









-
Variable selection is a fundamental problem in modern statistics, particularly in high-dimensional regression, where the number of predictors can greatly exceed the sample size[1,2,3]. When covariates possess a natural grouping structure, such as sets of genetic markers belonging to the same biological pathway, the ability to select or discard groups of variables rather than individual variables becomes crucial for both interpretability and statistical efficiency. Group LASSO[4] provides an early and influential framework for grouped selection by penalizing the
$ \ell_2 $ Our research is motivated by the unique data structures encountered in gene set analysis (GSA). Gene set variation analysis (GSVA)[9] is a widely used unsupervised method that constructs, for each individual and each gene set, a Kolmogorov–Smirnov (KS) statistic comparing the distributions of expression levels for genes inside the set with those outside. The collection of such statistics along the ranked gene list yields an individualized KS curve that characterizes the enrichment profile of the gene set. Figure 1 shows examples of these curves for the Kyoto Encyclopedia of genes and genomes (KEGG)[10] pathway "MicroRNAs in Cancer," where each curve corresponds to one individual. In practice, GSVA summarizes each curve by a single enrichment score, which is then used as the gene-set–level feature. This representation suffers from two important limitations. First, the enrichment score is marginal in the sense that it does not adjust for dependence among gene sets, and thus, the gene sets with significant enrichment scores may rise because of correlation with truly relevant ones. Second, reducing the entire curve to a single number may fail to capture the important structural features of the enrichment pattern, potentially limiting the statistical efficiency and biological interpretability[11].
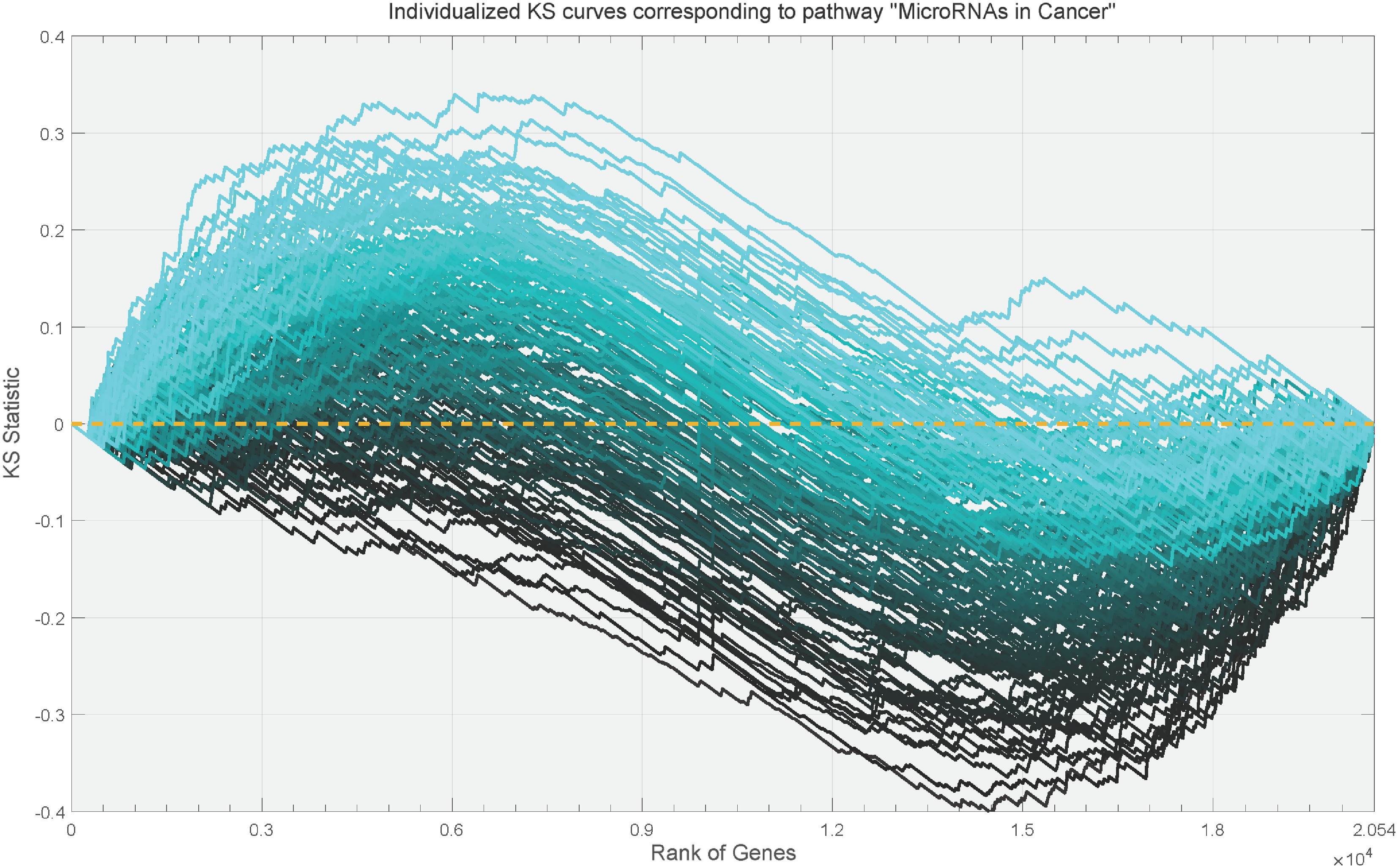
Figure 1.
Individualized KS curves corresponding to the pathway "MicroRNAs in Cancer". Each curve corresponds to an individual and is estimated from the head and neck squamous cell carcinoma data. The depth of the curve's color is determined by the value of the extreme point in the curve.
A natural remedy is to treat the collection of genes within a set, or equivalently, the curves formed by their KS statistics, as a group, and then apply group variable selection methods to automatically identify the most important gene sets. However, the existing group variable selection methods are not well suited for this setting because gene set data typically exhibit substantially more complex structures. For instance, the design matrix of a gene set may consist of individualized curves, leading to dimensions of size n × p, where n is the sample size and p is the number of genes. When the group size is very large, conventional group selection methods are prone to computational difficulties such as non-convergence. Moreover, strong correlations among genes or functional-like curve structures within a set result in severe multicollinearity, violating the irrepresentable conditions required for consistent group selection[12,13]. Consequently, truly important gene sets cannot be reliably recovered under standard penalized regression. A few methods, such as the elastic net[14] and factor-adjusted regularized model selection (Farm-Select)[15], offer partial remedies by addressing multicollinearity, but they neither exploit the grouping of covariates nor accommodate complex within-group structures.
To address the challenges of high-dimensional grouped data with complex group structures, we propose factor-augmented group effect selection (FAGES), a novel group variable selection method that simultaneously identifies important groups, provides comparable estimates of group effect sizes, and determines their effect directions. The key idea is to represent each group of variables by a low-dimensional latent factor that captures its main variation, and then specify a factor-augmented regression model accounting for the additive contributions of all groups. In particular, when the grouped variables take the form of curves (e.g., individualized KS curves in GSA), the latent factor representation can be viewed as functional principal component analysis (FPCA)[16,17], enabling FAGES to effectively handle functional data structures. By applying a variable selection penalty, FAGES achieves both group identification and effect estimation in a unified framework. We establish the consistency of parameter estimation and group selection under mild conditions, and numerical studies demonstrate that FAGES reliably recovers relevant groups even under model misspecification. As an illustration, we apply FAGES to head and neck squamous cell carcinoma (HNSCC) transcriptomic data and detect the biological pathways that play key roles in disease development.
-
For a vector a = (aj)p × 1, let ||a||q = (
$\sum_{j=1}^p $ $ \in $ $ j $ $ ||{\bf{A}}\|_F^2=\sum_{i}\sum_{j}A_{ij}^2 $ $ \asymp $ $ \in\mathbb{R}^{p\times p} $ Background
Approximate factor model
-
A multivariate variable Xi = (Xi1, …, Xip)T is termed to follow a factor model if
$ {\bf{X}}={\bf{F}}{\boldsymbol{\Lambda}}^\top +{\bf{e}}, $ (1) where, X = (X1, …, Xn)T is the sample matrix of Xi, F= (F1, …, Fn)T is the matrix of latent factor Fi = (fi1, …, fiK)T,
$ {\boldsymbol{\Lambda}} $ Principal components analysis (PCA) and AFM are closely related[18]. Specifically, F and
$ {\boldsymbol{\Lambda}} $ $ \begin{aligned} \hat{{\bf{F}}},\hat{{\bf{\Lambda}}}&=\arg\min_{{\bf{F}},{\bf{\Lambda}}}\ ||{\bf{X}}-{\bf{F}}{\bf{\Lambda}}^\top ||_\text{F}^2,\\ &\text{subject to } {\bf{F}}^\top {\bf{F}}/n={\bf{I}}_K \text{ and } {\bf{\Lambda}}^\top {\bf{\Lambda}} \text{ is diagonal}. \end{aligned} $ (2) The minimizers of the above restricted minimization are explicit and unique. Suppose the singular value decomposition X =
$ \sum_{s=1}^p $ $ \hat{{\bf{F}}}=\sqrt n({\boldsymbol{U}}_1,\cdots,{\boldsymbol{U_K}}) $ $ \hat{\Lambda}={\bf{X}}^\top \hat{{\bf{F}}}/\sqrt n $ $ \hat{{\bf{F}}} $ Note that AFM is further connected to functional PCA, which is used to characterize the main pattern of the individualized trajectories around an overall mean trend function in functional data analysis[19]. In the simulation example on functional regression, we introduce how to use AFM to handle the functional data through the projection-PCA[16].
