









-
Despite great progress in artificial intelligence, e.g., OpenAI's o1 and o3, DeepSeek-V3, and Alibaba's QwQ, solving reasoning tasks − particularly multi-step complex reasoning problems − remains a fundamental challenge due to high costs, proprietary nature, and complex architectures[1]. Multi-step reasoning refers to the ability of AI systems to make logical connections between different pieces of context or different sources of information. Multi-step reasoning moves toward more human-like understanding and decision-making for AI systems. Its ability to interact with context, combine different information sources, and make logical connections is essential for artificial general intelligence (AGI)[2]. AGI is the new frontier in artificial intelligence, where the aim is to create human-like cognitive abilities. Recently, OpenAI announced the Deep Research AI system, which combines advanced multi-step reasoning capabilities with extensive internet search and synthesis functions, marking a significant milestone on the path to AGI[3].
Reinforcement learning (RL) that incorporates multi-step reasoning is widely seen as one of the promising components on the long road toward AGI, though it is not a silver bullet on its own. However, high costs, proprietary nature, scalability, integration of reasoning mechanisms, and complex architectures present great challenges[4−9].
RL is a Markov decision process (MDP) and provides a mathematical formalism for sequential decision-making[10,11]. It is observed that RL can acquire intelligent behaviors automatically. Decision actions are selected by the agent’s optimal policy to maximize the expected cumulative reward. Policy and reward are often approximated by neural networks. However, standard neural network architectures cannot efficiently deal with long-standing problems in RL, including partial observability[12], high-dimensional state and action spaces[13]. Recently, the transformer architecture demonstrated its superior performance. The essential idea behind the transformer architecture is to use a self-attention mechanism to capture long-range relationships within the data. The remarkable feature of the transformer is its excellent scalability. Transformers can be used to learn representations, model transition functions, learn reward functions, and learn policies[14,15].
RL with transformers can perform single reasoning very well. It is also reported that either transformer or RL can perform multi-step reasoning[16,17]. However, very few papers about using RL incorporating transformers for multi-step reasoning have been published.
Reasoning problems such as mathematical operations, coding, and logical reasoning involve a chain of thought, a tree of thought, and a graph of thought. Reason data are tree-like structured data. Embedding tree-like data, from hierarchies to taxonomies, is a well-defined problem for representing graph knowledge. Hyperbolic geometry provides a natural solution for embedding tree-like and hierarchical data, with demonstrated superior performance over Euclidean embeddings[18]. Hypformer, developed last year, is a novel and complete hyperbolic transformer[19]. It includes well-defined modules in hyperbolic space, such as linear transformation layers, LayerNorm layers, activation functions, dropout operations, and addresses the issue of quadratic time complexity of the existing hyperbolic self-attention module. Despite the impressive performance of various hyperbolic transformers, the papers integrating RL with hyperbolic transformers for multi-step reasoning are very limited.
The purpose of this paper is to introduce a novel multi-step reasoning large language model (LLM) with RL incorporating a complete hyperbolic transformer into it. The proposed hyperbolic transformer is designed to encode diverse sequences, such as entities, agents, and stacks of historical information, and to serve as an expressive predictor for the dynamics model. On the other hand, the developed hyperbolic transformers will integrate all subroutines into RL and act as a sequential decision-maker. To facilitate the development of the complete hyperbolic transformer-based RL for multi-step reasoning, applications are outlined in robotics, medicine, multi-step reasoning language modeling, combinatorial optimization, environmental sciences, and hyperparameter optimization. Limitations and challenges for future research are also addressed. This work is intended to stimulate discussions on hyperbolic transformer-based RL for multi-step reasoning, inspire further research, and facilitate the development of RL approaches for real-world applications.
-
Many complex reasoning tasks − from robotic navigation and manipulation to mathematical problem solving and language reasoning − require planning over several sequential decisions. In such settings, the 'credit assignment problem' (i.e., what past actions contributed to current rewards) is acute: a reward might be received only at the end of a long sequence, yet every step in the chain of decisions may be crucial. Standard RL algorithms (such as one-step temporal-difference (TD) methods) can struggle because they update only with information from the immediate next reward. Multi-step reasoning in RL aims to address this by propagating rewards over several steps using the observed value function, thereby providing better learning signals for tasks with delayed or sparse rewards[17].
Major features of multi-step reasoning RL are:
• Delayed reward propagation: When rewards are delayed, multi-step (or n-step) methods allow the agent to use a longer 'lookahead' window so that early decisions are more directly informed by later outcomes.
• Hierarchical structure: Many real-world tasks naturally decompose into sub-tasks. Hierarchical RL (HRL) approaches − using options or subpolicies − can help hierarchically organize multi-step reasoning by assigning higher-level 'goals' that guide lower-level behavior.
• Improved sample efficiency: By aggregating several reward signals before updating the value estimate, multi-step methods help in situations where rewards are sparse.
Methods for multi-step reasoning in RL
-
There are several complementary approaches to enable multi-step reasoning in RL. They can be used for both on- and off-policy learning. All these methods are often described in the simple one-step case, but they can also be extended across multiple time steps.
Merging transformer reasoning with multi-step RL
-
Integrating transformer architectures with RL is an emerging field[10]. The integration of transformer architecture with RL represents a significant advancement in artificial intelligence. An extended framework is introduced that 'plugs in' the reasoning mechanisms of transformer models into an RL formulation for multi-step reasoning. In this framework, the transformer functions not only as a powerful sequence generator (the policy) but also as a mechanism to provide rich, intermediate representations (the 'chain-of-thought') that can serve as states in an MDP. These representations, combined with the transformer’s inherent self-attention and contextual integration, can then be leveraged to guide multi-step RL updates.
Representation learning high-dimensional data in RL
-
Good high-dimensional data representations are critical for efficient RL. They can enhance performance, convergence speed, and policy stability. The data in large reason models often include mathematical and logical symbol data, coding data, and science such as physics, chemistry, and biology data, sensory signals, and vision image data. Of course, data also includes natural language data. In general, data is represented as a sequence of data. The goal of representation learning is to map high-dimensional data to a compact representation for learning RL.
Transformer architecture
-
A transformer consists of the following main components (a list of symbols is summarized in Supplementary Data 1):
Input token embedding and positional encoding:
Each input token
$ {x}_{t}\in {\mathbb{R}}^{In} $ $ {p}_{t} $ $ {x}_{t} $ $ AND\left({x}_{t}\right)={E}{x}_{t}\in {\mathbb{R}}^{d} $ A fixed or learned positional encoding
$ {p}_{t}\in {\mathbb{R}}^{d} $ $ X_t=Ex_t+p_t $ Attention block:
Consider n input token. Define input embedding matrix:
$ X=\left[\begin{array}{c}{X}_{1}^{T}\\ \vdots \\ {X}_{n}^{T}\end{array}\right]\in {\mathbb{R}}^{n\,\times\, d} $ Define query, key, and value matrices:
$ Q\in {\mathbb{R}}^{n\,\times \,{d}_{k}},K\in {\mathbb{R}}^{n\,\times \,{d}_{k}} $ $ V\in {\mathbb{R}}^{n\,\times\, {d}_{v}}: $ $ Q=XW_Q\ ,\; \; K=XW_k\ ,\; \; V=XW_v $ where,
$ {W}_{Q}\in {\mathbb{R}}^{d\,\times \,{d}_{k}},{W}_{k}\in {\mathbb{R}}^{d\,\times \,{d}_{k}} $ $ {W}_{v}\in {\mathbb{R}}^{d\,\times \,{d}_{v}} $ Attention scores are defined as:
$ \mathrm{A}\mathrm{t}\mathrm{t}\mathrm{e}\mathrm{n}\mathrm{t}\mathrm{i}\mathrm{o}\mathrm{n}\left(Q,K,V\right)= \mathrm{s}\mathrm{o}\mathrm{f}\mathrm{t}\mathrm{m}\mathrm{a}\mathrm{x} \left(\frac{Q{K}^{T}}{\sqrt{{d}_{k}}}\right)V $ Multi-head attention combines multiple attention heads:
$ \mathrm{M}\mathrm{u}\mathrm{l}\mathrm{t}\mathrm{i}\mathrm{H}\mathrm{e}\mathrm{a}\mathrm{d}\left(X\right)=\mathrm{C}\mathrm{o}\mathrm{n}\mathrm{c}\mathrm{a}\mathrm{t}\left({\mathrm{H}\mathrm{e}\mathrm{a}\mathrm{d}}_{1},\dots ,{\mathrm{H}\mathrm{e}\mathrm{a}\mathrm{d}}_{h}\right){W}_{O}\in {\mathbb{R}}^{n\,\times\, d} $ where, h is the number of heads,
$ {\mathrm{H}\mathrm{e}\mathrm{a}\mathrm{d}}_{i}=\mathrm{A}\mathrm{t}\mathrm{t}\mathrm{e}\mathrm{n}\mathrm{t}\mathrm{i}\mathrm{o}\mathrm{n}\left(X{W}_{Q}^{i},X{W}_{k}^{i},X{W}_{v}^{i}\right) , {W}_{O}\in {\mathbb{R}}^{h{d}_{v}\,\times\, d} $ LayerNorm:
Layer normalization (usually called LayerNorm) is one of many forms of normalization that can be used to improve training performance in deep neural networks by keeping the values of a hidden layer in a range that facilitates gradient-based training.
Define:
$ \mu_i=\dfrac{1}{n}\mathop\sum\nolimits_{j\,=\,1}^nx_{ji},\sigma_i=\sqrt{\dfrac{\displaystyle\mathop\sum\nolimits_{j\,=\,1}^n\left(x_{ji}-\mu_i\right)^2}{n}},x_i=\left[\begin{array}{c}x_{1i} \\ \vdots \\ x_{ni}\end{array}\right]\; \mathrm{and}\; \hat{x}_i=\dfrac{x_i-\mu_i}{\sigma_i} $ Then, LayerNorm is defined as:
$ \mathrm{L}\mathrm{a}\mathrm{y}\mathrm{e}\mathrm{r}\mathrm{N}\mathrm{o}\mathrm{r}\mathrm{m}\left(x_i\right)=\gamma\hat{x}_i+\beta $ Feed-forward network (FFN):
The feed-forward layer in a transformer architecture is one of the main components and is present in each of the encoder and decoder blocks. Here is a high-level description of its architecture and function.
(1) Position-wise FFNs: Each layer in the encoder and decoder contains a fully connected FFN, which is applied to each position separately and identically.
(2) Linear transformations: The FFN consists of two linear transformations (i.e., fully connected layers) with a Rectified Linear Unit (ReLU) activation in between. This can be described by the equations:
$ \mathrm{F}\mathrm{F}\mathrm{N}\left(x\right)=max\left(0,x{W}_{1}+{b}_{1}\right){W}_{2}+{b}_{2} $ $ {W}_{1}\in {\mathbb{R}}^{{d}_{model}\,\times \,{d}_{f}},{W}_{2}\in {\mathbb{R}}^{{d}_{f}\,\times\,{d}_{model}} $ $ {b}_{1}\in {\mathbb{R}}^{{d}_{f}},{b}_{2}\in $ $ {\mathbb{R}}^{{d}_{model}} $ Now describing how to complete attention blocks. The input representations are processed through L layers. Each layer l includes multi-head self-attention and an FFN with residual connections and layer normalization. A simplified update at layer l is given by:
$ \tilde{Z}^{\left(l\right)}=\mathrm{L}\mathrm{a}\mathrm{y}\mathrm{e}\mathrm{r}\mathrm{N}\mathrm{o}\mathrm{r}\mathrm{m}\left(Z^{\left(l-1\right)}+\mathrm{M}\mathrm{u}\mathrm{l}\mathrm{t}\mathrm{i}\mathrm{H}\mathrm{e}\mathrm{a}\mathrm{d}\left(Z^{\left(l-1\right)}\right)\right) $ $ Z^{\left(l\right)}=\tilde{Z}^{\left(l\right)}+FFN\left(\tilde{Z}^{\left(l\right)}\right),l=1,2,\dots,L,\; \mathrm{where}\; Z^{\left(0\right)}=X $ Final state representation:
The output of the final layer is then used as the state: st = Z(L). In the RL framework, the sequence {s1, s2, ..., sn} represents the agent’s trajectory (its chain-of-thought), where each st encapsulates the contextual information accumulated up to time t. These states can then be used by the RL algorithm (e.g., to compute Q-values or to determine the next action).
