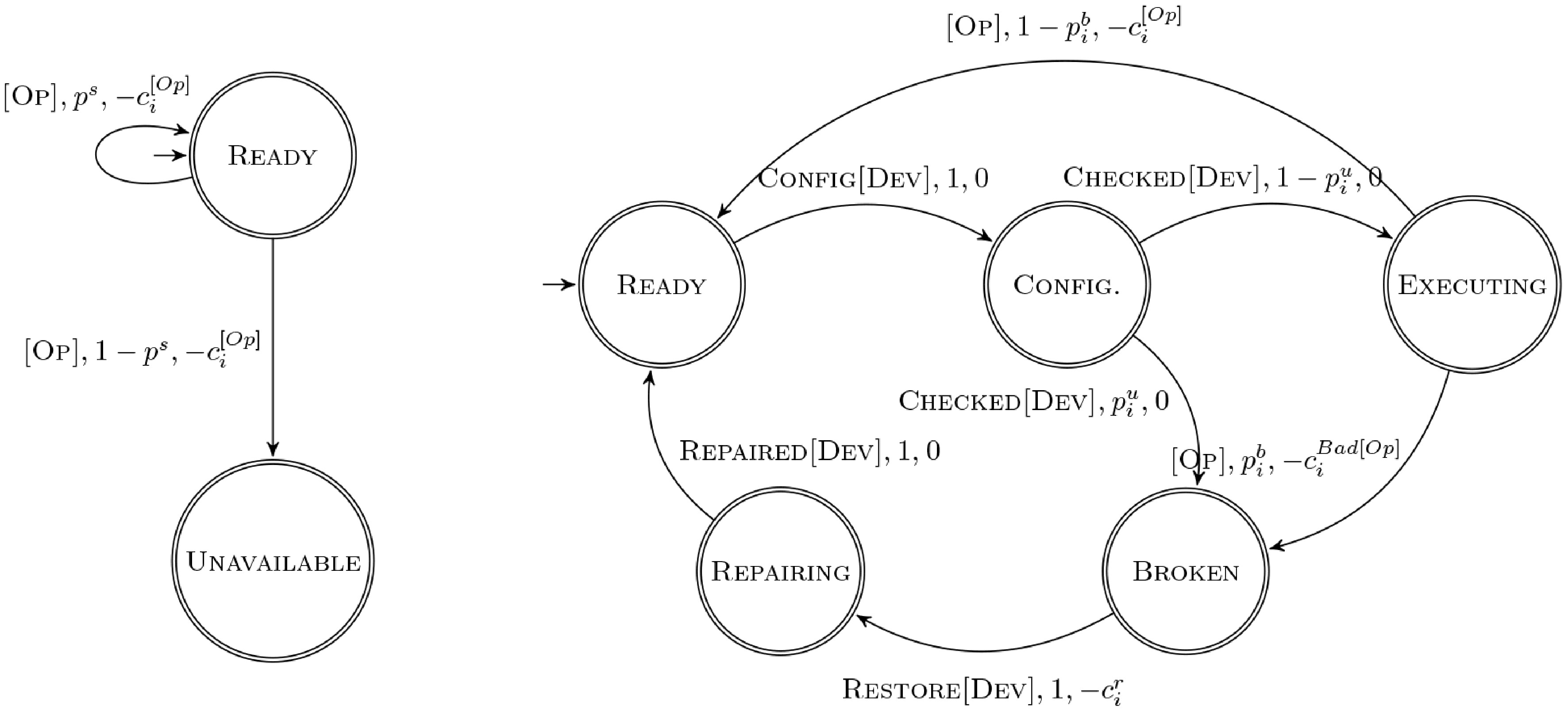
Figure 3.
The two types of service we consider for the electric motor case study. (a) 'Human operator' service. (b) 'Machine' service.