Group variable selection approaches
-
Multivariate variable Xi is termed to have a group structure if there is a series of sets
$ \{{\cal{M}}_1,\cdots,{\cal{M}}_J\} $ $ ({\boldsymbol{X}}_{i{\cal{M}}_1}^\top,\dots,{\boldsymbol{X}}_{i{\cal{M}}_J}^\top)^\top $ $ g({\boldsymbol{\mu}})={\bf{1}}\beta_0+{\bf{X}}_{{\cal{M}}_1}{{\boldsymbol{\beta}}}_{{\cal{M}}_1}+\cdots+{\bf{X}}_{{\cal{M}}_J}{{\boldsymbol{\beta}}}_{{\cal{M}}_J}, $ (3) where,
$ {\boldsymbol{\mu}} $ $\in\mathbb{R}^{n} $ $ \in\mathbb{R}^{n} $ $ {\bf{X}}_{{\cal{M}}_j}=({\boldsymbol{X}}_{1,{\cal{M}}_j},\dots,{\boldsymbol{X}}_{n,{\cal{M}}_j})^\top\in\mathbb{R}^{n\times p_j} $ $ {\cal{M}}_j $ $ {{\boldsymbol{\beta}}}_{{\cal{M}}_j}\in\mathbb{R}^{p_j} $ $ p_j=|{\cal{M}}_j| $ $ s\in{\cal{M}}_j $ $ ({\bf{1}},{\bf{X}}_{{\cal{M}}_1},\dots, {\bf{X}}_{{\cal{M}}_J})\in\mathbb{R}^{n\times(1+\sum_{j=1}^J p_j)} $ $ (\beta_0,{{\boldsymbol{\beta}}}_{{\cal{M}}_1}^\top,\dots,{{\boldsymbol{\beta}}}_{{\cal{M}}_J}^\top)^\top\in\mathbb{R}^{1+\sum_{j=1}^J p_j} $ The regression coefficient β can be estimated through the penalized likelihood[22] shown below:
$ \hat{{\boldsymbol{\beta}}}=\arg\min\limits_{{{\boldsymbol{\beta}}}}\bigg{\{}{\cal{L}}({\bf{X}}{{\boldsymbol{\beta}}})+n\sum\limits_{j=1}^J\rho_\lambda(||{{\boldsymbol{\beta}}}_{{\cal{M}}_j}||)\bigg{\}}, $ (4) where,
$ {\cal{L}}({\boldsymbol{\eta}})=-({\bf{y}}^\top{\boldsymbol{\eta}}-{\bf{1}}^\top b({\boldsymbol{\eta}})) $ $ \rho^\text{mcp}_\lambda(||{{\boldsymbol{\beta}}}||_2)=\lambda\int_0^{||{{\boldsymbol{\beta}}}||_2}\bigg{(}1-\frac{t}{a\lambda}\bigg{)}_+\text{d}t, $ (5) where, a > 2 is a tuning parameter. As well, the expression of GEL is given by
$ \rho^\text{gel}_\lambda(||{{\boldsymbol{\beta}}}||_1)=\frac{\lambda^2}{a}\bigg{\{}1-\exp\bigg{(}-\frac{a||{{\boldsymbol{\beta}}}||_1}{\lambda}\bigg{)}\bigg{\}}, $ (6) where, a > 0 is an alternative tuning parameter. In addition, a weight wβ is generally applied to adjust λ as wβλ to trade off the influence of group size. For group-level penalty, wβ is usually set as
$ \sqrt{{{\rm{dim}}}({{\boldsymbol{\beta}}})} $ Note that whether ρλ(||β||) is called group- or bi-level penalty depends on the type of norm ||·|| rather than its expression. The penalty is called group-level penalty if it measures the
$ \ell_2 $ $ \ell_1 $ Statistical methodology of FAGES
Representation
-
FAGES is a novel group variable selection method that combines the AFM and group variable selection approach reviewed in the previous section. Suppose a multivariate variable with group structure, i.e., Xi =
$(1,{\boldsymbol{X}}_{i,{\cal{M}}_1}^\top,\dots,{\boldsymbol{X}}_{i,{\cal{M}}_J}^\top)^\top $ $ {\boldsymbol{X}}_{i,{\cal{M}}_j} $ $ {\cal{M}}_j $ $ {\bf{X}}_{{\cal{M}}_j}={\bf{F}}_{{\cal{M}}_j}{\boldsymbol{\Lambda}}_{{\cal{M}}_j}^\top+{\bf{e}}_{{\cal{M}}_j}, $ (7) where,
$ {\bf{X}}_{{\cal{M}}_j}=({\boldsymbol{X}}_{1,{\cal{M}}_j},\dots,{\boldsymbol{X}}_{n,{\cal{M}}_j})^\top $ $ {\bf{F}}_{{\cal{M}}_j}=({\boldsymbol{F}}_{1,{\cal{M}}_j},\dots,{\boldsymbol{F}}_{n,{\cal{M}}_j})^\top $ $ {\boldsymbol{\Lambda}}_{{\cal{M}}_j}= ({\boldsymbol{\lambda}}_{1,{\cal{M}}_j},\dots,{\boldsymbol{\lambda}}_{p_j,{\cal{M}}_j}) $ $ {\bf{e}}_{{\cal{M}}_j}=({\boldsymbol{e}}_{1,{\cal{M}}_j},\dots,{\boldsymbol{e}}_{n,{\cal{M}}_j})^\top $ Since the major information of
$ {\bf{X}}_{{\cal{M}}_j} $ $ {\bf{F}}_{{\cal{M}}_j} $ $ {\cal{M}}_j $ $ {\bf{F}}_{{\cal{M}}_j} $ $ g({\boldsymbol{\mu}})={\bf{1}}\theta_0+\sum\limits_{j=1}^J{\bf{F}}_{{\cal{M}}_j}{{\boldsymbol{\theta}}}_{{\cal{M}}_j}. $ (8) Compared with the high-dimensional GLM (3), the grouped factor-augmented GLM discards the redundant parts
$ \{e_{i{\cal{M}}_j}\} $ $ \sum_j^J $ $ \sum_j^J $ $ {{\boldsymbol{\theta}}}_{{\cal{M}}_j} $ When the grouped factor-augmented GLM is misspecified, FAGES is still able to select the important groups with high precision. Specifically, consider the following model:
$ \text{E}(y_i|{\boldsymbol{X_i}})=g^{-1}(\eta_i^F+\eta_i^e), $ (9) Here,
$ \eta_i^F=\beta_0+\sum_j{\boldsymbol{F}}_{i{\cal{M}}_j}^\top{\boldsymbol{\theta}}_j $ $ \eta_i^e=\sum_j{\boldsymbol{e}}_{i{\cal{M}}_j}^\top{\boldsymbol{\beta}}_{{\cal{M}}_j} $ $ \{{\boldsymbol{F}}_{i{\cal{M}}_j}\} $ $ \{{\boldsymbol{e}}_{i{\cal{M}}_j}\} $ $ y_i $ $ \text{E}(y_i|{\boldsymbol{X_i}})=g^{-1}(\eta_i^F)+O(|\eta_i^{e}|^2), $ (10) indicating that the latent factors
$ \{{\boldsymbol{F}}_{{\cal{M}}_j}\} $ $ \{{\boldsymbol{X}}_{{\cal{M}}_j}\} $ In practice, we adopt a data-adaptive rule to select the number of factors. Specifically, for each group
$ {\cal{M}}_j $ ${\bf{X}}_{{\cal{M}}_j}^\top{\bf{X}}_{{\cal{M}}_j} $ $ z_{jk}=\frac{\sigma_{j,k-1}-\sigma_{jk}}{\sigma_{jk}-\sigma_{j,k+1}},\qquad k=2,\dots,K_{\max}, $ (11) and we set
$ K_j^{{\rm{DR}}}=\arg\max_{2\le k\le K_{\max}} z_{jk} $ $ r_{jk}=\frac{\sigma_{jk}}{\sigma_{j,k+1}},\qquad k=1,\dots,K_{\max}, $ (12) yielding
$ K_j^{{\rm{ER}}}=\arg\max_{1\le k\le K_{\max}} r_{jk} $ $ \tilde \sigma_{jk} $ $ {\bf{X}}_{{\cal{M}}_j} $ $ K_j^{{\rm{ACT}}}=\sum\limits_{k=1}^{K_{\max}}\text{I} \left(\tilde \sigma_{jk} \gt \,1+\sqrt{\frac{p_j}{n-1}}\right). $ (13) Finally, we take the conservative aggregation
$ K_j=\min \left\{K_j^{{\rm{DR}}},\,K_j^{{\rm{ER}}},\,K_j^{{\rm{ACT}}}\right\}, $ (14) and estimate the group factors
$ {\bf{F}}_{{\cal{M}}_j} $ Estimation and inference
-
In the implementation, FAGES first estimates the latent factor of each group through the PCA and then yields the related coefficient using the penalized likelihood below:
$ \hat{{\boldsymbol{\theta}}}=\arg\min\limits_{{{\boldsymbol{\theta}}}}\bigg{\{}{\cal{L}}(\hat{{\bf{F}}}{{\boldsymbol{\theta}}})+n\sum\limits_{j=1}^J\rho_{w_j\lambda}(||{{\boldsymbol{\theta}}}_{{\cal{M}}_j}||)\bigg{\}}, $ (15) where,
$ {\cal{L}}({\boldsymbol{\eta}}) $ $ {\boldsymbol{\eta}}=\hat{{\bf{F}}}{{\boldsymbol{\theta}}} $ $ \hat{{\bf{F}}}=({\bf{1}},\hat{{\bf{F}}}_{{\cal{M}}_1},\dots,\hat{{\bf{F}}}_{{\cal{M}}_J}) $ $ \hat{{\bf{F}}}_{{\cal{M}}_j} $ $ {\bf{X}}_{{\cal{M}}_j} $ $ \ell_2 $ $ \ell_1 $ $ {\cal{M}}_j $ After obtaining the minimizer
$ \hat{{\boldsymbol{\theta}}} $ $ {\cal{M}}_j $ $ \hat z_{{\cal{M}}_j}= \frac1{\sqrt n}||\hat{{\bf{F}}}_{{\cal{M}}_j}\hat{{\boldsymbol{\theta}}}_{{\cal{M}}_j}||_2. $ (16) This averaged group effect estimate is based on the fact that multiple latent factors may exist within a group and their directions are not identifiable under the AFM/PCA representation, rendering individual coefficient signs uninformative. By aggregating the fitted group-specific signal across samples, the averaged group effect provides a meaningful and comparable summary of the overall group contribution regardless of factor orientation.