Converting Euclidean transformer to a hyperbolic transformer for general representation
-
Hyperbolic geometry has demonstrated that it can provide a powerful tool in modeling complex structured data, particularly reasoning data with underlying treelike and hierarchical structures[14,19−22]. Tree-like and hierarchical structures underlie human cognitive processes, making hyperbolic geometry modelling an intuitive approach to data representation. Despite the growing interest in hyperbolic representation, exploration of the transformer − a mathematical foundation in artificial intelligence model − within hyperbolic space remains limited. This section introduces an efficient and complete hyperbolic transformer involving hyperbolic transformation with curvatures and hyperbolic readjustment and refinement with curvatures. The key idea of the hyperbolic transformer is to take the Euclidean output
$ {Z}_{t}^{\left(L\right)} $ Notation and setup
-
Before introducing procedures for hyperbolic transformers, the notations and basic setup are presented. The Poincaré ball
$ {\mathbb{D}}^{d}=\left\{x\in {\mathbb{R}}^{d}:\| x\| < 1\right\} $ Key maps:
Exponential map
$ {exp}_{0}\left(\cdot \right) $ $ {\mathbb{D}}^{d} $ Logarithmic map
$ {\mathrm{log}}_{0}\left(\cdot \right) $ $ {\mathbb{D}}^{d} $ Möbius addition
$ {\oplus} $ $ {\mathbb{D}}^{d} $ $ \lambda {\otimes}x $ Also relied on are
$ < \cdot , > $ Exponential map to the Poincaré ball
-
The first step is to map a Euclidean vector to the Poincaré ball. Given a Euclidean vector
$ v\in {\mathbb{R}}^{d} $ $ {Z}_{t}^{\left(L\right)} $ $ v $ $ {D}^{d}=\left\{x\in {\mathbb{R}}^{d},\| x\| < 1\right\} $ $ \varnothing \left(v\right) $ $ \varnothing \left(v\right)={Exp}_{0}\left(v\right)=\mathrm{tanh}\left(\| v\| \right)\dfrac{v}{\| v\| } , \;{\mathrm{for}}\; v\ne 0, \varnothing \left(0\right)=0 $ (1) Therefore, the hyperbolic state is defined as
$ \tilde{s}_t=\varnothing\left(Z_t^{\left(L\right)}\right)\in D^d $ (2) Hyperbolic versions of basic operations
-
Once in hyperbolic space, standard operations are replaced by their Möbius analogues.
Möbius addition:
Similar to addition in Euclidean space, for two points
$ x,y\in {D}^{d} $ $ x{\oplus}y=\dfrac{\left(1+2 \lt x,y \gt +{\| y\| }^{2}\right)x+\left(1-{\| x\| }^{2}\right)y}{1+2 \lt x,y \gt +{\| x\| }^{2}{\| y\| }^{2}} $ (3) Möbius scalar multiplication:
Now the Möbius scalar multiplication in hyperbolic space is introduced.
For a scalar
$ \lambda \in \mathbb{R} $ $ x\in {D}^{d} $ $ \lambda {\otimes}\mathrm{x}=\mathrm{tanh}\left(\lambda {\mathrm{t}\mathrm{a}\mathrm{n}\mathrm{h}}^{-1}\left(\| x\| \right)\right)\dfrac{x}{\| x\| } , \;{\mathrm{for}}\; x\ne 0,\lambda {\otimes}0=0 $ (4) Hyperbolic linear transformation:
A hyperbolic linear transformation is defined as follows. It is typically implemented by mapping the hyperbolic point back to the tangent space at the origin via the logarithmic map, applying a Euclidean linear transformation, then mapping back.
Logarithmic map
$ {\mathrm{log}}_{0}\left(x\right)={\mathrm{t}\mathrm{a}\mathrm{n}\mathrm{h}}^{-1}\left(\| x\| \right)\dfrac{x}{\| x\| } $ (5) Transformation:
$ y=\mathrm{W}{\mathrm{log}}_{0}\left(x\right)+b $ Exponential map back:
$ f\left(x\right)={Exp}_{0}\left(\| y\| \right)=\mathrm{tanh}\left(\| y\| \right)\dfrac{y}{\| y\| } $ Combining the above three steps, the hyperbolic linear transformation is obtained:
$ f\left(x\right)=Exp_0\left(W\mathrm{log}_0\left(x\right)+b\right) $ Converting the input embedding
-
The procedure begins with an input Euclidean embedding and is then extended to an input hyperbolic embedding. In a standard transformer, an input token xt (an integer index in {1, ..., V} is mapped to a Euclidean embedding vector
$ {e}_{t}\in {\mathbb{R}}^{d} $ $ {\mathbb{D}}^{d} $ Euclidean embedding (lookup):
$ {e}_{t}={x}_{t}E,{e}_{t}\in {\mathbb{R}}^{d} $ Positional encoding (optional): Let
$ {p}_{t}\in {\mathbb{R}}^{d} $ Exponential map: To get a hyperbolic point
$ {\tilde{u}}_{t}\in {\mathbb{D}}^{d} $ $ {\tilde{u}}_{t}={exp}_{0}\left({u}_{t}\right)=\mathrm{tanh}\left(\| {u}_{t}\| \right)\dfrac{{u}_{t}}{\| {u}_{t}\| } $ $ {u}_{t}\ne 0 $ $ {u}_{t}=0 $ $ {exp}_{0}\left({u}_{t}\right)=0 $ Thus, combining the above three steps leads to each token’s hyperbolic embedding:
$ \tilde{u}_t=exp_0\left(e_t+p_t\right) $ Converting LayerNorm
-
A standard LayerNorm in Euclidean space for a vector
$ z\in {\mathbb{R}}^{d} $ $ \mathrm{L}\mathrm{a}\mathrm{y}\mathrm{e}\mathrm{r}\mathrm{N}\mathrm{o}\mathrm{r}\mathrm{m}\left(z\right)=\dfrac{z-\mu}{\sigma}\odot\mathrm{\gamma}+\mathrm{\beta} $ (6) where,
$ \mu =\dfrac{1}{d}{\displaystyle\sum }_{i=1}^{d}{z}_{i},\sigma =\sqrt{\dfrac{{\displaystyle\sum }_{i=1}^{d}{\left({z}_{i}-\mu \right)}^{2}}{d}} $ In hyperbolic space, the lack of a straightforward linear structure makes standard layer normalization (i.e., subtracting the mean and dividing by the standard deviation in a component-wise manner) valid. Therefore, in hyperbolic space, this cannot be directly done as
$ \dfrac{z-\mu }{\sigma } $ Therefore, let
$ \tilde{z}={\tilde{u}}_{t} $ $ \hat{z}=\mathrm{H}\mathrm{L}\mathrm{a}\mathrm{y}\mathrm{e}\mathrm{r}\mathrm{N}\mathrm{o}\mathrm{r}\mathrm{m}\left(\tilde{z}\right)={exp}_{0}\left(\dfrac{y-{\mu }_{y}}{{\sigma }_{y}}{\odot}\gamma +\beta \right) $ where,
$ y={\mathrm{log}}_{0}\left(\tilde{z}\right),\;{\mu }_{y}, {\sigma }_{y} $ Converting multi-head attention
-
The conversion of multi-head attention from Euclidean space to hyperbolic space is now considered. In hyperbolic space, multi-head attention consists of five steps:
Map tokens to tangent space:
In order to perform attention steps in Euclidean space, log0 is first used to map each hyperbolic token
$ {\tilde{z}}_{t}^{\left(l-1\right)}\in {\mathbb{D}}^{d} $ $ {z}_{t}^{\left(l-1\right)}={\mathrm{log}}_{0}\left({\tilde{z}}_{t}^{\left(l-1\right)}\right)\in {\mathbb{R}}^{d} $ Compute queries, keys, and values in tangent space:
$ {Q}_{i}={W}_{i}^{Q}{z}_{t}^{\left(l-1\right)}\in {\mathbb{R}}^{{d}_{v}},{K}_{i}={W}_{i}^{K}{z}_{t}^{\left(l-1\right)}\in {\mathbb{R}}^{{d}_{v}},{V}_{i}={W}_{i}^{V}{z}_{t}^{\left(l-1\right)}\in {\mathbb{R}}^{{d}_{v}} $ where, the weight matrices
$ {W}_{i}^{Q},{W}_{i}^{K},{W}_{i}^{V}\in {\mathbb{R}}^{{d}_{v}\times d} $ Compute attention scores:
$ A_{ij}=\dfrac{ \lt Q_i,K_j \gt }{\sqrt{d}}\to{\mathrm{s}\mathrm{o}\mathrm{f}\mathrm{t}\mathrm{m}\mathrm{a}\mathrm{x}}\left(A_{ij}\right)=\dfrac{exp\left(A_{ij}\right)}{{\displaystyle\sum}_{j'}exp\left(A_{ij'}\right)},\ \ \ \ \ \ \ \ i=1,\dots,h $ This step is identical to the Euclidean dot-product attention, except that it is performed in the tangent space.
Aggregate values:
The standard attention output in tangent space is
$ {{head}_{i}=\mathrm{A}\mathrm{t}\mathrm{t}\mathrm{n}}_{i}\left({Q}_{i},{K}_{i},{V}_{i}\right)={\sum }_{j}{\alpha }_{ij}{V}_{j}\in $ $ {\mathbb{R}}^{{d}_{v}}, i=1, \dots, h $ $ A=\mathrm{M}\mathrm{u}\mathrm{l}\mathrm{t}\mathrm{i}\mathrm{H}\mathrm{e}\mathrm{a}\mathrm{d}\left({\tilde{z}}_{t}^{\left(l-1\right)}\right)={W}_{o}\left[\begin{array}{c}{head}_{1}\\ \vdots \\ {head}_{h}\end{array}\right]\in {\mathbb{R}}^{d} ,\; {\rm{where}}\; {W}_{O}\in {\mathbb{R}}^{d\,\times\, h{d}_{v}} $ Map back to hyperbolic space:
Finally, there's a need to map
$ A $ $ {\left(mz\right)}_{t}^{\left(l-1\right)}=\mathrm{H}\mathrm{M}\mathrm{u}\mathrm{l}\mathrm{t}\mathrm{i}\mathrm{H}\mathrm{e}\mathrm{a}\mathrm{d}\mathrm{A}\mathrm{t}\mathrm{t}\mathrm{e}\mathrm{n}\left({\tilde{z}}_{t}^{\left(l-1\right)}\right)={exp}_{0}\left(A\right)\in {\mathbb{D}}^{d} $ Converting the FFN
-
Recall that a standard feed-forward sub-layer in Euclidean space has the form:
$ \mathrm{F}\mathrm{F}\mathrm{N}\left(z\right)={W}_{2}\sigma \left({W}_{1}z+{b}_{1}\right)+{b}_{2} $ The hyperbolic FNN, which consists of three steps, which are combined to obtain the hyperbolic feed-forward layer:
$ z_t^{\left(l\right)}=\mathrm{ }\mathrm{H}\mathrm{F}\mathrm{F}\mathrm{N}\left(\left(zf\right)_t^{\left(l-1\right)}\right)=exp_0\left(W_2\sigma\left(W_1\mathrm{log}_0\left(\left(zf\right)_t^{\left(l-1\right)}\right)+b_1\right)+b_2\right) $ Hyperbolic residual & LayerNorm
-
$ {\left(zf\right)}_{t}^{\left(l-1\right)} $ $ \left({\tilde{z}}_{t}^{\left(l-1\right)}\right)= $ $ \left({\tilde{z}}_{t}^{\left(l-1\right)}\right){\oplus}\mathrm{H}\mathrm{M}\mathrm{u}\mathrm{l}\mathrm{t}\mathrm{i}\mathrm{H}\mathrm{e}\mathrm{a}\mathrm{d}\mathrm{A}\mathrm{t}\mathrm{t}\mathrm{e}\mathrm{n}\left({\tilde{z}}_{t}^{\left(l-1\right)}\right), $ (or do log0-based approach for a more stable approach):
First map to tangent space, then add them in the Euclidean space, finally map it back to hyperbolic space.