We are interested in the problem of maximising the probability that the smart factory succeeds in producing electric motors at a minimum utilization cost. A two-stage approach can achieve this: in the first stage, we aim to find the maximally permissive strategy that (i) determines the equally optimal sequences of actions to satisfy the goal specification and (ii) the equally optimal dispatching strategy that decides which services should perform the operation. The optimization must also consider configuration/checking/repairing action to bring the service back to a final configuration. This might require limiting the use of services with certain probability of leading to a failing configuration. In the second stage, we select, among the available strategies, those that also minimize the utilization cost. Crucially, the optimal solution might vary depending on the service available and their capabilities, as well as the probabilities
$ p_i^s $ $ p_i^u $ $ p_i^b $ $ c_i^[{OP}] $ $ c_{i}^{Bad[Op]} $ $ c^r_i $ -
This paper proposes a novel stochastic composition framework in which we aim to maximize the satisfaction probability of a goal specification, expressed as a high-level logic formalism such as ʟᴛʟf, and conditioned on this, minimize the utilization costs of the available services. We formalized two variants of the problem, one for reachability tasks and the other for safety tasks, and proposed a solution based on a reduction to a bi-objective optimization over MDPs, proving the correctness. Finally, we highlighted the relevance of our contribution by providing an industrial case study considered in the literature. In future work, we would like to study the process-oriented variant of our framework, namely, to maximize the probability of realizing all traces that are compatible with the specification, and conditioned on this, maximize as much as possible the average expected reward coming from the utilization of the services. This would allow us to consider a hierarchy of target specifications (either goal-oriented or process-oriented), hence delivering a rich framework suitable for several applications. The same kind of generalization can be considered for the service reward/cost function, where we can consider more than one reward regarding service utilization. Moreover, we would like to implement our approach using state-of-the-art probabilistic model checkers such as PRISM[43] and Storm[44]. Another interesting direction for future work is incorporating internal-action hiding and parallel composition, which are standard in compositional modeling frameworks.
This work is supported in part by the ERC Advanced Grant WhiteMech (Grant No. 834228), the PRIN project RIPER (Grant No. 20203FFYLK), the PNRR MUR project FAIR (Grant No. PE0000013), and the UKRI Erlangen AI Hub on Mathematical and Computational Foundations of AI (Grant No. EP/Y028872/1). This work has been carried out while Luciana Silo was enrolled in the Italian National Doctorate on Artificial Intelligence run by Sapienza University of Rome.
-
The authors confirm contributions to the paper as follows: study conception and design: De Giacomo G, Favorito M, Silo L; analysis and interpretation of results: De Giacomo G, Favorito M, Silo L; draft manuscript preparation: De Giacomo G, Favorito M, Silo L. All authors reviewed the results and approved the final version of the manuscript.
-
Data sharing is not applicable to this article as no datasets were generated or analyzed during the current study.
-
The authors declare that they have no conflict of interest.
- Copyright: © 2026 by the author(s). Published by Maximum Academic Press, Fayetteville, GA. This article is an open access article distributed under Creative Commons Attribution License (CC BY 4.0), visit https://creativecommons.org/licenses/by/4.0/.
-
About this article
Cite this article
De Giacomo G, Favorito M, Silo L. 2026. Stochastic service composition for ʟᴛʟf reachability and safety tasks. The Knowledge Engineering Review 41: e003 doi: 10.48130/ker-0026-0003 

Stochastic service composition for ʟᴛʟf reachability and safety tasks
- Received: 06 January 2025
- Revised: 08 November 2025
- Accepted: 04 February 2026
- Published online: 30 April 2026
Abstract: Service composition à la Roman model consists of realizing a virtual service by suitably orchestrating a set of already available services. In this paper, we consider a variant where available services are stochastic systems, and the target specification is goal-oriented and specified in Linear Temporal Logic on finite traces (ʟᴛʟf). In this setting, we are interested in synthesizing a controller (policy) that maximizes the probability of satisfying the temporal logic objective (either reachability or safety) while minimizing the expected cost of using the available services. To do so, we combine techniques from ʟᴛʟf synthesis, service composition à la Roman Model, and bi-objective lexicographic optimization on Markov Decision Processes (MDPs). This framework has several interesting applications, including Smart Manufacturing and Digital Twins.
-
Key words:
- Service composition /
- Linear temporal logic on finite traces /
- MDPs