With the same motivation, we propose to determine the related effect direction by the sign of certain well-defined correlation statistics
$ \widehat{{\rm{cor}}}(\hat{{\bf{F}}}_{{\cal{M}}_j}\hat{{\boldsymbol{\theta}}}_{{\cal{M}}_j},{\bf{y}}) $ $ \hat\omega_{{\cal{M}}_j}=\frac{1}{n(n-1)}\sum\limits_{i=1}^n\sum\limits_{s\neq i}^n{\bf{1}}(\hat{{\boldsymbol{F}}}_{i,{\cal{M}}_j}^\top\hat{{\boldsymbol{\theta}}}_{{\cal{M}}_j} \lt \hat{{\boldsymbol{F}}}_{s,{\cal{M}}_j}^\top\hat{{\boldsymbol{\theta}}}_{{\cal{M}}_j}){\bf{1}}(y_i \lt y_s)-\frac14 $ (17) has been demonstrated to be robust for modelling the dependency of two variables[29]. Other correlations like Kendall-
$ \tau $ $ \hat{{\bf{F}}}_{{\cal{M}}_j} $ $ \hat{{\boldsymbol{\Lambda}}}_{{\cal{M}}_j} $ Large sample property
-
Denote
$ \hat{{\bf{F}}}_{{\cal{M}}_j} $ $ {\bf{X}}_{{\cal{M}}_j} $ $ \hat{{\boldsymbol{\Lambda}}}_{{\cal{M}}_j}={\bf{X}}_{{\cal{M}}_j}^\top\hat{{\bf{F}}}_{{\cal{M}}_j}/n $ $ \hat{{\bf{V}}}_{{\cal{M}}_j} $ $ {\bf{X}}_{{\cal{M}}_j}^\top{\bf{X}}_{{\cal{M}}_j}/(np_j) $ $ {\bf{H}}_{{\cal{M}}_j}^\top=\hat{{\bf{V}}}_{{\cal{M}}_j}^{-1}(\hat{{\bf{F}}}_{{\cal{M}}_j}^\top{\bf{F}}_{{\cal{M}}_j}/n)({\bf{\Lambda}}^\top{\boldsymbol{\Lambda}}/p_j) $ $ {\bf{H}}_{{\cal{M}}}={{\rm{diag}}}({\bf{H}}_{{\cal{M}}_1},\dots,{\bf{H}}_{{\cal{M}}_{J_0}}) $ $ {\bf{H}}_{{\cal{M}}^c}={{\rm{diag}}}({\bf{H}}_{{\cal{M}}_{J_0+1}},\dots,{\bf{H}}_{{\cal{M}}_{J}}) $ $ {{\rm{diag}}}({\bf{H}}_{{\cal{M}}},{\bf{H}}_{{\cal{M}}^c}) $ $ {{\boldsymbol{\theta}}}^\star=(\theta_0^\star,({{\boldsymbol{\theta}}}^\star_{{\cal{M}}_1})^\top,\dots,({{\boldsymbol{\theta}}}^\star_{{\cal{M}}_q})^\top) $ $ {\cal{M}}=\{{\cal{M}}_j,||{{\boldsymbol{\theta}}}_{{\cal{M}}_j}^\star||_2\neq 0\} $ $ {\cal{M}}^c=\{{\cal{M}}_j, ||{{\boldsymbol{\theta}}}_{{\cal{M}}_j}^\star||_2=0\} $ $ {{\boldsymbol{\theta}}}^\star_{{\cal{M}}}=(\theta_0^\star,({{\boldsymbol{\theta}}}^\star_{{\cal{M}}_1})^\top,\dots,({{\boldsymbol{\theta}}}^\star_{{\cal{M}}_{J_0}})^\top)^\top $ $ {{\boldsymbol{\theta}}}^\star_{{\cal{M}}^c}=(({{\boldsymbol{\theta}}}^\star_{{\cal{M}}_{J_0+1}})^\top,\dots,({{\boldsymbol{\theta}}}^\star_{{\cal{M}}_{J}})^\top)^\top $ $ {{\rm{E}}}(y_i)=\mu_i=b'({\boldsymbol{F_i^\top}}{{\boldsymbol{\theta}}}^\star) $ $ {{\rm{var}}}(y_i)=\phi_0b''(\mu_i)=\phi_0b''({\boldsymbol{F_i^\top}}{{\boldsymbol{\theta}}}^\star) $ $ (b''({\boldsymbol{F}}_1^\top{{\boldsymbol{\theta}}}^\star),\dots,b''({\boldsymbol{F_n^\top}}{{\boldsymbol{\theta}}}^\star)) $ $ {\boldsymbol{\epsilon}}={\bf{y}}-b'({\bf{F}}{{\boldsymbol{\theta}}}^\star) $ $ {\boldsymbol{\varepsilon}}={\bf{W}}_0^{-1/2}({\bf{y}}-b'({\bf{F}}{{\boldsymbol{\theta}}}^\star)) $ $ {\boldsymbol{\delta}}=(\hat{{\bf{F}}}_{{\cal{M}}}-{\bf{F}}_{{\cal{M}}}{\bf{H}}_{{\cal{M}}}){\bf{H}}_{{\cal{M}}}^{-1}\theta^\star $ $ {\bf{C}}_{{\cal{M}}_j{\cal{M}}}=\lim_{n\to\infty}{\bf{H}}^\top_{{\cal{M}}_j}{\bf{F}}^\top_{{\cal{M}}_j}{\bf{W}}_0{\bf{F}}_{{\cal{M}}}{\bf{H}}_{{\cal{M}}} /n $ $ {\bf{C}}_{{\cal{M}}{\cal{M}}}=\lim_{n\to\infty}{\bf{H}}^\top_{{\cal{M}}}{\bf{F}}^\top_{{\cal{M}}}{\bf{W}}_0{\bf{F}}_{{\cal{M}}}{\bf{H}}_{{\cal{M}}}/n $ The following conditions facilitate the proofs of the theorems.
(A1) For all j, the group of variables
$ {\boldsymbol{X}}_{i,{\cal{M}}_j} $ $ {\boldsymbol{F}}_{i,{\cal{M}}_j} $ $ {\bf{\Lambda}}_{{\cal{M}}_j} $ $ {\boldsymbol{e}}_{i,{\cal{M}}_j} $ (A2) The scaled residual ε = (ε1, …, εn)T is a vector of IID variables, which satisfies that for all i, E(εi) = 0 , var(εi) = 1, and E(exp(tεi)) ≤ exp(τ0t2/2) for all t
$ \in $ $ \{F_{i,{\cal{M}}_j}\}_{1\leq j\leq p} $ $ \{e_{i,{\cal{M}}_j}\}_{1\leq j\leq p} $ $ n^{-\frac32}\sum_{i=1}^n||{\boldsymbol{F}}_{i,{\cal{M}}}^\top{\bf{H}}_{{\cal{M}}}{\bf{C}}_{{\cal{MM}}}^{-2}{\bf{H}}_{{\cal{M}}}^\top{\boldsymbol{F}}_{i,{\cal{M}}}||_2^3\to $ (A3) There is a positive constant c0 such that −c0 < miniηi ≤ maxiηi < c0, where
$ \eta_i={\boldsymbol{F_i^\top{\boldsymbol{\theta}}^\star}} $ $ i\in\{1,\dots,n\} $ $ c_1 $ $ |b'(\eta_i)-b'(\eta_j)|\leq c_1|\eta_i-\eta_j| $ $ |b''(\eta_i)-b''(\eta_j)|\leq c_1|\eta_i-\eta_j| $ $ i,j\in\{1,\dots,n\} $ $ \sigma_0 $ $ \sigma_0<\sigma_{\min }({\bf{C}}_{{\cal{M}}_j{\cal{M}}}^\top{\bf{C}}_{{\cal{M}}_j{\cal{M}}})\leq\sigma_{\max }({\bf{C}}_{{\cal{M}}_j{\cal{M}}}^\top{\bf{C}}_{{\cal{M}}_j{\cal{M}}})<\sigma_0^{-1} $ $ \sigma_0<\sigma_{\min }({\bf{C}}_{{\cal{M}}{\cal{M}}})\leq\sigma_{\max }({\bf{C}}_{{\cal{M}}{\cal{M}}})<\sigma_0^{-1} $ $ j\in\{1,\dots,J\} $ (A4) The concave penalty
$ \rho_\lambda(\cdot) $ $ a $ $ \rho_\lambda(||x||) $ $ ||x||\in[0,+\infty) $ $ \rho_\lambda(0)=0 $ $ \rho_\lambda(||x||) $ $ ||x||\in(0,+\infty) $ $ \rho_\lambda'(0):=\rho_\lambda'(0+). $ $ \rho_\lambda'(||x||)\geq a_1\lambda $ $ ||x||\in[0,a_2\lambda] $ $ \rho_\lambda'(||x||)=o(n^{-1/2}) $ $ ||x||\in[a\lambda,+\infty) $ $ a>a_2 $ (A5) The dimensions of the latent factors
$ \{K_j\} $ $ \{p_j\} $ $ p_j\asymp n $ $ j $ $ w_1,\dots,w_J $ $ J_0^2n^{-1}\to0 $ $ \lambda^{-1}\alpha_n\to0 $ $ \alpha_n=\max[(J_0/n)^{1/2},\{\log(J)/n\}^{1/2}] $ $ \ell_2 $ $ \ell_\infty $ $ c_0 $ $ \max_{j\in\{1,\dots,J_0\}}||{{\boldsymbol{\theta}}}_j||<c_0<\infty $ $ \min_{j\in\{1,\dots,J_0\}}\min_{s\in{\cal{M}}_j}|{{\boldsymbol{\theta}}}_{s,{\cal{M}}_j}|/\lambda\to\infty $ Condition (A1) presents the standard conditions of factor structure given by Fan et al.[30]. Condition (A2) demonstrates that we only pay attention to exponential family distributions where the noise term