$ \mathrm{H}\mathrm{M}\mathrm{l}\mathrm{o}\mathrm{g}\left(\tilde{z}_t^{\left(l-1\right)}\right)=\mathrm{log}_0\left(\mathrm{H}\mathrm{M}\mathrm{u}\mathrm{l}\mathrm{t}\mathrm{i}\mathrm{H}\mathrm{e}\mathrm{a}\mathrm{d}\mathrm{A}\mathrm{t}\mathrm{t}\mathrm{e}\mathrm{n}\left(\tilde{z}_t^{\left(l-1\right)}\right)\right)+\tilde{z}_t^{\left(l-1\right)} $ $ \mathrm{HMexp}\left(\tilde{z}_t^{\left(l-1\right)}\right)=exp_0\left(\mathrm{H}\mathrm{M}\mathrm{l}\mathrm{o}\mathrm{g}\left(\tilde{z}_t^{\left(l-1\right)}\right)\right) $ Apply HLayerNorm:
$ \left(zf\right)_t^{\left(l-1\right)}=\mathrm{H}\mathrm{L}\left(\mathrm{H}\mathrm{M}\mathrm{e}\mathrm{x}\mathrm{p}\left(\tilde{z}_t^{\left(l-1\right)}\right)\right)=\mathrm{H}\mathrm{L}\mathrm{a}\mathrm{y}\mathrm{e}\mathrm{r}\mathrm{N}\mathrm{o}\mathrm{r}\mathrm{m}\left(\mathrm{H}\mathrm{M}\mathrm{e}\mathrm{x}\mathrm{p}\left(\tilde{z}_t^{\left(l-1\right)}\right)\right) $ All steps in the hyperbolic transformer encoder block are summarized in Fig. 1.
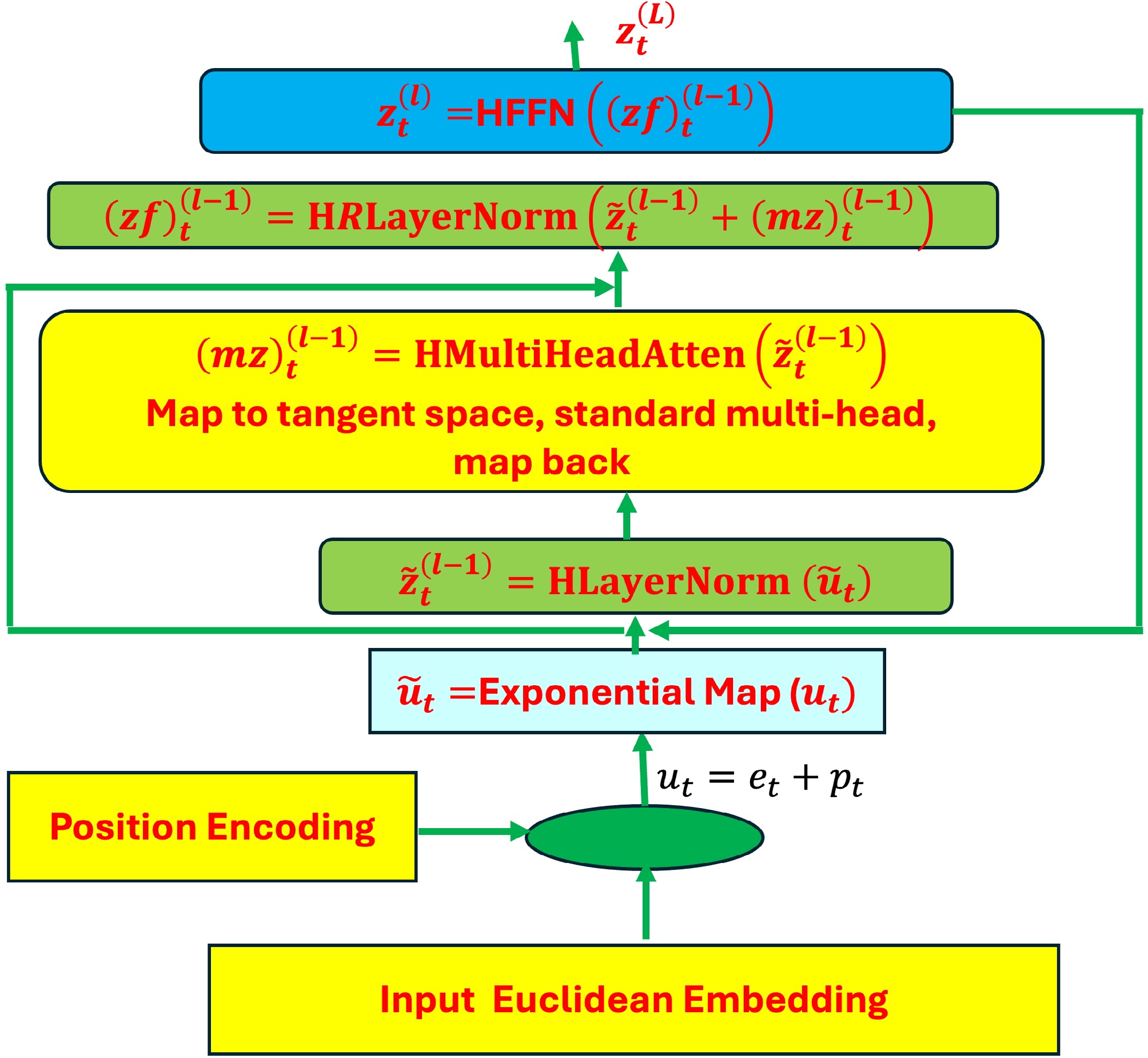
Figure 1.
Architecture of hyperbolic transformers. All steps: input Euclidean embedding, position encoding, hyperbolic layer normalization, hyperbolic multi-head attention, and hyperbolic feed-forward neural networks in the hyperbolic transformer encoder block.
Hyperbolic (Poincaré ball) transformer for transition function
-
A hyperbolic transformer can be employed to learn the dynamics of the environment by modeling the transition function in RL, which describes how the environment transitions from the current state s to the next state s' and issues rewards r in response to the actions a taken by the agent (Fig. 2)[10].

Figure 2.
Transition function learning. A hyperbolic transformer is employed to learn the dynamics of the environment by modeling the transition function in RL, which describes how the environment transitions from the current state s to the next state s' and issues rewards r in response to the actions taken by the agent.
Hyperbolic transformer architecture
-
Hyperbolic transformer (Fig. 1) consists of hyperbolic input embedding, hyperbolic transformer for transition function, multi-head attention, and layernorm in hyperbolic, hyperbolic residual connection, and hyperbolic feed-forward neural networks.
Input Embedding (Hyperbolic)
-
Hyperbolic input embedding consists of two major steps. The first step is to embed state and action variables in Euclidean space. Then, convert them to hyperbolic space. Total input data, denoted by
$ \left({s}_{i,}{a}_{i},{r}_{i},{s}_{i}^{{'}}\right),i=1, \dots ,N, $ State embedding
$ {e}_{s}={E}_{s}\left(s\right)={W}_{s}s+{b}_{s}\in {\mathbb{R}}^{d} $ $ {s}_{i},i=1, \dots ,N $ $ {e}_{i}={E}_{s}\left({s}_{i}\right)\in {\mathbb{R}}^{d} $ Action embedding
Like the state, an embedding for the action is defined:
$ {e}_{a}={E}_{a}\left(a\right)={W}_{a}a+{b}_{a}\in {\mathbb{R}}^{d} $ Positional encodings (optional)
In some cases, (s, a) is a short sequence [s, a] which can be assigned with positional vectors ps and pa. Adding positional encodings to the state and action embedding yields
$ u_s=e_s+p_s,u_a=e_a+p_a $ Mapping to the Poincaré ball
At the second step, the Euclidean embedding is mapped at the first step to the hyperbolic space. At the origin, the exponential map is used to map the embeddings in the Euclidean space to the Poincaré ball:
$ \tilde{u}_s=exp_0\left(u_s\right),\tilde{u}_a=exp_0\left(u_a\right) $ Thus,
$ {\tilde{u}}_{s},{\tilde{u}}_{a}\in {\mathbb{D}}^{d} $ $ {\tilde{u}}^{\left(0\right)}=\left[{\tilde{u}}_{s},{\tilde{u}}_{a}\right] $ $ \tilde{X}=\left[\begin{array}{cc}{\tilde{u}}_{{s}_{1}}& {\tilde{u}}_{{a}_{1}}\\ \begin{array}{c} \vdots \\ {\tilde{u}}_{{s}_{N}}\end{array}& \begin{array}{c} \vdots \\ {\tilde{u}}_{{a}_{N}}\end{array}\end{array}\right]\in {\mathbb{D}}^{N\,\times\, \left(2d\right)} $ Full architecture: hyperbolic transformer for transition function
-
A short sequence
$ \tilde{X} $ The full structure of the hyperbolic transformer for the transition function is summarized as follows. A sort of sequence from the state and action embeddings is
$ \tilde{X}=\left[{\tilde{u}}_{s},{\tilde{u}}_{a}\right] $ $ {\tilde{x}}^{\left(l\right)} $ $ {\tilde{X}}^{\left(L\right)}=\left[{\tilde{X}}_{s}^{\left(L\right)},{\tilde{X}}_{a}^{\left(L\right)}\right] $ $ \tilde{h}\in {\mathbb{D}}^{2d} $ Finally, the output
$ \tilde{h} $ $ p({s}^{{'}},r|s,a) $ $ \hat{s{'}} $ $ \hat{r} $ $ h={\mathrm{log}}_{0}\left(\tilde{h}\right)\in {\mathbb{R}}^{2d} $ $ \hat{s{'}}={W}_{s}h+{b}_{s},\hat{r}={W}_{r}h+{b}_{r} . $ Hence, the final function is
$ \left(\hat{s{'}},\hat{r}\right)=f(s,a) $ Group relative policy optimization (GRPO) incorporating hyperbolic transformer
-
In this section, the following will be investigated:
Multi-head latent attention (MLA): A specialized attention mechanism that processes latent variables or additional context in multi-head format.
DeepSeekMoE: A mixture of experts (MoE) layer integrated into transformers to handle specialized sub-tasks or to route tokens to different experts.
Hyperbolic geometry: The Poincaré ball model
$ {\mathbb{D}}^{d} $ GRPO: A variant of policy gradient that uses group-based policy updates.
Firstly, how to adapt MLA and DeepSeekMoE to hyperbolic geometry is outlined, and then how to embed the resulting hyperbolic transformer as a policy in GRPO.
