








-
Feature selection is a fundamental topic of research in statistics and machine learning, as it improves predictive accuracy, enhances interpretability, and reduces computational costs by eliminating irrelevant or redundant variables. Consequently, it has been widely used in real-world data analysis across various application domains.
Several methods for variable selection have been proposed for both parametric and nonparametric models. The classical techniques include the
$ \ell_0 $ $ \ell_1 $ Being a fundamental component of deep learning, neural networks have undergone significant theoretical and empirical advances, and can now be used to approximate complex data structures and tackle intricate modeling tasks[12−16]. However, neural networks are often over-parameterized, posing challenges for training, prediction, and interpretation. Several methods have been developed to reduce the number of model parameters and compress network architectures in order to enhance the predictive performance. A widely adopted solution is dropout[17], which randomly drops nodes during training to prevent overfitting. Subsequently, sparse neural networks have been proposed to reduce the number of parameters and compress model architectures. The existing research on sparse neural networks falls into two categories: Bayesian and frequentist. Within the Bayesian framework, various sparsity-inducing priors, such as the hierarchical prior[18,19], the mixture Gaussian prior[20], and the spike-and-slab prior[21], have been proposed for learning sparse Bayesian neural networks. In the frequentist framework, the group
$ \ell_1 $ Although the existing methods encourage sparsity in the weight matrix and compress the network architectures, few methods directly address the sparse-input problem. However, these methods are not specifically designed for variable selection. To identify the important covariates in neural network models, several nonlinear variable selection techniques have been proposed. First, the group
$ \ell_1 $ $ \ell_0 $ $ \ell_1 $ $ \ell_0 $ $ \ell_0 $ However, the current neural network-based variable selection methods face challenges in both variable selection accuracy and predictive performance. First, these
$ \ell_1 $ $ \ell_1 $ $ \ell_0 $ Just like the
$ \ell_1 $ $ \ell_0 $ $ \ell_0 $ $ \ell_0 $ $ \ell_1 $ In comparison with the IHT algorithm, which is based on deterministic learning[31], we propose the multistage stochastic iterative hard-thresholding (StoIHT) algorithm. The proposed methods, which are based on stochastic learning algorithms, are used to select important variables by estimating the weights connecting the input and the first hidden layer. Then, we develop a novel variable selection method with an annealing strategy within the framework of a multistage stochastic algorithm[36]. This approach can help in substantially enhancing both variable selection and prediction accuracy. To simplify the discussion and provide a clear description of our methodology, we will focus on shallow neural networks in this article. Furthermore, we investigate the criteria for variable selection and develop a novel Bayesian information criterion (BIC) tailored to the high-dimensional setting (the large-p−small-n scenario), along with the conventional BIC for the low-dimensional setting (n > p scenario)[37]. The main contributions of this paper are as follows:
(1) This article proposes two novel variable selection methods that use neural networks as surrogate models with a group
$ \ell_0 $ (2) This paper develops a novel BIC for model selection in the high-dimensional setting. Numerical experiments demonstrate that the proposed criterion helps to substantially improve variable selection accuracy relative to the conventional BIC.
The remainder of this paper is organized as follows. The next section introduces the notation and outlines the model framework. The section "Methodology" presents the proposed variable selection approaches based on a stochastic optimization strategy. The section "Simulation" assesses the performance of the proposed methods through numerical experiments and real data applications. The last section provides the conclusions and discusses the potential directions for future research.