$ \varepsilon_i $ $ \max_i {\rm{E}}(|\varepsilon_i|^3)=O(1) $ $ n^{-\frac32}\sum_{i=1}^n|{\boldsymbol{F}}_{i,{\cal{M}}}^\top{\bf{H}}_{{\cal{M}}}{\bf{C}}_{{\cal{MM}}}^{-2}{\bf{H}}_{{\cal{M}}}^\top{\boldsymbol{F}}_{i,{\cal{M}}}|_2^3\to0 $ $ {\bf{F}} $ $ {\boldsymbol{\Lambda}} $ $ {\bf{F}}^\top{\bf{F}}/n={\bf{I}}_K $ $ {\boldsymbol{\Lambda}}^\top{\boldsymbol{\Lambda}} $ $ {\bf{F}}{\bf{\Lambda}}^\top ={\bf{F}}{\bf{Q}}^{-1}{\bf{Q}}{\boldsymbol{\Lambda}} $ $ {\bf{Q}} $ $ {\bf{H}}^\top=(\hat{{\boldsymbol{\Lambda}}}^\top\hat{{\boldsymbol{\Lambda}}}/p)^{-1}(\hat{{\bf{F}}}^\top{\bf{F}}/n)({\boldsymbol{\Lambda}}^\top{\boldsymbol{\Lambda}}/p) $ $ \{{\bf{H}}_{{\cal{M}}_j}\} $ Theorem 1 (model selection consistency) Suppose that conditions (A1)-(A5) are satisfied. Let
$ {\cal{O}}_1(\hat{{\boldsymbol{\theta}}}) $ $ \hat{{\boldsymbol{\theta}}} $ $ ||\hat{{\boldsymbol{\theta}}}_{{\cal{M}}_j}||_2>0 $ $ j\in\{1,\dots,J_0\} $ $ {\cal{O}}_2(\hat{{\boldsymbol{\theta}}}) $ $ ||\hat{{\boldsymbol{\theta}}}_{{\cal{M}}_j}||_2=0 $ $ j\in\{J_0+1,\dots,J\} $ $ n\to\infty $ $ \Pr({\cal{O}}_1(\hat{{\boldsymbol{\theta}}})\cap{\cal{O}}_2(\hat{{\boldsymbol{\theta}}}))\to1. $ Theorem 2 (parameter estimation consistency) Suppose that conditions (A1)−(A5) are satisfied. Then, for the local minimizer
$ \hat{{\boldsymbol{\theta}}} $ $ ||\hat{{\boldsymbol{\theta}}}_{{\cal{M}}}-{\bf{H}}_{{\cal{M}}}^{-1}{{\boldsymbol{\theta}}}_{{\cal{M}}}^\star||_2=O_P(\sqrt{J_0/n}) $ $ \sqrt n(\hat{{\boldsymbol{\theta}}}_{{\cal{M}}}-{\bf{H}}_{{\cal{M}}}^{-1}{{\boldsymbol{\theta}}}_{{\cal{M}}}^\star)\stackrel{D}{\longrightarrow}{\cal{N}}({\bf{b}}_{{\cal{M}}},{\bf{C}}_{{\cal{M}}{\cal{M}}}^{-1}) $ $ {\bf{b}}_{{\cal{M}}}=\lim_{n\to\infty}\frac1{\sqrt{n}}{\bf{C}}_{{\cal{M}}{\cal{M}}}^{-1}{\bf{H}}_{{\cal{M}}}^\top{\bf{F}}_{{\cal{M}}}^\top{\bf{W}}_0{\boldsymbol{\delta}} $ Theorem 1 indicates that FAGES can achieve the model selection consistency. Theorem 2 points out the convergence rate and asymptotic normal distribution of
$ \hat{{\boldsymbol{\theta}}}_{{\cal{M}}} $ $ {{\boldsymbol{\theta}}}^\star $ $ {\bf{b}}_{{\cal{M}}} $ $ \hat{{\boldsymbol{\theta}}}_{{\cal{M}}}-{\bf{H}}_{{\cal{M}}}^{-1}{{\boldsymbol{\theta}}}_{{\cal{M}}}^\star $ $ n\to\infty $ $ \hat{{\boldsymbol{\theta}}}_{{\cal{M}}} $ $ ||{\bf{b}}_{{\cal{M}}}||^2_2=O_p(J_0) $ $ {\bf{C}}_{{\cal{M}}{\cal{M}}}^{-1} $ -
In this section, we make a comprehensive comparison between FAGES and the traditional group variable selection methods: group LASSO[4], group MCP[5], and GEL[8]. The difference between FAGES and the traditional approaches is that the latter methods directly predict the response using the standard GLM (Eq. [3]), while FAGES considers the grouped factor-augmented GLM (Eq. [8]). We illustrate that FAGES outperforms the traditional approaches even though the underlying model is the standard GLM (Eq. [3]) rather than the grouped factor-augmented GLM (Eq. [8]).
We set
$ p_1=\cdots=p_J $ $ K_1=\cdots=K_J $ $ {\bf{X}} $ $ {\bf{F}} $ $ {\bf{F}}=({\bf{F}}_{{\cal{M}}_1},\dots,{\bf{F}}_{{\cal{M}}_J}) $ $ {\cal{N}}(0,{R}_{K}(0.5)) $ $ K=\sum_jK_j $ $ {R}_{K}(r) $ $ r $ $ {\cal{M}}_j $ $ {\bf{e}}_{{\cal{M}}_j} $ $ {\cal{N}}(0,{R}_{p_j}(0.5)) $ $ {\bf{s}}_j=(s_j)_{p_j\times 1} $ $ {\boldsymbol{s\sim}}{\cal{U}}(0,1) $ $ {\boldsymbol{p}}_{{\cal{M}}_j}=({\bf{1}}, {\boldsymbol{p}}_{1},\dots,{\boldsymbol{p}}_{K_j-1}) $ $ {\boldsymbol{p}}_{k}=\sqrt 2\cos(k\pi{\boldsymbol{s}}) $ $ {\bf{D}}_{{\cal{M}}_j}= \text{diag}(2\sqrt 2,2,\sqrt 2) $ $ {\bf{\Lambda}}_{{\cal{M}}_j}={\boldsymbol{p}}_{{\cal{M}}_j}{\bf{D}}_{{\cal{M}}_j} $ $ {\bf{X}}_{{\cal{M}}_j}={\bf{F}}_{{\cal{M}}_j}{\bf{\Lambda}}_{{\cal{M}}_j}^\mathsf{T}+{\bf{e}}_{{\cal{M}}_j} $ $ {\cal{M}}=\bigcup_{j=1}^{J_0}{\cal{M}}_j $ We consider the following two scenarios:
● Scenario 1. Assume the grouped factor-augmented GLM (Eq. [8]) holds:
$ {{\rm{E}}}({\bf{y}})=b'({\bf{F}}{{\boldsymbol{\theta}}}^\star) $ $ {{\boldsymbol{\theta}}}^\star_{{\cal{M}}_j} $ $ {\cal{N}}(0,\sigma^2I_3) $ $ {\bf{F}}_{{\cal{M}}_j} $ ● Scenario 2. Assume the standard GLM (3) holds:
$ {{\rm{E}}}({\bf{y}})=b'({\bf{X}}{{\boldsymbol{\beta}}}^\star) $ $ {{\boldsymbol{\beta}}}^\star_{{\cal{M}}_j} $ $ {\bf{X}}_{{\cal{M}}_j} $ Scenario 1 is designed to simulate the real data, which have a factor structure in each group. FAGES is expected to outperform the traditional group variable selection approaches here. Scenario 2 is presented in order to investigate the robustness of FAGES. In this case,
$ {{\boldsymbol{\beta}}}^\star_{{\cal{M}}_j} $ The evaluation criteria include the prediction error (PE), the computing time, the proportion of true positives (TP), and the proportion of true negatives (TN). Specifically, the PE is
$ ||{\boldsymbol{\eta}}-\hat{{\boldsymbol{\eta}}}||_2/\sqrt n $ $ {\bf{F}}{{\boldsymbol{\theta}}}^\star $ $ {\bf{X}}{{\boldsymbol{\beta}}}^\star $ $ \hat{{\boldsymbol{\eta}}} $ $ \hat{{\bf{F}}}\hat{{\boldsymbol{\theta}}} $ $ {\bf{X}}\hat{{\boldsymbol{\beta}}} $ $\mathrm{grpreg}$ To isolate and examine the intrinsic statistical properties of FAGES, we begin with the simulation settings in which the true number of latent factors is known and is treated as oracle information. This design allows us to disentangle the intrinsic performance of FAGES from the additional variability introduced by factor dimension estimation. In the Supplementary Material (Supplementary Fig. S1−S4), we further compare the results obtained using the oracle factor dimension with those based on the proposed adaptive selection strategy that combines multiple criteria. We find that, at least under these idealized simulation settings, the adaptive strategy can consistently recover the true number of factors, leading to a performance that is nearly indistinguishable from the one achieved using the oracle factor dimension.