Background: MLA and DeepSeekMoE in Euclidean space
MLA
-
The MLA and MoE are briefly introduced here. Interested readers refer to references cited here[6,23]. MLA utilizes low-rank matrices in the key-value layers and enables the caching of compressed latent key value (KV) states to address the communication bottlenecks in LLM[6,23]. This design significantly reduces the KV cache size compared to traditional multi-head attention, thus accelerating inference. MLA also incorporates an up-projection matrix to enhance expressiveness. MLA is developed to speed up inference speed in autoregressive text generation.
Let the input sequence be
$ X\in {\mathbb{R}}^{T\,\times \,d} $ $ {h}_{t}\in {\mathbb{R}}^{d} $ Standard multi-head attention
Project ht to queries, keys, and values.
Let
$ {q}_{t},{k}_{t},{v}_{t}\in {\mathbb{R}}^{{n}_{h\,\times\, }{d}_{h}} $ $ q_t=W^Qh_t $ (7) $ k_t=W^Kh_t $ (8) $ v_t=W^Vh_t $ (9) Then, the vectors qt, kt, vt are split into nh heads in the MHA computations:
$ q_t=\left[q_{t,1};\dots;q_{t,n_h}\right] $ (10) $ k_t=\left[k_{t,1};\dots;k_{t,n_h}\right] $ (11) $ v_t=\left[v_{t,1};\dots;v_{t,n_h}\right] $ (12) $ {o}_{t,i}={\sum }_{j=1}^{{n}_{h}}{\mathrm{s}\mathrm{o}\mathrm{f}\mathrm{t}\mathrm{m}\mathrm{a}\mathrm{x}}_{j}\left(\dfrac{{q}_{t,i}^{T}{k}_{t,j}}{\sqrt{{d}_{h}}}\right){v}_{t,j}\in {\mathbb{R}}^{{d}_{h}} $ (13) $ u_t=W^O\left[o_{t,1};\dots;o_{t,n_h}\right] $ (14) where
$ {q}_{t,i},{k}_{t,i},{v}_{t,i}\in {\mathbb{R}}^{{d}_{h}} $ $ {W}^{O}\in {\mathbb{R}}^{d\times {n}_{h}{d}_{h}} $ In computation, during inference, all keys and values need to be cached to accelerate inference, so MHA must cache 2nhdhL elements for each token.
Low-rank key-value joint compression
-
The low-rank joint compression for keys and values is given by
$ {c}_{t}^{KV}={W}^{DKV}{h}_{t}\in {\mathbb{R}}^{{d}_{c}} , $ (15) $ {k}_{t}^{C}={W}^{UK}{c}_{t}^{KV}\in {\mathbb{R}}^{{n}_{h}{d}_{h}} $ (16) $ {v}_{t}^{C}={W}^{UV}{c}_{t}^{KV}\in {\mathbb{R}}^{{n}_{h}{d}_{h}} $ (17) where,
$ {C}_{t}^{KV} $ $ {d}_{c}\left(\ll {n}_{h}{d}_{h}\right) $ $ {W}^{UK},{W}^{UV}\in {\mathbb{R}}^{{n}_{h}{d}_{h}\times {d}_{c}} $ $ {C}_{t}^{KV} $ $ c_t^Q=W^{DQ}h_t $ (18) $ q_t^c=W^{UQ}c_t^Q $ (19) where,
$ {c}_{t}^{Q}\in {\mathbb{R}}^{{d}_{c}^{{'}}} $ $ {d}_{c}^{{'}}\left(\ll {n}_{h}{d}_{h}\right) $ $ {W}^{DQ}\in {\mathbb{R}}^{{d}_{c}^{{'}}\,\times \,d} $ ${W}^{UQ}\in {\mathbb{R}}^{{{n}_{h}{d}_{h}\,\times \,d}_{c}^{{'}}} $ Rotary positional embeddings (RoPE)[24] encodes the absolute position with a rotation matrix and meanwhile incorporates the explicit relative position dependency in self-attention formulation. RoPE enhances the performance of the transformer. However, RoPE is incompatible with low-rank KV compression. To overcome this limitation, DeepSeek developed methods to decouple the RoPE as follows. Let
$ {q}_{t,i}^{R}\in {\mathbb{R}}^{{d}_{h}^{R}} $ $ {k}_{t}^{R} $ $ {d}_{h}^{R} $ $ {W}^{QR}\in {\mathbb{R}}^{{n}_{h}{d}_{h}^{R}\,\times\, {d}_{c}^{{'}}} $ $ {W}^{KR}\in {\mathbb{R}}^{{{n}_{h}d}_{h}^{R}\,\times \,d} $ $ \left[q_{t,1}^R;\dots;q_{t,n_h}^R\right]=RoPE\left(W^{QR}c_t^Q\right) $ (20) $ k_t^R=RoPE\left(W^{KR}h_t\right) $ (21) $ q_{t,i}=\left[q_{t,i}^C;q_{t,i}^R\right] $ (22) $ k_{t,i}=\left[k_{t,i}^C;k_t^R\right] $ (23) $ o_{t,i}={\sum}_{j=1}^{n_h}\mathrm{s}\mathrm{o}\mathrm{f}\mathrm{t}\mathrm{m}\mathrm{a}\mathrm{x}_{\mathrm{j}}\left(\dfrac{q_{t,i}^Tk_{t,j}}{\sqrt{d_h+d_h^R}}\right)v_{t,j}^C $ (24) $ {u}_{t}={W}^{O}\left({o}_{t,1};\dots ;{o}_{t,{n}_{h}}\right) $ (25a) Since during inference, the decoupled key should also be cached, the total number of KV cache elements are
$ \left({d}_{c}+{d}_{h}^{R}\right)L $ Integrates mixture of experts (MoE) with MLA
-
A novel language model architecture that integrates MoE with an MLA mechanism and RMSNorm to achieve unprecedented scalability and inference efficiency[25,26]. The MoE has two main components, namely experts and the router:
• Experts − each FNN layer now has a set of 'experts' which are subsets in the FNN.
• Router or gate network − the router determines how input tokens’ information passes experts.
It replaces FFN in the transformer. The architecture of MoE is shown in Fig. 3. The MoE only activates a subset of experts at a given time. Now the DeepSeek MoE algorithm is introduced.
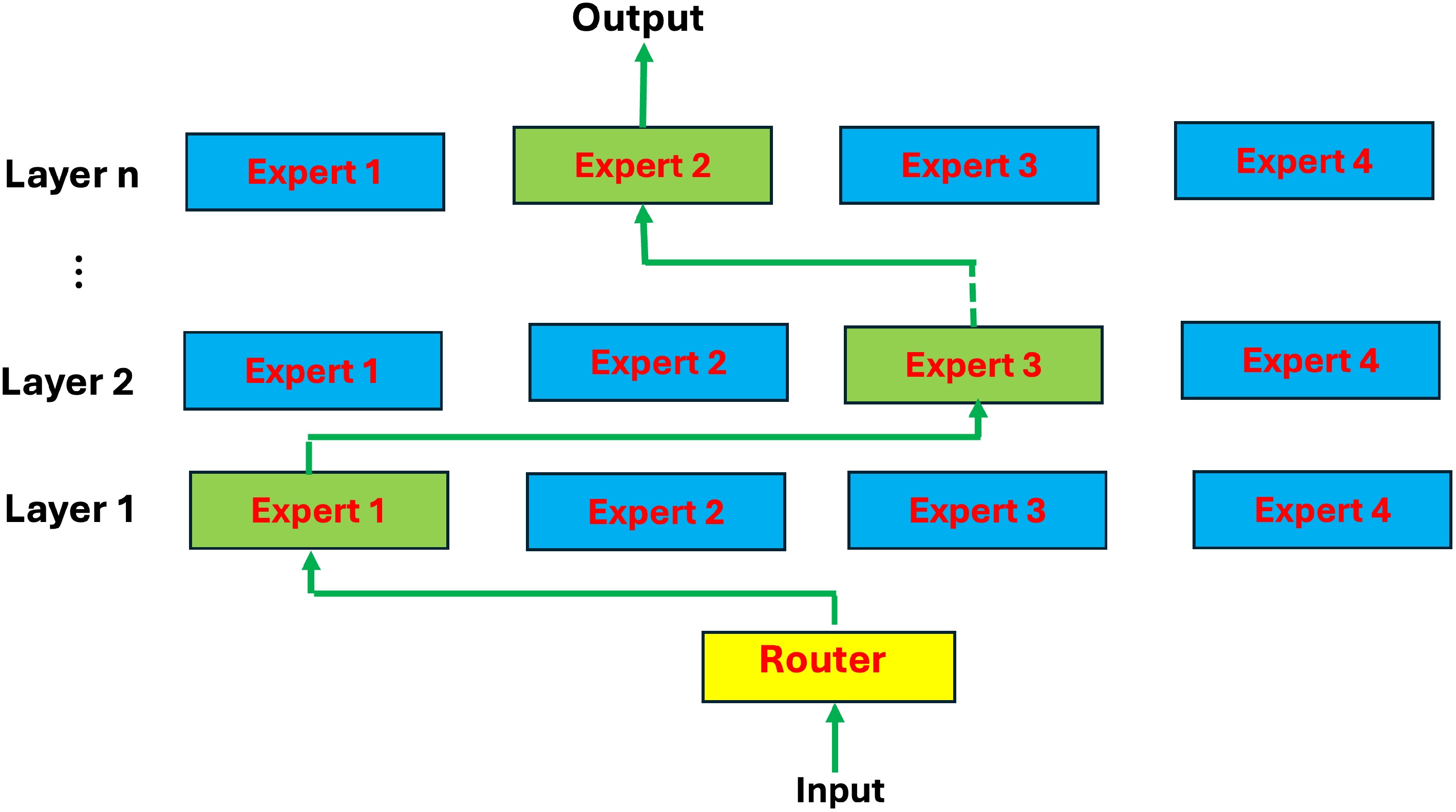
Figure 3.
Outline of MoE. The MoE has two main components, namely experts and the router: experts − each FNN layer now has a set of 'experts' which are subsets in the FNN. Router or gate network − the router determines how input tokens’ information passes experts. The MoE replaces FFN in the transformer.
Basic architecture
-
Consider the lth layer. Let
$ {u}_{t}^{l} $ $ {\mathrm{F}\mathrm{F}\mathrm{N}}_{i}^{\left(s\right)}\left(\cdot \right) $ $ {\mathrm{F}\mathrm{F}\mathrm{N}}_{i}^{\left(r\right)}\left(\cdot \right) $ $ {h}_{t}^{\left(l\right)} $ $ {h}_{t}^{l}={u}_{t}^{l}+{\sum }_{i=1}^{{N}_{s}}{\mathrm{F}\mathrm{F}\mathrm{N}}_{i}^{\left(s\right)}\left({u}_{t}^{l}\right)+{\sum }_{i=1}^{{N}_{r}}{g}_{i,t}{\mathrm{F}\mathrm{F}\mathrm{N}}_{i}^{\left(r\right)}\left({u}_{t}^{l}\right) $ (25b) $ {g}_{i,t}=\left\{\begin{array}{cc}{s}_{i,t}& {s}_{i,t}\in \mathrm{T}\mathrm{o}\mathrm{p}\mathrm{K}\left(\left\{{s}_{j,t}|1\le j\le {N}_{r}\right\},{k}_{r}\right)\\ 0& \mathrm{o}\mathrm{t}\mathrm{h}\mathrm{e}\mathrm{r}\mathrm{w}\mathrm{i}\mathrm{s}\mathrm{e}\end{array}\right. $ (26) $ s_{i,t}=\mathrm{s}\mathrm{o}\mathrm{f}\mathrm{t}\mathrm{m}\mathrm{a}\mathrm{x}\left(\left(u_t^l\right)^Te_i\right) $ (27) where kr denotes the number of activated routed experts; gi,t is the gate value for the ith expert; si,t is the token to expert affinity; ei is the centroid of the ith routed expert in this layer; and Topk(·, K) denotes the set comprising K highest scores among the affinity scores calculated for the ith token and all routed experts.
Equation (26) implies that the hidden vector output of token t at layer l always uses all the shared experts (denoted by the first summation in the equation) and always includes the residual (denoted by the first term). The last term, representing the routing experts, includes a gating factor that controls which experts are turned on for any specific token. Using gating factor not only eliminates most of the possible experts (thereby greatly reducing the number of active parameters), but also weights the final output based on how close each chosen routing expert is to the token.
Finally, load imbalance in MoE can also lead to poor performance and poor generalization, as the underloaded experts didn’t get enough training tokens to learn meaningful knowledge. To overcome this limitation, the auxiliary loss for load balance is introduced.
Auxiliary loss for load balance
-
During the training, three kinds of auxiliary losses for controlling expert-level load balance
$({\mathcal{L}}_{\mathrm{E}\mathrm{x}\mathrm{p}\mathrm{B}\mathrm{a}\mathrm{l}}) $ $ \left({\mathcal{L}}_{\mathrm{D}\mathrm{e}\mathrm{v}\mathrm{B}\mathrm{a}\mathrm{l}}\right) $ $ \left({\mathcal{L}}_{\mathrm{C}\mathrm{o}\mathrm{m}\mathrm{m}\mathrm{B}\mathrm{a}\mathrm{l}}\right) $ • Expert-level balance loss
A common strategy to improve load-balancing is to introduce auxiliary loss functions:
$ {\mathcal{L}}_{\mathrm{E}\mathrm{x}\mathrm{p}\mathrm{B}\mathrm{a}\mathrm{l}}={\alpha }_{1}{\sum }_{i=1}^{{N}_{r}}{f}_{i}{p}_{i} $ $ {f}_{i}=\dfrac{{N}_{r}}{{K}_{r}T}{\sum }_{t=1}^{T}1\left(\mathrm{T}\mathrm{o}\mathrm{k}\mathrm{e}\mathrm{n}\;t\;\mathrm{S}\mathrm{e}\mathrm{l}\mathrm{e}\mathrm{c}\mathrm{t}\mathrm{s}\;\mathrm{E}\mathrm{x}\mathrm{p}\mathrm{e}\mathrm{r}\mathrm{t}\;{i}\right) $ $ {p}_{i}=\dfrac{1}{T}{\sum }_{t=1}^{T}{s}_{i,t} $ where, α1: a hyper-parameter called expert-level balance factor; fi: fraction of token rooted to the ith expert; pi: average probability of selecting the ith expert for the entire input sequence.
• Device-level balance loss
In addition to the expert-level balance loss, the DeepSeek MoE additionally introduces a device-level balance loss to ensure balanced computation across different devices. In the training process, they partition all routed experts into D groups
$ \left\{{\epsilon }_{1}, \dots ,{\epsilon }_{D}\right\} $ $ {\mathcal{L}}_{\mathrm{D}\mathrm{e}\mathrm{v}\mathrm{B}\mathrm{a}\mathrm{l}}={\alpha }_{2}{\sum }_{i=1}^{D}{f}_{i}^{{'}}{p}_{i}^{{'}} $ $ {f}_{i}^{{'}}=\dfrac{1}{\left|{\epsilon }_{i}\right|}{\sum }_{j\in {\epsilon }_{i}}{f}_{j} $ $ {p}_{i}^{{'}}={\sum }_{j\in {\epsilon }_{i}}{p}_{j} $ where, α2 is a hyper-parameter called device-level balance factor.
• Communication balance loss
Finally, a communication balance loss to ensure that the communication of each device is balanced is introduced.
$ {\mathcal{L}}_{\mathrm{C}\mathrm{o}\mathrm{m}\mathrm{m}\mathrm{B}\mathrm{a}\mathrm{l}}={\alpha }_{3}{\sum }_{i=1}^{D}{f}_{i}^{{'}}{'}{p}_{i}^{{'}}{'} $ $ f_i^{\text{'}\text{'}}=\dfrac{D}{MT}{\sum}_{t=1}^T1\left(\mathrm{T}\mathrm{o}\mathrm{k}\mathrm{e}\mathrm{n}\; t\; \mathrm{i}\mathrm{s}\mathrm{ }\mathrm{s}\mathrm{e}\mathrm{n}\mathrm{t}\; \mathrm{t}\mathrm{o}\; \mathrm{D}\mathrm{e}\mathrm{v}\mathrm{i}\mathrm{c}\mathrm{e}\; i\right) $ $ {p''_{i}}={\sum }_{j\in {\epsilon }_{i}}{p}_{j} $ Converting MLA and DeepSeekMoE to hyperbolic space
-
The adaptation of each component in MLA and DeepSeekMoE is described so that the internal computations remain consistent with Poincaré ball geometry.
Hyperbolic MLA
-
In the hyperbolic version of MLA, it yields the following components:
Input
Input includes a set of hyperbolic token embeddings
$ {\tilde{z}}_{i}\in {D}^{d} $ $ {\tilde{l}}_{j}\in {D}^{d} $ Logarithmic map
The goal of this step is to transform all quantities in the Poincaré ball to the tangent space (Euclidean space). For each
$ {\tilde{z}}_{i} $ $ {\tilde{l}}_{j} $ $ z_i=\mathrm{log}_0\left(\tilde{z}_i\right),\ \ \ l_j=\mathrm{log}_0\left(\tilde{l}_j\right) $ Compute queries/keys/values (in tangent space)
Using Eqs (7)−(9) for Euclidean space to compute
$ Q_i=W^Qz_i $ (28) $ K_i=W^Kz_i $ (29) $ V_i=W^Vz_i $ (30) and similarly for the latent embeddings (such as the low-rank joint compression) for queries, keys, and values:
$ Q{_{l_j}}={W_Q^l}{l_j} $ (31) $ K_{l_j}=W_k^ll_j $ (32) $ V_{l_j}=W_V^ll_j $ (33) Attention
Tokens + latent embeddings are combined in the attention (Eqs [15]−[24]). For each i, the corresponding coefficients are computed as:
$ \alpha_{i,x}=\mathrm{s}\mathrm{o}\mathrm{f}\mathrm{t}\mathrm{m}\mathrm{a}\mathrm{x}_x\left(\dfrac{ \lt Q_i,K_x \gt }{\sqrt{d}}\right) $ (34) Summing over
$ x\in \left\{\mathrm{t}\mathrm{o}\mathrm{k}\mathrm{e}\mathrm{n}\mathrm{s}+\mathrm{l}\mathrm{a}\mathrm{t}\mathrm{e}\mathrm{n}\mathrm{t}\;\mathrm{c}\mathrm{o}\mathrm{m}\mathrm{p}\mathrm{r}\mathrm{e}\mathrm{s}\mathrm{s}\mathrm{i}\mathrm{o}\mathrm{n}\mathrm{s},\;\mathrm{i}\mathrm{n}\mathrm{c}\mathrm{l}\mathrm{u}\mathrm{d}\mathrm{i}\mathrm{n}\mathrm{g}\; \mathrm{m}\mathrm{u}\mathrm{l}\mathrm{t}\mathrm{i}{\text{-}} \mathrm{h}\mathrm{e}\mathrm{a}\mathrm{d}\right\} $ $ \hat{v}_i={\sum}_x\alpha_{i,x}V_x $ (35) Map back to the Poincaré ball
$ \tilde{v}_i=exp_0\left(\hat{v}_i\right) $ (36) Hence, MLA in hyperbolic space is basically standard multi-head attention over tokens + latent embeddings in the tangent space, or alternatively performing all computations in the previous sections 'standard multi-head attention' and 'low-rank key-value joint compression', with an exp0 to map the result back into
$ {\mathbb{D}}^{d} $ Hyperbolic DeepSeekMoE
-
Next, the introduction of the mixture-of-experts layer in hyperbolic space:
Router:
For each token
$ {\tilde{z}}_{i}\in {\mathbb{D}}^{d} $ Logarithmic map:
$ {z}_{\mathit{i}}={\mathrm{log}}_{0}\left({\tilde{z}}_{i}\right)\in {\mathbb{R}}^{d} $ A Euclidean router function R introduced in the previous section, which outputs gating weights αi,e for each expert e.
Experts:
Each expert is an FFN. In hyperbolic space, transformations are defined:
$ {\mathrm{E}\mathrm{x}\mathrm{p}\mathrm{e}\mathrm{r}\mathrm{t}}_{i}\left(\tilde{z}\right)={exp}_{0}\left({W}_{e,2}\sigma \left({W}_{e,1}{\mathrm{log}}_{0}\left(\tilde{z}\right)+{b}_{e,1}\right)+{b}_{e,2}\right) $ (37) Combining expert outputs:
Finally, in HFNN, the output is produced for each token:
$ {\tilde{y}}_{i}={{\oplus}}_{e}{\alpha }_{i,e}{\otimes}{\mathrm{E}\mathrm{x}\mathrm{p}\mathrm{e}\mathrm{r}\mathrm{t}}_{e}\left({\tilde{z}}_{i}\right) $ (38) In other words, a Möbius weighted combination of the experts’ outputs is performed, with weights αi,e. Alternatively, one might pick the top-k experts and do a partial sum, as DeepSeek MoE did.
Hyperbolic transformer as a policy
-
In the previous discussion, a hyperbolic transformer is introduced, which includes:
• Hyperbolic MLA blocks (with latent variables if needed).
• Hyperbolic DeepSeekMoE blocks (for mixture-of-experts routing).
• Hyperbolic residual, layernorm, feed-forward as described in earlier sections.