Example 1: Linear regression
-
We first consider the linear regression model, i.e.,
$ {\bf{y}}={\boldsymbol{\eta}}+{\boldsymbol{\epsilon}} $ $ {\boldsymbol{\epsilon}}=(\epsilon_1,\dots,\epsilon_n)^\top $ $ \epsilon_i\sim{\cal{N}}(0,1) $ $ {\bf{F}}{{\boldsymbol{\theta}}}^\star $ $ {\bf{X}}{{\boldsymbol{\beta}}}^\star $ 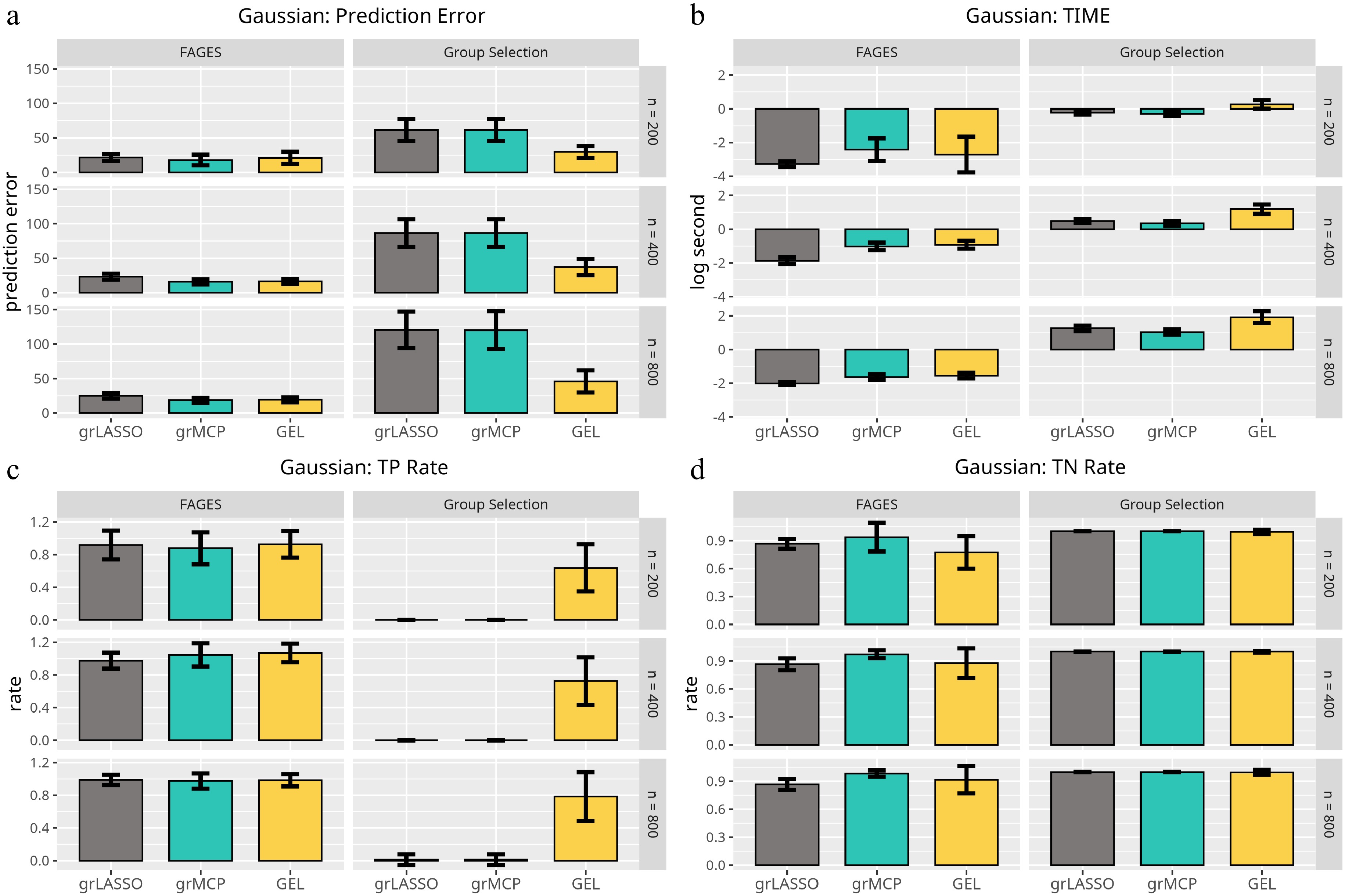
Figure 2.
Results of the linear model with respect to Scenario 1. Each panel represents a different evaluation metric: (a) prediction error, (b) computing time, (c) true negative rate, and (d) true positive rate. The height of each bar indicates the average value of the corresponding metric across multiple simulations, with error bars representing twice the standard deviation. The first three bars in each panel correspond to traditional methods, while the last three bars represent FAGES-based approaches with different penalty settings.
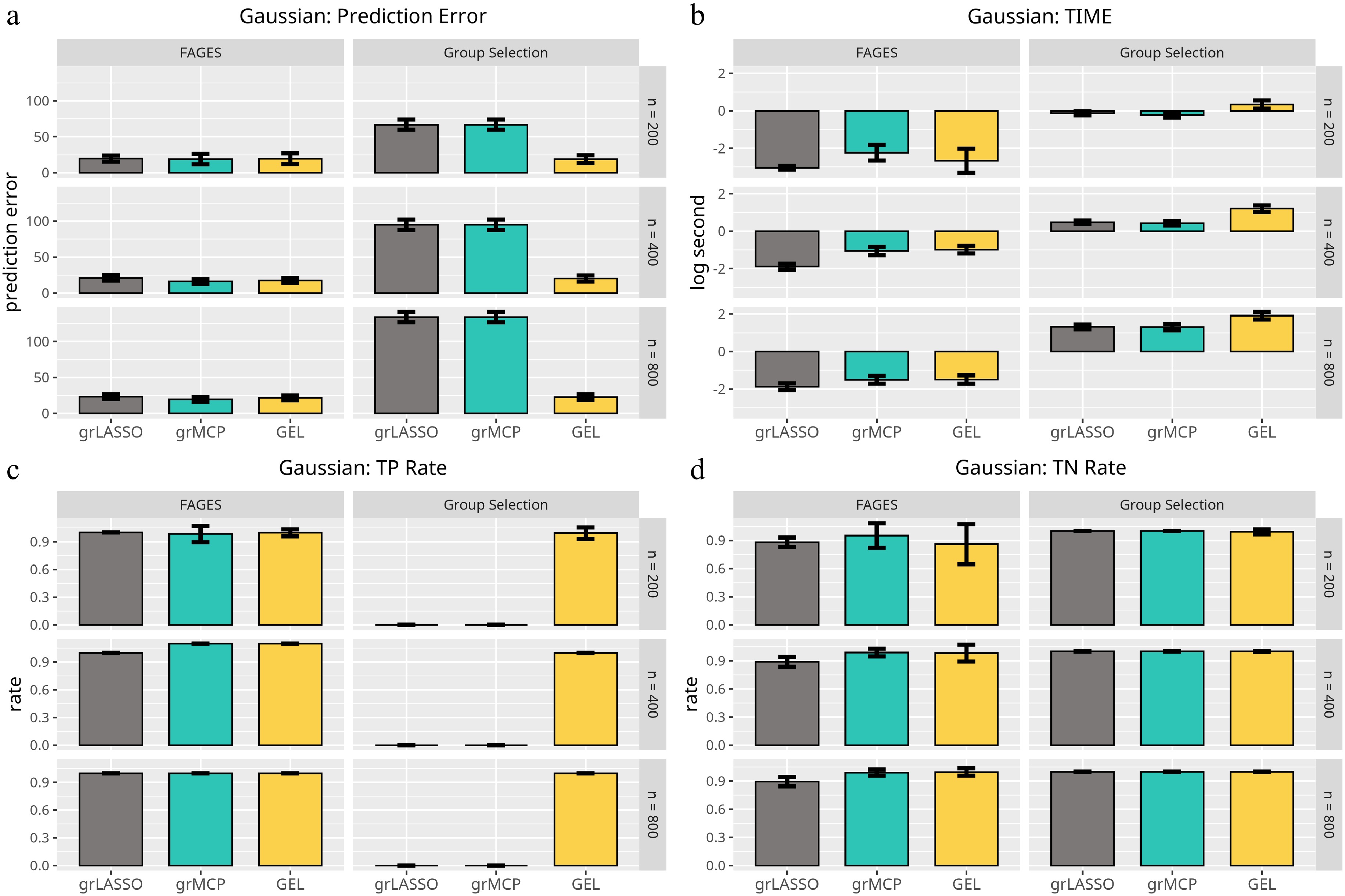
Figure 3.
Results of the linear model with respect to Scenario 2. Each panel represents a different evaluation metric: (a) prediction error, (b) computing time, (c) true positive rate, and (d) true negative rate. The height of each bar indicates the average value of the corresponding metric across multiple simulations, with error bars representing twice the standard deviation. The first three bars in each panel correspond to traditional methods, while the last three bars represent FAGES-based approaches with different penalty settings.
Our findings from Fig. 2 are as follows. In terms of the PE, FAGES performs uniformly better than the traditional methods, regardless of the group variable selection penalty applied. Besides, the traditional method with GEL is the only accurate method. Groups LASSO and grSCAD cannot select any group when the group size is very large. In terms of computing time, FAGES is computationally efficient than the traditional ones since it reduces the dimension of the GLM by the PCA before minimizing it. Regarding the TN, both the traditional methods and FAGES show high accuracy when concave penalties are used. For the TP, FAGES shows the top performance, followed by the traditional method with GEL, while the remaining two traditional methods show no power. In addition, FAGES cannot achieve the group selection consistency with the group LASSO penalty because this penalty lacks the oracle property[1].
In Fig. 3, we observe the following phenomena when the grouped factor-augmented GLM is misspecified. Traditional methods with GEL and FAGES are almost of the same accuracy in terms of PE. This phenomenon illustrates that FAGES is robust even when the underlying model is misspecified. As for TN and TP, the traditional approaches with GEL and FAGES are of the same accuracy. Regarding the computing time, FAGES is much faster than all three traditional methods, since it handles a model with a much lower dimension than the traditional methods. In summary, FAGES is still accurate when the underlying model is totally misspecified. In contrast, the traditional method performs well only when the GEL penalty is employed.
Example 2: Logistic regression
-
Now we investigate FAGES for binary responses under the logistic model:
$ {{\rm{E}}}({\bf{y}})=\exp({\boldsymbol{\eta}})/\{1+\exp({\boldsymbol{\eta}})\} $ $ {\boldsymbol{\eta}}={\bf{F}}{{\boldsymbol{\theta}}}^\star $ $ {\boldsymbol{\eta}}={\bf{X}}{{\boldsymbol{\beta}}}^\star $ $\mathrm{grpreg}$ $\mathrm{grpreg}$ From Fig. 4, we learn that FAGES uniformly outperforms the traditional methods in terms of all four criteria when the underlying model is correctly specified. However, it should be noted that, despite the fact that traditional approaches perform far worse even when GEL is applied as a group selector, FAGES does not produce ideal results because it is likely to ignore groups with non-zero effects. Only when n is sufficiently large can FAGES achieve the model selection consistency. Fig. 5 illustrates that FAGES is more accurate than the traditional methods in terms of the PE, even when the underlying model is misspecified. The underlying explanation for this occurrence is that the binary response carries less information than the continuous response and thus, it prefers the model with less degrees of freedom, even if the other model with more degrees of freedom is closer to the true model. Hence, we conclude that FAGES is powerful and robust to analyze the high-dimensional grouped variables, especially for the binary response, as FAGES is able to greatly reduce the dimension of the conventional GLM (Eq. [3]) without losing any key information.