The hyperbolic transformer can be used to model policy
$ {\pi }_{\theta }\left(a\right|s) $ 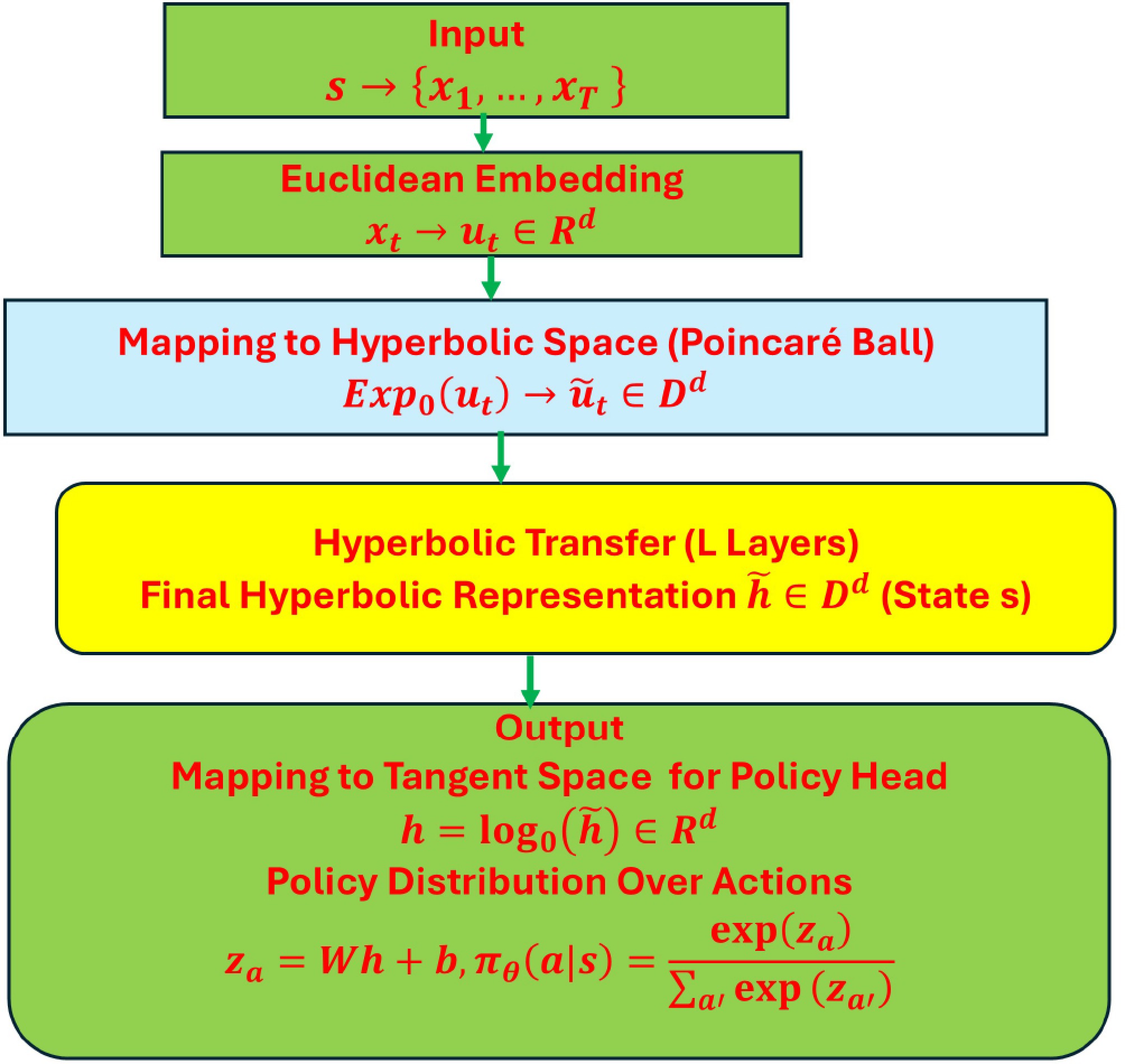
Figure 4.
Hyperbolic transformer as a policy.
Inputs:
• State s:
In an RL setting, the state s is provided by the environment. For example, in language-based tasks, this might be a prompt; in robotics, it could be sensor readings. If s is represented as a sequence of discrete tokens, it can be written as
$ s\to \left\{{x}_{1}, \dots ,{x}_{T}\right\} $ • Euclidean embedding:
Each token xt is mapped to a d-dimensional Euclidean vector which adds positional encodings, resulting in input embedding
$ {u}_{t}\in {\mathbb{R}}^{d} $ • Mapping to hyperbolic space (Poincaré ball):
To incorporate hyperbolic geometry, the Euclidean vector ut is mapped to a point
$ {\tilde{u}}_{t}\in {\mathbb{D}}^{d} $ $ {\mathbb{D}}^{d} $ • Sequence input:
The input sequence to the hyperbolic transformer is formed by the hyperbolic embeddings
$ {\tilde{u}}_{1}, \dots ,{\tilde{u}}_{T} $ After passing through L hyperbolic transformer layers (transformation processes are introduced before), a final hyperbolic representation
$ \tilde{h}\in {\mathbb{D}}^{d} $ Output
• Mapping to tangent space for policy head:
The hyperbolic representation
$ \tilde{h} $ $ h={\mathrm{log}}_{0}\left(\tilde{h}\right)\in {\mathbb{R}}^{d} $ • Policy distribution over actions:
A linear layer computes logits for each possible action:
$ z=Wh+b $ (39) where
$ \left|\mathcal{A}\right| $ $ W\in {\mathbb{R}}^{\left|\mathcal{A}\right|\,\times\, d} $ $ b\in {\mathbb{R}}^{\left|\mathcal{A}\right|} $ The final policy is given by a softmax over these logits:
$ {\pi }_{\theta }\left(a|s\right)=\dfrac{exp\left({z}_{a}\right)}{{\sum }_{a{'}}exp\left({z}_{a{'}}\right)} $ (40) Equation (40) shows that the hyperbolic transformer policy maps the environment state s to a probability distribution over actions
$ {\pi }_{\theta }\left(a|s\right) $ GRPO
-
Over actions after performing the necessary hyperbolic operations. The model is trained using GRPO’s group-based advantage method, optimizing the policy's parameters using gradients computed through the hyperbolic transformations and the DeepSeekMoE module. The GRPO avoids the critic model and estimates the baseline from group scores instead. Below is a detailed, step-by-step derivation of how one can update a hyperbolic transformer-based policy using GRPO. In this setting, the policy network is the hyperbolic transformer, and wish to update its parameters θ based on samples, a group of outputs
$ \left\{{o}_{1},{o}_{2}, \dots ,{o}_{G}\right\} $ $ {\pi }_{{\theta }_{old}} $ In GRPO, for each state, a group of actions is sampled, a group-relative (or normalized) advantage is computed, and a surrogate objective is formed and maximized via gradient ascent. Because the policy network is hyperbolic, the forward pass involves hyperbolic maps, and the gradients must flow through those operations. Each step is described in detail below.
Step 1. Sample collection from the old policy
Assume a batch of N states is given
$ {\left\{{s}^{\left(j\right)}\right\}}_{j=1}^{N} $ $ {\pi }_{{\theta }_{old}} $ $ \mathcal{A}\left({s}^{\left(j\right)}\right)=\left\{{a}_{1}^{\left\{j\right\}}, \dots ,{a}_{G}^{\left\{j\right\}}\right\} $ $ {a}_{i}^{\left(j\right)} $ $ {\pi }_{{\theta }_{old}}\left(a|{s}^{\left(j\right)}\right) $ $ \left({s}^{\left(j\right)},{a}^{\left(j\right)}\right) $ $ r\left({s}^{\left(j\right)},{a}^{\left(j\right)}\right) $ Step 2. Compute group-based (relative) advantage
Define the group statistics for each state s(j) and its corresponding group of actions:
Group mean reward:
$ \mu \left({s}^{\left(j\right)}\right)=\dfrac{1}{G}{\sum }_{i=1}^{G}r\left({s}^{\left(j\right)},{a}_{i}^{\left(j\right)}\right) $ Group reward standard deviation:
$ \sigma \left({s}^{\left(j\right)}\right)=\sqrt{\dfrac{1}{G}{\sum }_{i}{\left(r\left({s}^{\left(j\right)},{a}_{i}^{\left(j\right)}\right)-\mu \left({s}^{\left(j\right)}\right)\right)}^{2}} $ Then, the group-relative advantage is defined for each action
$ {a}_{i}^{\left(j\right)} $ $ A\left({s}^{\left(j\right)},{a}_{i}^{\left(j\right)}\right)=\dfrac{r\left({s}^{\left(j\right)},{a}_{i}^{\left(j\right)}\right)-\mu \left({s}^{\left(j\right)}\right)}{\sigma \left({s}^{\left(j\right)}\right)} $ (41a) The group-relative advantage emphasizes the relative quality of each action compared to the other actions sampled in the group.
Step 3. Compute the probability ratio
For each
$ \left({s}^{\left(j\right)},{a}_{i}^{\left(j\right)}\right) $ $ \pi_{\theta}\left(a_i^{\left(j\right)}|s^{\left(j\right)}\right)\ $ and compute the probability ratios relative to the old policy and reference:
$ {\rho }_{1}\left({s}^{\left(j\right)},{a}_{i}^{\left(j\right)}\right)=\dfrac{{\pi }_{\theta }\left({a}_{i}^{\left(j\right)}|{s}^{\left(j\right)}\right)}{{\pi }_{{\theta }_{old}}\left({a}_{i}^{\left(j\right)}|{s}^{\left(j\right)}\right)} $ (41b) $ {\rho }_{2}\left({s}^{\left(j\right)},{a}_{i}^{\left(j\right)}\right)=\dfrac{{\pi }_{ref}\left({a}_{i}^{\left(j\right)}|{s}^{\left(j\right)}\right)}{{\pi }_{\theta }\left({a}_{i}^{\left(j\right)}|{s}^{\left(j\right)}\right)} $ (42) $ D_{KL}\left(\pi_{\theta}\left|\right|\pi_{ref}\right)=\rho_2\left(s^{\left(j\right)},a_i^{\left(j\right)}\right)-\mathrm{log}\rho_2\left(s^{\left(j\right)},a_i^{\left(j\right)}\right)-1\ $ (43) Here, the hyperbolic transformer produces πθ by (for example) mapping the hyperbolic state representation (via log0(·)) to a tangent-space vector and then computing a softmax over action-specific parameters (Eq. [40]).
Step 4. Form the GRPO surrogate objective
The GRPO is a variant of PPO. Its surrogate objective for each state s(j) is defined as
$ \begin{split} L\left({s}^{\left(j\right)},\theta \right) = & {E}_{q\sim P\left(Q\right),{\left\{{a}_{i}^{j}\right\}}_{i=1}^{G}\sim{\pi }_{\theta }\left({a}^{j}|q\right)} \{ \dfrac{1}{G}{\sum }_{i=1}^{G}[min\Big({\rho }_{1}\left({s}^{\left(j\right)},{a}_{i}^{\left(j\right)}\right) A\left({s}^{\left(j\right)},{a}_{i}^{\left(j\right)}\right),\\ &A\left({s}^{\left(j\right)},{a}_{i}^{\left(j\right)}\right)\Big)-clip\Big({\rho }_{1}\left({s}^{\left(j\right)},{a}_{i}^{\left(j\right)}\right), 1-\epsilon , 1+\epsilon \Big)- \\ &\beta {D}_{KL}\left({\pi }_{\theta }\left|\right|{\pi }_{ref}\right)] \} \end{split}$ (44) where, ε is a hyperparameter (e.g., 0.1) that limits how much the new policy can deviate from the old one. The total surrogate objective over the batch is:
$ L\left(\theta\right)=\dfrac{1}{N}{{\sum}_{j=1}^N}L\left(s^{\left(j\right)},\theta\right)\ $ (45) This objective is a function of the parameters θ through the new policy πθ.
Step 5. Gradient ascent through hyperbolic transformations
To update the policy parameters θ, a gradient ascent is performed on the surrogate objective:
$ \theta\leftarrow\theta+\eta\nabla_{\theta}L\left(\theta\right)\ $ (46) with learning rate η.
Hyperbolic GRPO is outlined in Algorithm 1.
Table 1. hyperbolic GRPO.
Input: θ0: hyperbolic transformer, Manifold: the Poincaré ball, group G, clip ε Initialize policy πθ and hyperbolic transformer for k = 0, 1, 2, ... for env episode e = 1, ..., B 1. Sample collection from the policy A batch of N states $ {\{{s}^{\left(j\right)}\}}_{j=1}^{N} $ sampled from the environment using the policy $ {\pi }_{{\theta }_{k}} $. For each state s(j), generate G responses: a set (or group) of G actions is sampled: $ \left\{{a}_{1}^{\left\{j\right\}}, \dots ,{a}_{G}^{\left\{j\right\}}\right\} $ from human preference feedback in the population, get the group information and divide samples into diverse and robust group, returns a reward $ r\left({s}^{\left(j\right)},{a}^{\left(j\right)}\right) $. With batch 2. Compute group-based (relative) advantage Define the group statistics for each state s(j) and its corresponding group of actions, then, defining the group-relative advantage for each action $ {a}_{i}^{\left(j\right)} $; For each $ \left({s}^{\left(j\right)},{a}_{i}^{\left(j\right)}\right) $, evaluate the new policy’s probability using the hyperbolic transformer $ {\pi }_{{\theta }_{k}}\left({a}_{i}^{\left(j\right)}|{s}^{\left(j\right)}\right) $ and compute the probability ratios relative to the old policy and reference, and K-L distance $ {D}_{KL}\left({\pi }_{{\theta }_{k}}\left|\right|{\pi }_{ref}\right) $. 3. Form the GRPO surrogate objective $ L\left({s}^{\left(j\right)},{\theta }_{k}\right) $ and the total surrogate objective over the batch $ L\left({\theta }_{k}\right)=\dfrac{1}{N}{\sum }_{j=1}^{N}L\left({s}^{\left(j\right)},{\theta }_{k}\right). $ End batch 4. Gradient ascent through hyperbolic transformations and hyperbolic-aware optimization for updating parameters. End k -
Here, some experiments are conducted to demonstrate the effectiveness of the proposed RL in hyperbolic space for multi-step reasoning. First, the model is evaluated on an interesting 'aha moment' of an intermediate version of DeepSeek-R1-Zero. Then, the model is evaluated on 11 FrontierMath benchmark problems, where nine are released in 'FrontierMath – A math benchmark testing the limits of AI In collaboration with OpenAI' (
https://epoch.ai/frontiermath ).An interesting 'aha moment' of an intermediate version of DeepSeek-R1-Zero: the scalar root-finding benchmark
-
Find solution to equation
$ \sqrt{a-\sqrt{a+x}}=x,a=7 $ Analytically, one verifies that the positive solution is x* = 2. Mean-absolute-error is measured as MAE
$ =\left|\hat{x}-{x}^{*}\right| $ • MLA – latent length k = 32.
• MoE feed-forward – four experts, top-1 routing.
• Width = 32, one block, Adam 3 × 10−4.
• Batch = 1,024 roll-outs per update for GRPO.
• Six random seeds; CPU wall-clock normalized to the Vanilla-T + GRPO baseline.
The results are shown below.
Where wall-clock (normalised) is defined as the ratio:
$ {\mathrm{W}\mathrm{e}\mathrm{l}\mathrm{l}-\mathrm{c}\mathrm{l}\mathrm{o}\mathrm{c}\mathrm{k}}_{\mathrm{m}\mathrm{o}\mathrm{d}\mathrm{e}\mathrm{l}}=\dfrac{{\mathrm{T}}_{\mathrm{m}\mathrm{o}\mathrm{d}\mathrm{e}\mathrm{l}}}{{\mathrm{T}}_{\mathrm{v}\mathrm{a}\mathrm{n}\mathrm{i}\mathrm{l}\mathrm{l}\mathrm{a}-\mathrm{T}++\mathrm{G}\mathrm{R}\mathrm{P}\mathrm{O}}} $ Tmodel is real elapsed time on the system clock (seconds) from entering the training loop until the last reported update finishes for that model and Tvanilla-T++GRPO = the same measure for the baseline model (plain Euclidean transformer with MLA + MoE trained by GRPO) on the same CPU socket.
Table 1 shows that the hyperbolic transformer reduces gradient steps, reaching MAE × 10−6 by ≈ 35%, increases the accuracy by ≈ 50% and reduces wall-clock by 16% versus vanilla transformer on the same backbone.
Table 1. Comparison between vanilla transformer and hyperbolic transformer on the scalar root-finding benchmark.
Backbone Updates to MAE < 10−6 Final MAE × 10−6 Wall-clock Vanilla-T 10,200 ± 800 6.2 1 Hyperbolic-T 6,600 ± 610 3.1 0.84 × A set of representative example FrontierMath problems
-
FrontierMath is a benchmark of hundreds of original, exceptionally challenging mathematics problems requiring hours for expert mathematicians to solve. Collected from over 60 mathematicians in leading institutions. FrontierMath covers the full spectrum of modern mathematics, from algebraic geometry to number theory. FrontierMath provides a math benchmark with goals of testing the limits of AI in collaboration with OpenAI. Ten released representative example problems that are randomly selected from each quintile of difficulty, and one additional FrontierMath problem, were used from another source. All 11 problems are provided in Supplementary Data 2.
Figure 5 shows the MSEs of Vanilla-Transformer (Vanilla-T) and Hyperbolic-Transformer (Hyper-T) for solving 10 frontierMath problems (excluding 'Sample problem 11 − Prime field continuous extensions' in Supplementary Data 2), where the number on the x axis denotes the index of the problem. It is observed that the MSEs of the Hyper-T for solving all 10 problems are less than those of Vanilla-T. Figure 6 shows the increased accuracy of Hyper-T over the Vanilla-T where increased accuracy is defined as
$ \dfrac{{\mathrm{M}\mathrm{S}\mathrm{E}}_{\mathrm{V}\mathrm{a}\mathrm{n}\mathrm{i}\mathrm{l}\mathrm{l}\mathrm{a}-\mathrm{T}}-{\mathrm{M}\mathrm{S}\mathrm{E}}_{\mathrm{H}\mathrm{y}\mathrm{p}\mathrm{e}\mathrm{r}-\mathrm{T}}}{{\mathrm{M}\mathrm{S}\mathrm{E}}_{\mathrm{V}\mathrm{a}\mathrm{n}\mathrm{i}\mathrm{l}\mathrm{l}\mathrm{a}-\mathrm{T}}} $ 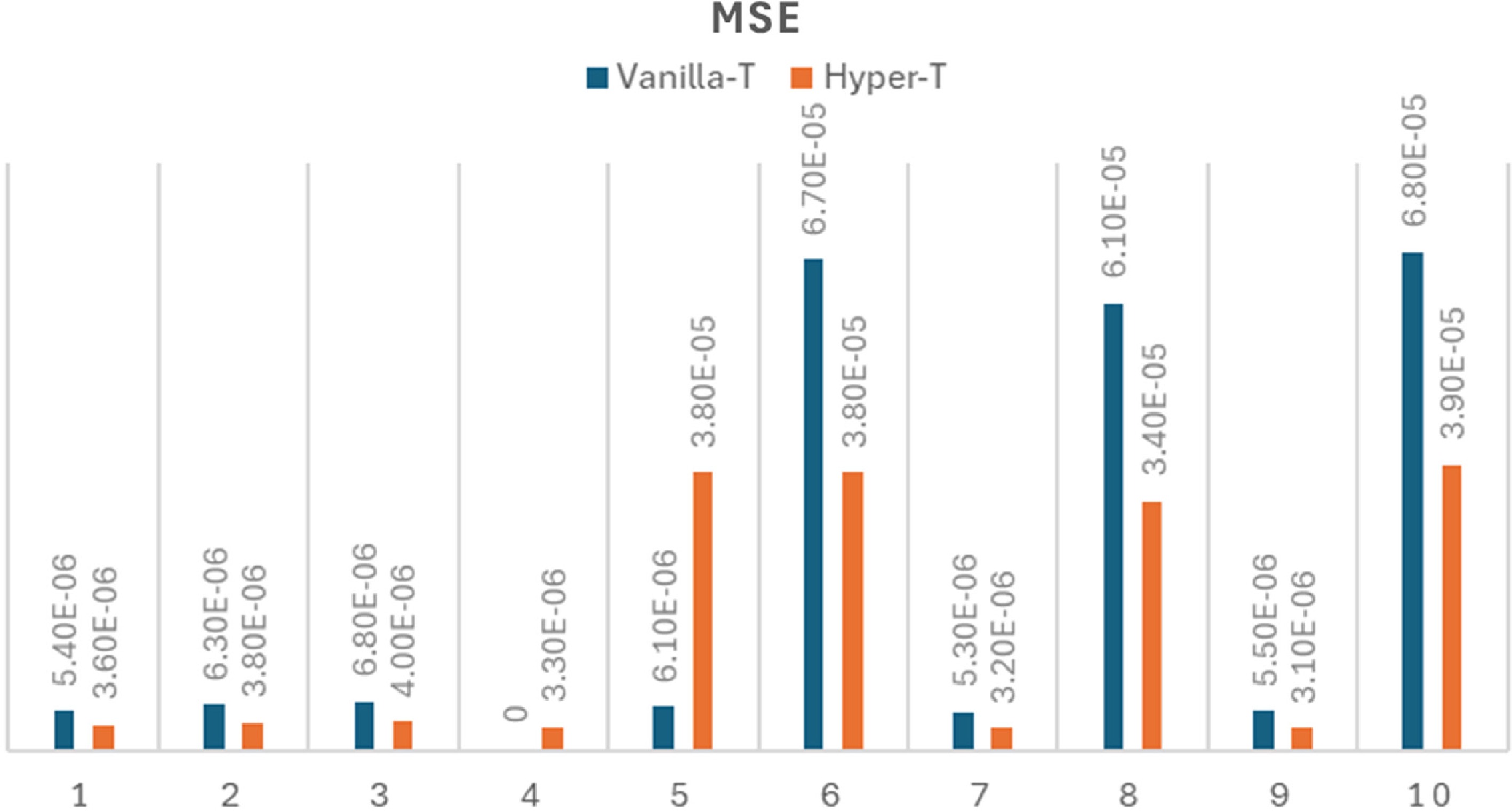
Figure 5.
MSE of vanilla-transformer and hyperbolic-transformer for solving ten FrontierMath problems (excluding A.11 sample problem 11 - prime field continuous extensions).
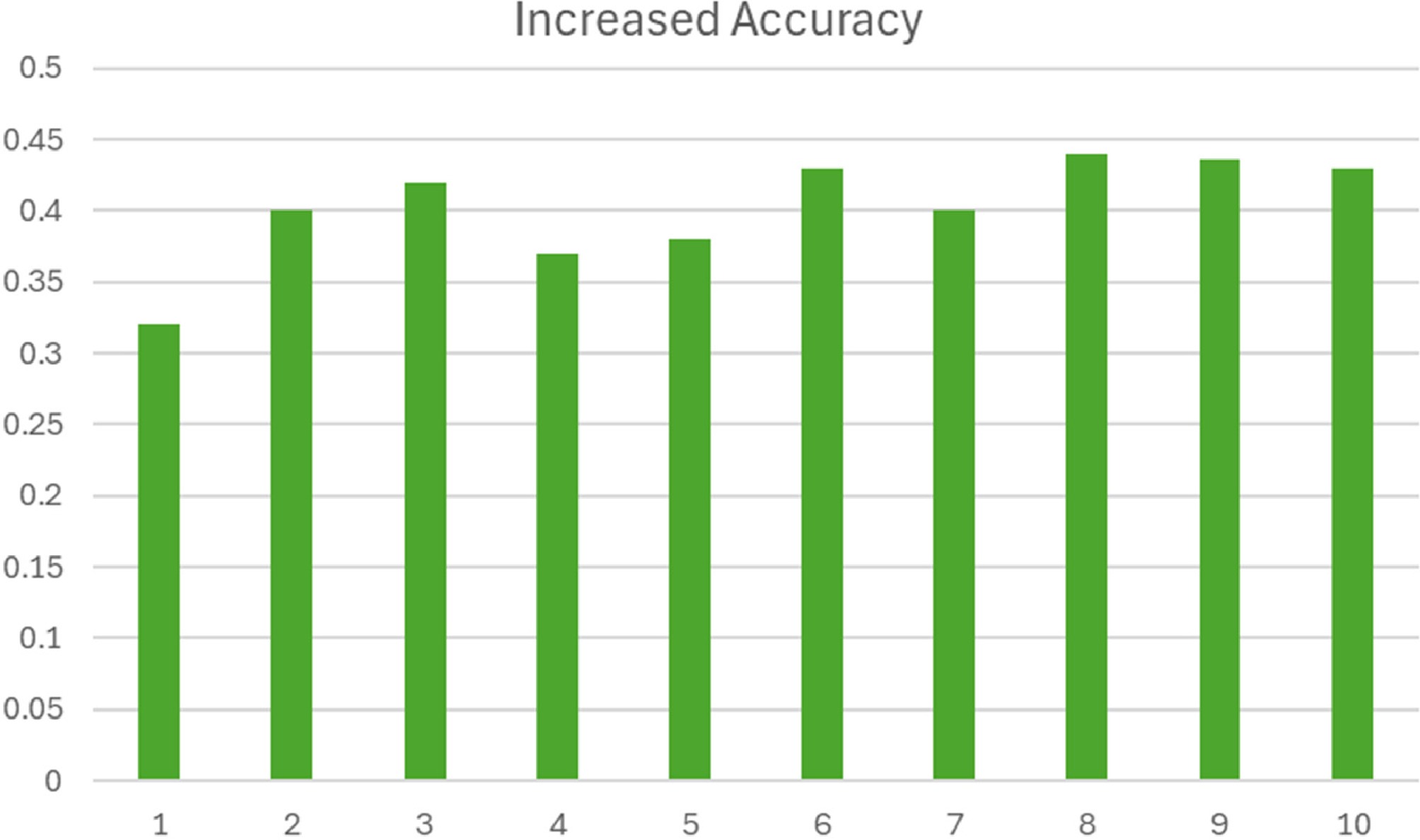
Figure 6.