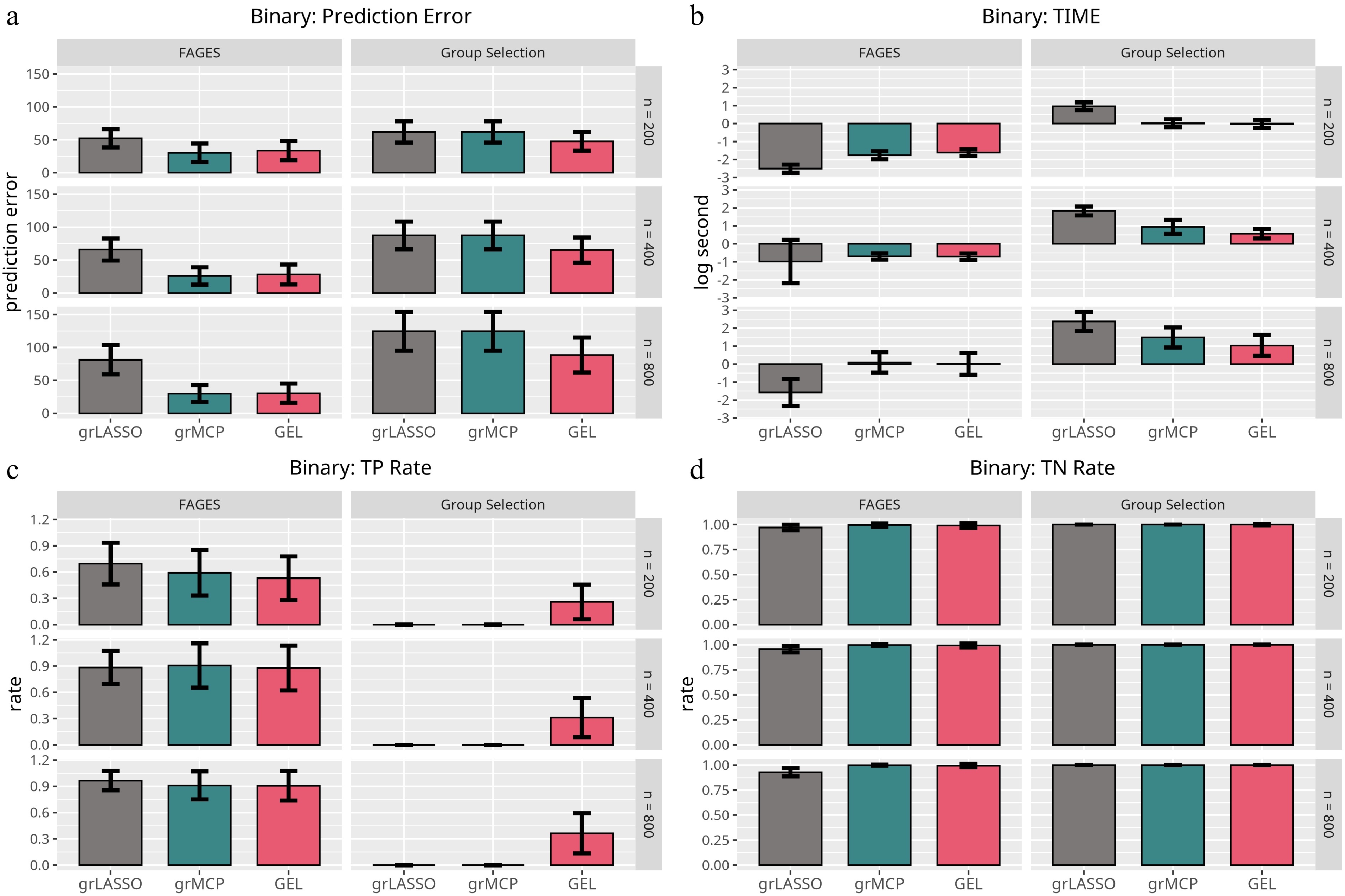
Figure 4.
Results of the logistic model with respect to Scenario 1. Each panel represents a different evaluation metric: (a) prediction error, (b) computing time, (c) true positive rate, and (d) true negative rate. The height of each bar indicates the average value of the corresponding metric across multiple simulations, with error bars representing twice the standard deviation. The first three bars in each panel correspond to traditional methods, while the last three bars represent FAGES-based approaches with different penalty settings.
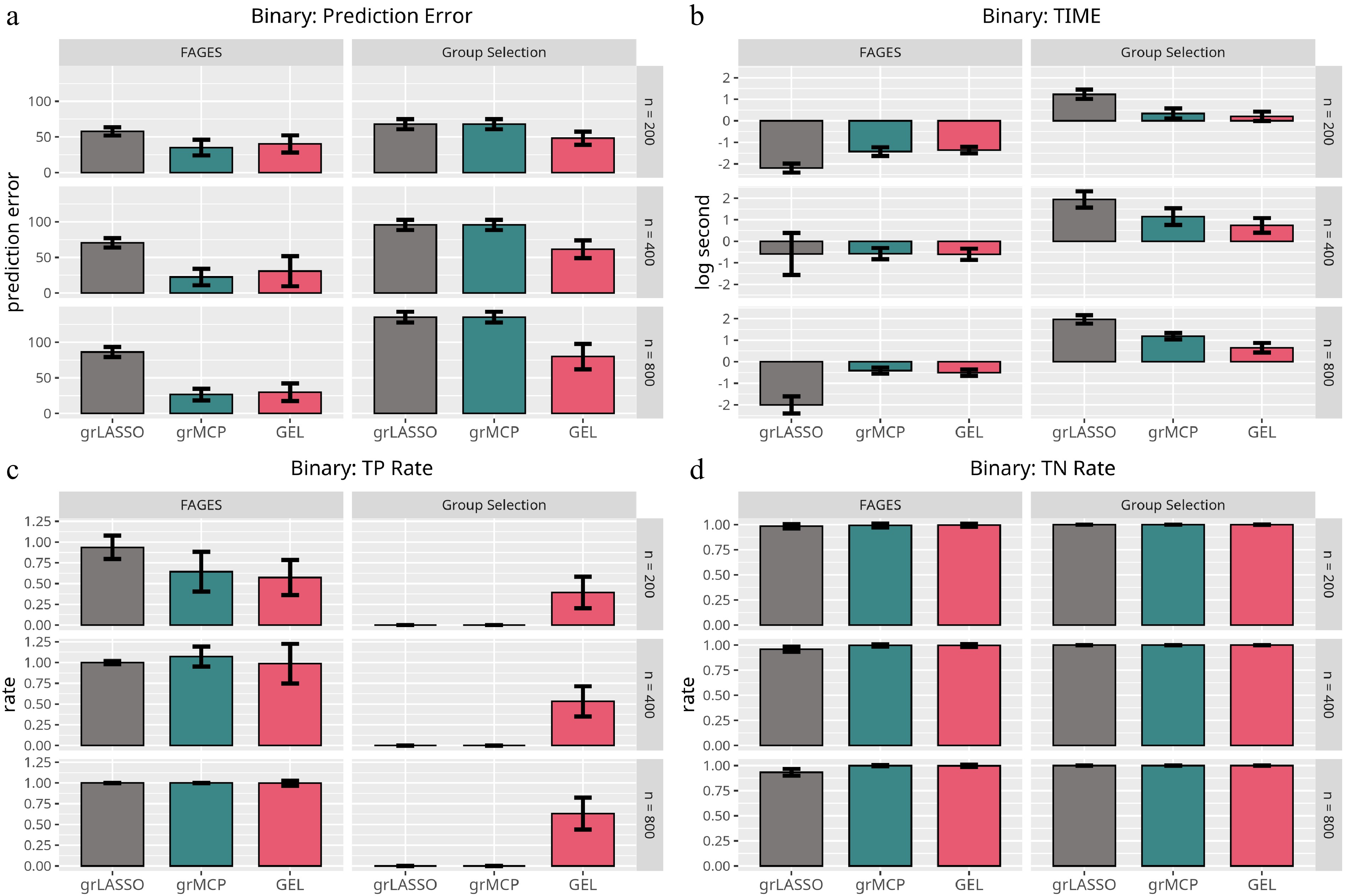
Figure 5.
Results of the logistic model with respect to Scenario 2. Each panel represents a different evaluation metric: (a) prediction error, (b) computing time, (c) true negative rate, and (d) true positive rate. The height of each bar indicates the average value of the corresponding metric across multiple simulations, with error bars representing twice the standard deviation. The first three bars in each panel correspond to traditional methods, while the last three bars represent FAGES-based approaches with different penalty settings.
Example 3: Functional regression
-
We consider a more complex case: the observed variables of each group are in the form of smooth functions. Consider the following functional AFM:
$ {\bf{X}}({\boldsymbol{t}})={\bf{F}}{\boldsymbol{\Lambda}}({\boldsymbol{t}})^\top+{\bf{e}}, $ (18) where, t = (t1, …, tp)T is a covariate like the time of observation, λ1(t) is a smooth function of t, and
$ {\boldsymbol{\Lambda}}({\boldsymbol{t}})=({\boldsymbol{\lambda}}_1({\boldsymbol{t}}),\dots,{\boldsymbol{\lambda}}_K({\boldsymbol{t}}))^\top $ $ {\boldsymbol{\Lambda}}({\boldsymbol{t}}) $ $ {\boldsymbol{\Lambda}}({\boldsymbol{t}}) $ $ {\boldsymbol{p_s}}({\boldsymbol{t}})=\sqrt{2}\cos(s\pi {\boldsymbol{t}}) $ $ {\boldsymbol{p}}({\boldsymbol{t}})=({\bf{1}},{\boldsymbol{p}}_1({\boldsymbol{t}}),\dots,{\boldsymbol{p_S}}({\boldsymbol{t}})) $ $ {\bf{P}}({\boldsymbol{t}})={\boldsymbol{p}}({\boldsymbol{t}}){\boldsymbol{p^\top}}({\boldsymbol{t}})/p $ $ S $ $ {\boldsymbol{\Lambda}}^\top({\boldsymbol{t}}){\bf{P}}({\boldsymbol{t}})\approx{\boldsymbol{\Lambda}}^\top({\boldsymbol{t}}) $ $ {\bf{e}}{\bf{P}}({\boldsymbol{t}})\approx0 $ $ \hat{{\bf{X}}}={\bf{X}}({\boldsymbol{t}}){\bf{P}}({\boldsymbol{t}}) $ $ \hat{{\bf{X}}}\hat{{\bf{X}}}^\top/n\approx{\bf{F}}\{{\boldsymbol{\Lambda}}({\boldsymbol{t}})^\top{\bf{P}}({\boldsymbol{t}}){\boldsymbol{\Lambda}}({\boldsymbol{t}})\}{\bf{F}}^\top/n. $ (19) Similar to the ordinal AFM, the first
$ K $ $ \hat{{\bf{X}}}\hat{{\bf{X}}}^\top/n $ $ \hat{{\bf{F}}}/\sqrt{ n} $ $ \hat{\Lambda}({\boldsymbol{t}})=\hat{{\bf{X}}}^\top\hat{{\bf{F}}}/\sqrt{n} $ Without losing generality, we set
$ p_1=\cdots=p_J $ $ {\bf{X}}_{{\cal{M}}_j}({\boldsymbol{t}}) $ $ {\bf{P}}({\boldsymbol{t}})={\boldsymbol{p}}({\boldsymbol{t}}){\boldsymbol{p^\top}}({\boldsymbol{t}})/p $ $ {\boldsymbol{p}}({\boldsymbol{t}})=({\bf{1}},{\boldsymbol{t}}_1({\boldsymbol{t}}),\dots,{\boldsymbol{t}}_9({\boldsymbol{t}})) $ $ \hat{{\bf{F}}}_{{\cal{M}}_j} $ $ \hat{{\bf{X}}}_{{\cal{M}}_j}={\bf{X}}_{{\cal{M}}_j}({\boldsymbol{t}}){\bf{P}}({\boldsymbol{t}}) $ The top three rows of Fig. 6 show the results of the linear model for functional data analysis. FAGES is clearly capable of handling the data that are in the form of smooth curves. FAGES accomplishes the model selection consistency with a high probability using the concave penalty no matter the sample size is large or small. The bottom three rows of Fig. 6 present the counterpart of the logistic regression model. FAGES is likely to ignore certain non-zero groups, consistent with the previous simulations. Only when the sample size is sufficiently large can FAGES achieve the model selection consistency.
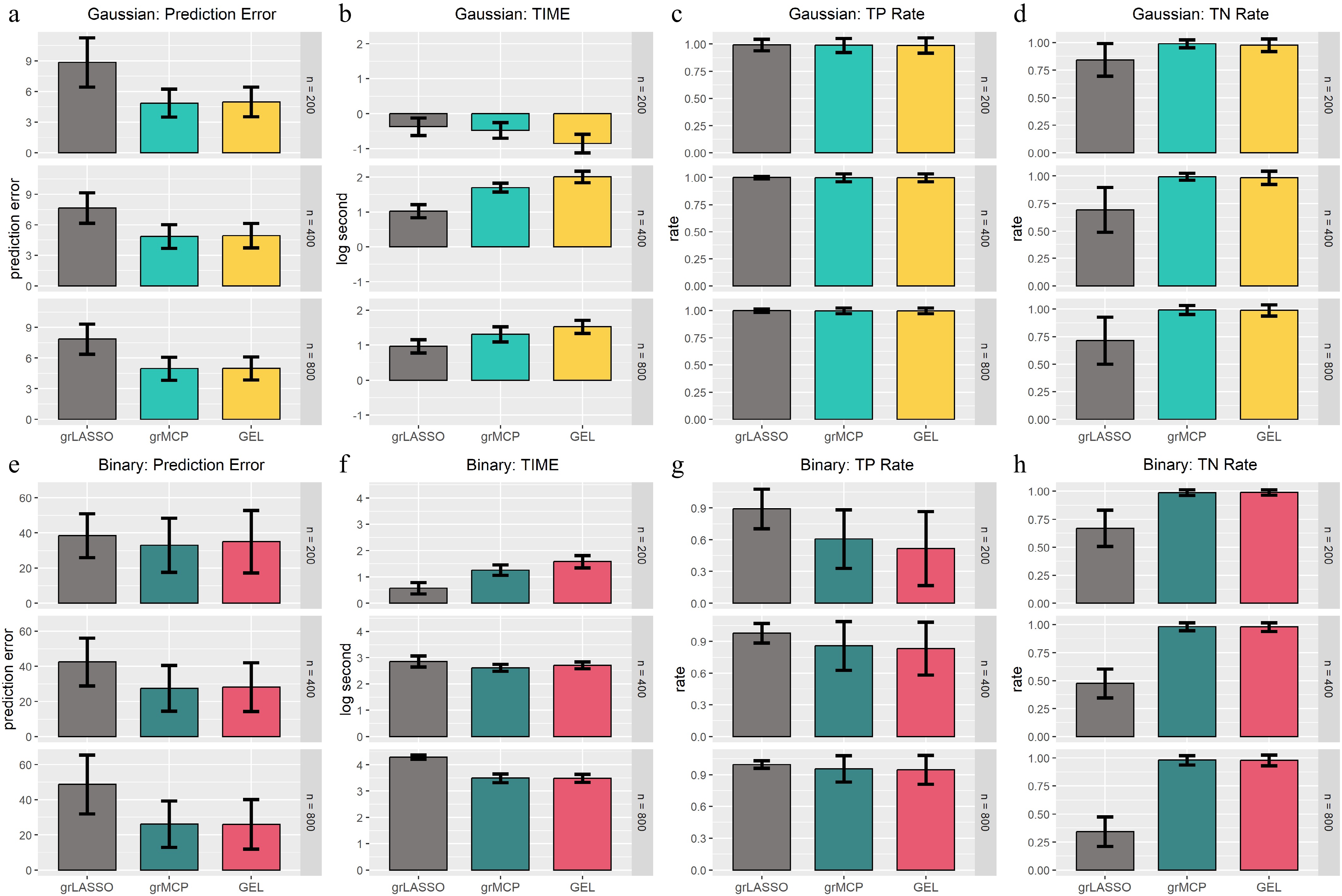
Figure 6.
Results of functional data analysis. The first four rows correspond to the Gaussian model, while the last four rows correspond to the binary model. Each column represents a different evaluation metric: (a), (e) prediction error; (b), (f) computing time; (c), (g) true negative rate; and (d), (h) true positive rate. The height of each bar indicates the average value of the corresponding metric across multiple simulations, with error bars representing twice the standard deviation. Different methods are compared, with the first set of bars corresponding to traditional approaches and the latter set representing FAGES-based methods with different penalty settings.
Real-data analysis
Data
-
In this section, we demonstrate the analysis of the HNSCC data through FAGES. We first give a description of the data and related concepts and then show the results of the analysis. The HNSCC data are provided by the cancer genome atlas (TCGA) program and can be found on the website UCSC Xena (
https://xenabrowser.net/datapages ). The website contains data related to n = 520 patients and 20,530 genes, which show the gene-level transcription estimates, as in the log2(x+1)-transformed RSEM normalized count. The gene "Ki67" is considered the response variable because it is the indicator gene in many biological researches. For example, "Ki67" may be necessary for cellular proliferation; it is involved in maintaining the individual mitotic chromosomes dispersed in the cytoplasm following nuclear envelope disassembly; and higher expression of "Ki67" is related to a poor prognosis of cancer[35,36].A pathway is a kind of gene set commonly used in biological researches. There are more than 20,000 genes in humans, and their molecular functions are based on the so-called biological pathways, which host a series of interactions among genes or molecules in a cell that lead to a biological function. KEGG is a kind of pathway database built for understanding the high-level functions and utilities of the biological system from gene-level or molecular-level information, especially large-scale molecular datasets generated by genome sequencing and other high-throughput experimental technologies[37].
The KS random walk method[9] is applied to convert the gene expressions into an individualized KS curve that reflects the enrichment of a target gene set. Suppose there is a matrix of expression profiles
$ {\bf{V}}=(V_{ij})_{n\times p} $ $ {\boldsymbol{X}}_{il,{\cal{M}}_j}=\dfrac{\sum_{h=1}^l|S_{ih}| {\bf{1}}(h\in{\cal{M}}_j)}{\sum_{h=1}^p|S_{ih}|{\bf{1}}(h\in{\cal{M}}_j)}-\dfrac{\sum_{h=1}^l {\bf{1}}(h\notin{\cal{M}}_j)}{p-|{\cal{M}}_j|}, $ (20) where,
$ {\bf{1}}(h\in{\cal{M}}_j) $ $ {\cal{M}}_j $ $ |{\cal{M}}_j| $ $ j $ $ {\boldsymbol{X}}_{il,{\cal{M}}_j} $ $ {\cal{M}}_j $ Analysis
-
We consider the KEGG pathways as gene sets and utilize the KS random walk approach to generate the individualized KS curves for every pathway. Besides, we assume the individualized KS curves to follow an AFM (Eq. [7]) in each pathway, and use the projection-PCA to estimate the related latent factor. Without loss of generality, the dimensions of the latent factors are uniformly set as 3 and only the 1st,..., 1027th quantiles of each KS curve are recorded. We use the penalized likelihood (Eq. [15]) to handle the grouped factor-augmented GLM (Eq. [8]). The averaged group effect is computed through Eq. (16) and the effect direction is determined based on Eq. (17).
Figure 7 demonstrates the identified pathways and the related pathway effects using FAGES. First of all, FAGES with the two different penalties identifies many consistent pathways, including Toxoplasmosis, TGF-beta, Staphylococcus aureus infection, Progesterone edited oocyte maturation, etc. Besides, FAGES with the GEL identifies ten more important pathways than FAGES with the grMCP because of GEL's flexibility. The cell cycle and TGF-beta are the two pathways that have the most significant averaged group effects in both methods. The cell cycle pathway, which regulates DNA synthesis and mitosis during tumor cell proliferation, is recognized to be positively associated with tumor cell proliferation[38]. The TGF-beta pathway, consistent with previous reports, has a strongly negatively averaged group effect on cell proliferation, implying that the activation of this pathway might compromise tumor proliferation[39]. Furthermore, pathways with considerable averaged group effects, such as prostate cancer, toxoplasmosis, amino sugar and nucleotide sugar metabolism, and inositol phosphate metabolism, warrant further investigation. In this process, FAGES acts as a screen that removes the noisy genes in a more statistically valid and biologically understandable manner.