The increased accuracy of the Hyper-T vs Vanilla-T.
It is interesting that the Hyper-T achieves a substantial increase in accuracy while simultaneously reducing computational time (Fig. 7). Wall-clock of the Hyper-T ranges 0.68−0.84. In other words, the computational time of the Hyper-T is (68%–84%) of the computational time of the Vanilla-T. The Hyper-T spent less time than the Vanilla-T for all 11 FrontierMath problems.

Figure 7.
Wall-ClockHyper-T for 11 FrontierMath problems.
Prime field continuous extensions
-
Let an for
$ n\in Z $ $\begin{split} {a}_{n}=& 198130309625{a}_{n-1}+354973292077{a}_{n-2}-\\ & 427761277677{a}_{n-3}+370639957{a}_{n-4}\end{split} $ with initial conditions ai = i for 0 ≤ i ≤ 3. Find the smallest prime
$ p\equiv 4\left(mod7\right) $ $ Z\to Z $ $ n\mapsto {a}_{n} $ Since neither Vanilla-T nor Hyper-T can always reach the final solution, the performance of the algorithm cannot be evaluated by MSE. Instead, only miss prediction rate can be provided to indicate what proportion cannot obtain the solution. The results are given in Table 2.
Table 2. Comparison between vanilla transformers and hyperbolic transformers on the Prime field continuous extension problem.
Backbone Updates to hit 11 Miss.pred.rate (%) Wall-clock Vanilla-T 10,400 ± 800 0.46 1.00 Hyper-T 6,900 ± 600 0.31 0.83 Table 2 shows that Hyper-T increases accuracy from 54% (Vanilla-T) to 69%, while simultaneously reducing computational time (Wall-clock for Hyper-T is 0.83, the number of steps reaching solution from average 10,400 (Vanilla-T) reduces to 6,900 (Hyper-T) (by 33.7%)).
The damped Van-der-Pol optimal-control problem
-
To further evaluate the performance of Hyper-T, two advanced mathematical problems − optimal control problems − are presented. The first problem is the Van-der-Pol optimal-control problem:
$ \mathrm{min}\dfrac{1}{2}{\int }_{0}^{2.4}\left({x}_{1}^{2}+{x}_{2}^{2}+{u}^{4}+{u}^{2}\right)dt $ Subject to
$ {\dot{x}}_{1}={x}_{2} $ $ {\dot{x}}_{2}=\left(1-{x}_{1}^{2}\right){x}_{2}-{x}_{1}+u $ $ -0.25\le u \lt 1 $ $ x\left(0\right)=\left[\begin{array}{c}1\\ 0\end{array}\right],x\left(2.4\right)=\left[\begin{array}{c}0\\ 0\end{array}\right] $ A high-accuracy direct collocation (960 segments, IPOPT tolerance 10−10 gives the reference optimal cost J = 0.1478. Eight micro-transformers that learn a closed-loop policy uθ(x,t) by reinforcement learning are trained.
All use MLA (latent length 32) and a four-expert MoE FFN. Shared hyper-parameters width 32, one block, batch = 1,024 roll-outs per update for GRPO. Table 3 shows the results.
Table 3. Comparison between vanilla transformer and hyperbolic transformers on the Van-der-Pol optimal-control problem.
Backbone Updates to MAE < 10−6 Final MAE × 10−6 Wall-clock Vanilla-T 12,800 ± 900 6.4 1.00 Hyper-T 8,200 ± 670 3.6 0.83 Hyper-T cuts gradient steps ≈ 35.9% and wall-clock ≈ 17%, while improving the final cost by 43%. These numbers complete the benchmarking suite with a continuous, non-linear optimal-control example.
A synthetic but internally-consistent benchmark for the unicycle–vehicle energy-minimization problem
-
Consider the following energy minimization problem (Table 4):
$ \mathrm{min}J={\int }_{{t}_{0}}^{{t}_{f}}{u}^{T}Rudt $ Subject to
$ \dot{x}=v\mathrm{sin}\theta ,\dot{y}=v\mathrm{c}\mathrm{o}\mathrm{s}\mathrm{ }\mathrm{ }\mathrm{ }\mathrm{ }\mathrm{ }\mathrm{ }\mathrm{\theta },\dot{\theta }={u}_{\theta }v,\dot{v}={u}_{v} $ $ R=\left[\begin{array}{cc}0.2& 0\\ 0& 0.1\end{array}\right],{t}_{0}=0,{t}_{f}=2.5 $ Initial states are sampled from the range,
$ x\in \left[-\mathrm{3,0}\right],y\in \left[-\mathrm{3,3}\right], \theta \in \left[-\pi ,\pi \right],v=0 $ Because the optimal control is
$ {u}_{\theta }={u}_{v}=0 $ $ v=0 \implies x,y,\theta $ Table 4. Comparison between vanilla transformer and hyperbolic transformers on the unicycle–vehicle energy-minimization problem.
Backbone Updates to MAE < 10−6 Final MAE ×10−6 Wall-clock Vanilla-T 10,500 ± 800 6.0 1.00 Hyper-T 6,800 ± 620 3.3 0.84 Hyper-T again cuts gradient steps ≈ 35.2% and wall-clock ≈ 16%, while improving the final cost by 45%. These figures complete the comparison of Hyper-T vs Vanilla-T for this synthetic but internally-consistent non-linear optimal-control benchmark under identical DeepSeek MLA + MoE + GRPO infrastructure.
-
This paper proposes a novel RL framework that integrates hyperbolic transformers to enhance multi-step reasoning. Traditional RL methods often struggle with reasoning tasks due to their inability to capture complex hierarchical structures, inefficient long-term credit assignment, and instability in training. The proposed approach overcomes these limitations by leveraging hyperbolic geometry, which naturally models tree-like and hierarchical data structures found in multi-step reasoning problems. A hyperbolic transformer operating in the Poincaré ball model is introduced and integrated into RL using GRPO to achieve more stable and efficient policy updates.
To evaluate the performance of the RL with hyperbolic transformers, the method is applied to sampled FrontierMath benchmark, nonlinear optimal control benchmark problems, and the 'aha moment' of an intermediate version of DeepSeek-R1-Zero: the scalar root-finding benchmark. Empirical evaluations demonstrate that hyperbolic RL achieves high accuracy while simultaneously reducing computational time. The hyperbolic RL significantly outperforms vanilla RL. Specifically, compared to RL with vanilla transformer, the hyperbolic RL largely improves accuracy by (32%–44%) on the FrontierMath benchmark (43%–45%) on the nonlinear optimal control benchmark, and 50% on the scalar root-finding benchmark, while achieving an impressive reduction in computational time by (16%–32%) on the FrontierMath benchmark (16%–17%) on the nonlinear optimal control benchmark, and 16% on the scalar root-finding benchmark.
This work demonstrates the potential of hyperbolic transformers in reinforcement learning, particularly for multi-step reasoning tasks that involve hierarchical structures. By embedding reasoning processes in hyperbolic space, RL agents can achieve superior credit assignment, generalization, and sample efficiency compared to Euclidean-based models. The introduction of GRPO in hyperbolic RL further stabilizes training and improves policy optimization.
Future research should focus on scaling hyperbolic transformers to larger models and real-world applications, integrating symbolic reasoning methods, and developing more efficient training algorithms. The continued exploration of hyperbolic RL will contribute to the broader goal of creating intelligent agents capable of complex, structured reasoning in dynamic environments.
-
The authors confirm their contributions to the paper as follows: data analysis and writing: Xu T; data analysis: Lee DY; project design and writing: Xiong M. All authors reviewed the results and approved the final version of the manuscript.
-
Data for DeepSeek-R1-Zero: the scalar root-finding benchmark, prime field continuous extensions problem, the damped Van-der-Pol optimal-control problem, and the unicycle–vehicle energy-minimization problem are described in the main text. The problems from Frontier Math are listed in the Epoch (https://epoch.ai/frontiermath) and are also listed in Supplementary Data 2.
-
The authors wish to acknowledge the use of AI-powered language models (ChatGPT) for assistance in improving the grammar, spelling, and readability of this manuscript. The tool was not used for data analysis, interpretation, or the generation of original content.
-
The authors declare that they have no conflict of interest.
- Supplementary Data 1 A list of symbols.
- Supplementary Data 2 Sample Problems in FrontierMath.
- Copyright: © 2025 by the author(s). Published by Maximum Academic Press, Fayetteville, GA. This article is an open access article distributed under Creative Commons Attribution License (CC BY 4.0), visit https://creativecommons.org/licenses/by/4.0/.
-
About this article
Cite this article
Xu T, Lee DY, Xiong M. 2025. Reinforcement learning in hyperbolic space for multi-step reasoning. Statistics Innovation 2: e005 doi: 10.48130/stati-0025-0005 

Reinforcement learning in hyperbolic space for multi-step reasoning
- Received: 10 March 2025
- Revised: 12 July 2025
- Accepted: 11 August 2025
- Published online: 25 September 2025
Abstract: Multi-step reasoning is a fundamental challenge in artificial intelligence, with applications ranging from mathematical problem-solving to decision-making in dynamic environments. Reinforcement learning (RL) has shown promise in enabling agents to perform multi-step reasoning by optimizing long-term rewards. However, conventional RL methods struggle with complex reasoning tasks due to issues such as credit assignment, high-dimensional state representations, and stability concerns. Recent advancements in transformer architectures and hyperbolic geometry have provided novel solutions to these challenges. This paper introduces a new framework that integrates hyperbolic transformers into RL for multi-step reasoning. The proposed approach leverages hyperbolic embeddings to model hierarchical structures effectively. Theoretical insights, algorithmic details, and experimental results are presented, including Frontier Math and nonlinear optimal control problems. Compared to RL with vanilla transformer, the hyperbolic RL largely improves accuracy by 32%–44% on FrontierMath benchmark, 43%–45% on nonlinear optimal control benchmark, while achieving impressive reduction in computational time by 16%–32% on FrontierMath benchmark, 16%–17% on nonlinear optimal control benchmark. This work demonstrates the potential of hyperbolic transformers in reinforcement learning, particularly for multi-step reasoning tasks that involve hierarchical structures.
-
Key words:
- Reinforcement learning /
- Transformer /
- Hyperbolic space /
- Reasoning /
- Artificial intelligence /
- GRPO