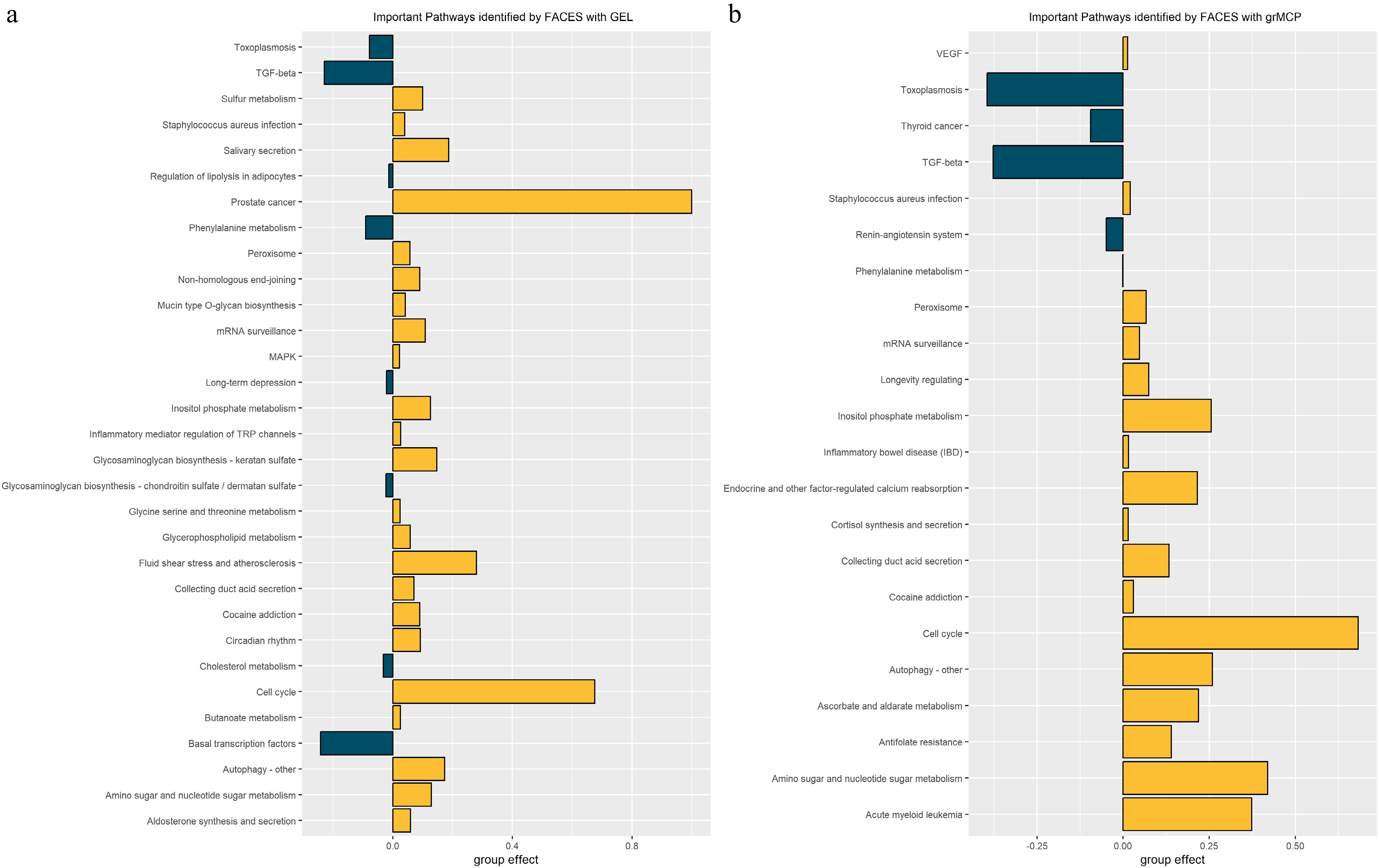
Figure 7.
Important pathways identified by FAGES with different penalty functions. (a) shows the results obtained using GEL, while (b) displays the results yielded by grMCP. The bars represent the estimated averaged group effect for each selected pathway, with the pathway names shown on the y-axis. Green bars indicate pathways that are positively associated with the outcome, while yellow bars indicate pathways that are negatively associated with the outcome.
-
In this paper, we introduce a two-stage method called FAGES for identifying important variable groups within the framework of GLM. Methodologically, FAGES first addresses within-group correlations by modeling each group of variables with an AFM. Each group is assumed to be driven by a few latent factors together with idiosyncratic components, with the latent factors capturing the dominant variation[18]. By representing groups through their latent factors, FAGES reduces dimensionality and specifies a grouped factor-augmented GLM in which these latent factors are entered as predictors associated with the outcome. A variable selection penalty is then applied to simultaneously identify relevant groups and estimate their corresponding regression coefficients. For inference, FAGES quantifies the strength of the selected groups through an averaged group effect estimate (Eq. [16]), which provides a comparable measure of the group contribution.
In our simulations, we found that grMCP performs slightly better than GEL. This is not surprising. Under idealized settings, grMCP does not impose an explicit bi-level selection structure and can therefore exploit the group information more efficiently, which may translate into higher power. However, prior empirical evidence in the literature suggests that, in real-data applications, GEL tends to be more robust to heterogeneous within-group correlation patterns and model misspecification[8]. Hence, we recommend GEL as the default choice in practice, and view grMCP as a competitive alternative when the signal is sufficiently strong and the group structure is well aligned with the assumed model.
As an application of FAGES, we show how to enhance GSVA by using FAGES in real-data analysis. Traditional GSVA relies on a single summary statistic, such as the maximum deviation or maximum difference statistic, to extract information from the KS curve[9]. We propose leveraging the leading FPCs of the KS curve to more effectively capture the contribution of gene sets to the outcome, and estimate the direct effect of a gene set on the outcome conditional on other gene sets. Beyond this application, we further hypothesize that FAGES can benefit Mendelian randomization (MR) analyses based on rare variants[40,41]. Specifically, we propose to ① construct a weighted kernel matrix for rare variants within a genomic region based on SKAT[42], and ② apply PCA to extract the leading kernel-weighted PCs. Furthermore, we can ③ select key genomic regions and estimate the effects of their PCs on both the exposure and the outcome, which can serve as instrument variables (IVs) in MR, and ④ ultimately perform MR to assess whether the exposure causally influences the outcome through the rare variants. For example, rare loss-of-function variants in ANGPTL3 have been associated with a decreased risk of cardiovascular diseases[43], while the common cis protein quantitative trait locus (pQTL) of ANGPTL3 abundance showed no causality[44]. In the future, we can investigate whether lipid traits, such as triglyceride, mediate their effect on ASCVD through rare loss-of-function ANGPTL3 variants by using a FAGE-based MR analysis.
Several limitations of the present study should be acknowledged. First, in the real-data analysis, we chose Ki67 expression as the response variable. Although Ki67 is a well-established marker of cellular proliferation and is widely recognized as a prognostic indicator in oncology[35,36], modeling the expression level of a single gene is less conventional in GSA. Thus, this application should be viewed mainly as a proof-of-concept illustration of FAGES. Second, the two-stage estimation procedure, which first extracts latent factors and then applies penalized regression, may introduce additional variability and potential heteroskedasticity[45]. Moreover, we did not include direct comparisons with classical GSA methods (e.g., AUCell[46] and PAGODA[47]), because these approaches are marginal by design, while our aim is to advance group variable selection methods that estimate the conditional effects in a regression framework.
We would like to thank the editors and the anonymous referees for their very careful reviews and suggestions.The first author would like to thank Dr. Jianxin Pan and Dr. Hao Xu for their multiple inspiring discussions.
-
The author confirms sole responsibility for all aspects of this study and approved the final version of the manuscript.
-
All data generated or analyzed during this study are included in this published article and its supplementary materials.
-
The author declares that there is no conflict of interest.
-
accompanies this paper online at: https://doi.org/10.48130/stati-0026-0007.
- Supplementary Fig. S1 Results of the linear model with respect to Scenario 1.
- Supplementary Fig. S2 Results of the linear model with respect to Scenario 2.
- Supplementary Fig. S3 Results of the logistic model with respect to Scenario 1.
- Supplementary Fig. S4 Results of the logistic model with respect to Scenario 2.
- Copyright: © 2026 by the author(s). Published by Maximum Academic Press, Fayetteville, GA. This article is an open access article distributed under Creative Commons Attribution License (CC BY 4.0), visit https://creativecommons.org/licenses/by/4.0/.
-
About this article
Cite this article
Yang Y. 2026. Factor-augmented group effect selection with application to gene set analysis. Statistics Innovation 3: e007 doi: 10.48130/stati-0026-0007 

Factor-augmented group effect selection with application to gene set analysis
- Received: 30 January 2026
- Revised: 31 January 2026
- Accepted: 19 March 2026
- Published online: 29 May 2026
Abstract: This paper addresses the problem of group variable selection when both the number of groups and the number of variables within each group are large. We propose the factor-augmented group effect selection (FAGES) method, which simultaneously identifies important groups, provides comparable estimates of group effect sizes, and determines the directions of these effects. The key idea is to assume that a low-dimensional latent factor captures the major information within each group and to apply a variable selection penalty to these factors in order to select relevant groups and estimate their effects. We establish the consistency of both parameter estimation and model selection under moderate conditions. Simulation studies demonstrate that FAGES can reliably recover significant groups and estimate their effects, even when the working model is misspecified. In practice, FAGES can be applied to gene set analysis to identify important biological pathways and quantify their direct effects. Using head and neck squamous cell carcinoma data, we illustrate the practical utility of FAGES by detecting multiple pathways implicated in disease development.
-
Key words:
- Factor model /
- Factor-augmented regression /
- Gene set analysis /
- Variable selection