-
Given a collection of independent training instances
$ \{({\bf{x}}_i, y_i)\}_{i=1}^n $ $ {\bf{x}}_i \in \mathbb{R}^{p_0} $ $ y_i \in \mathbb{R} $ $ y_i = f^*( {\bf{x}}_i) + \epsilon_i, \quad \epsilon_i \sim {\cal{N}}(0, \sigma^2), $ (1) where,
$ f^* $ $ {\bf{x}}_i $ $ y_i $ $ \epsilon_i $ $ f^* $ $ S^* \subset \{1, 2, \ldots, p_0\} $ $ |S^*| = k^* \ll p_0 $ $ k^* $ $ \log\left(\dfrac{\mathbb{P}(y_i = 1 \mid {\bf{x}}_i)}{\mathbb{P}(y_i = 0 \mid {\bf{x}}_i)}\right) = f^*({\bf{x}}_i), $ (2) where,
$ f^* $ $ {\bf{x}}_i $ $ y_i \in \{0,1\} $ $ f^* $ $ (d, C) $ Definition 2.1. Let d = q + ζ, where
$ \zeta \in $ $ \left\lfloor d \right\rfloor \in \mathbb{N}_0 $ $ \mathbb{N}_0 $ $ f:\mathbb{R}^{p_0} \rightarrow \mathbb{R} $ $ (d, C) $ $ {{\boldsymbol{\alpha}}} = (\alpha_1, \alpha_2, \cdots, \alpha_{p_0})^{\top} \in \mathbb{N}^{p_0}_0 $ $ \sum_{j=1}^{p_0}\alpha_j = q $ $ \partial^{q}f/\partial x_{1}^{\alpha_1}\partial x_{2}^{\alpha_2} \cdots \partial x_{p_0}^{\alpha_{p_0}} $ $ \left|\dfrac{\partial^{q}f}{\partial x_{1}^{\alpha_1}\partial x_{2}^{\alpha_2} \cdots \partial x_{p_0}^{\alpha_{p_0}}}( {\bf{x}}_1) - \dfrac{\partial^{q}f}{\partial x_{1}^{\alpha_1}\partial x_{2}^{\alpha_2} \cdots \partial x_{p_0}^{\alpha_{p_0}}}( {\bf{x}}_2)\right| \leq C\| {\bf{x}}_1 - {\bf{x}}_2\|^{\zeta}_2, $ for all
$ {\bf{x}}_1, {\bf{x}}_2 \in \mathbb{R}^{p_0} $ $ \|\cdot\|_2 $ $ \ell_2 $ In this paper, we aim to estimate the index set
$ S^* $ $ f^* $ $ f^* $ $ {\cal{H}}_{p_1, \varphi} $ $ p_1 $ $ {\cal{H}}_{p_1, \varphi} = \left\{ {{\boldsymbol{\omega}}}^{\top}_2\varphi( {\bf{W}}_1 {\bf{x}} + {\bf{b}}_1) + b_2: b_2 \in \mathbb{R}, {{\boldsymbol{\omega}}}_2, {\bf{b}}_1 \in \mathbb{R}^{p_1}, {\bf{W}}_1 \in \mathbb{R}^{p_1 \times p_0} \right\}. $ Therefore, models (1) and (2) can be approximated as
$ y_i \approx { {{\boldsymbol{\omega}}}_2}^{\top}\varphi( {\bf{W}}_1 {\bf{x}}_i+ {\bf{b}}_1) + b_2 + \epsilon_i, $ and
$ \log\left(\dfrac{\mathbb{P}(y_i = 1 \mid {\bf{x}}_i)}{\mathbb{P}(y_i = 0 \mid {\bf{x}}_i)}\right) \approx { {{\boldsymbol{\omega}}}_2}^{\top}\varphi( {\bf{W}}_1 {\bf{x}}_i+ {\bf{b}}_1) + b_2, $ respectively, where
$ {\bf{W}}_1 \in \mathbb{R}^{p_1 \times p_0} $ $ {\bf{b}}_1 \in \mathbb{R}^{p_1} $ $ {{\boldsymbol{\omega}}}_2 \in \mathbb{R}^{p_1} $ $ b_2 \in \mathbb{R} $ $ \varphi:\mathbb{R}^{p_1} \rightarrow \mathbb{R}^{p_1} $ $ ReLU $ $ \varphi(x) = \max\{x,0\} $ $ \ell(y_i, f( {\bf{x}}_i)) $ $ ( {\bf{x}}_i, y_i) $ $ f( {\bf{x}}_i) = {{\boldsymbol{\omega}}}^{\top}_2\varphi( {\bf{W}}_1 {\bf{x}}_i+ {\bf{b}}_1) + b_2 $ $ L( {\bf{W}}_1, {\bf{b}}_1, {{\boldsymbol{\omega}}}_2, b_2) = \dfrac{1}{n}\sum\limits_{i=1}^{n}\ell\left( y_i,f( {\bf{x}}_i; {\bf{W}}_1, {\bf{b}}_1, {{\boldsymbol{\omega}}}_2,b_2) \right). $ We propose the following optimization problem with a sparsity constraint on the weight matrix to address the feature selection problem:
$ \min\limits_{ {\bf{W}}_1, {\bf{b}}_1, {{\boldsymbol{\omega}}}_2,b_2}\dfrac{1}{n}\sum\limits_{i=1}^{n}\ell(y_i,f( {\bf{x}}_i; {\bf{W}}_1, {\bf{b}}_1, {{\boldsymbol{\omega}}}_2,b_2)), \quad \| {\bf{W}}_1\|_{2,0} \leq k, $ (3) where,
$ \| {\bf{W}}_1\|_{2,0} = \#\{j:\| {\bf{w}}_{\cdot j}\|_2 \neq 0, j = 1, 2, \cdots, p_0\} $ $ {\bf{w}}_{\cdot j} $ $ {\bf{W}}_1 $ $ \| {\bf{W}}_1\|_{2,0} $ $ {\bf{W}}_1 $ $ {\bf{W}}_1 $ It is worth noting that the group
$ \ell_0 $ $ {\bf{w}}_{\cdot j} $ $ {\bf{w}}_{\cdot j} $ $ \ell_0 $ $ f^{*} $ $ f^{*} $ $ (d, C) $ $ p_{1} $ 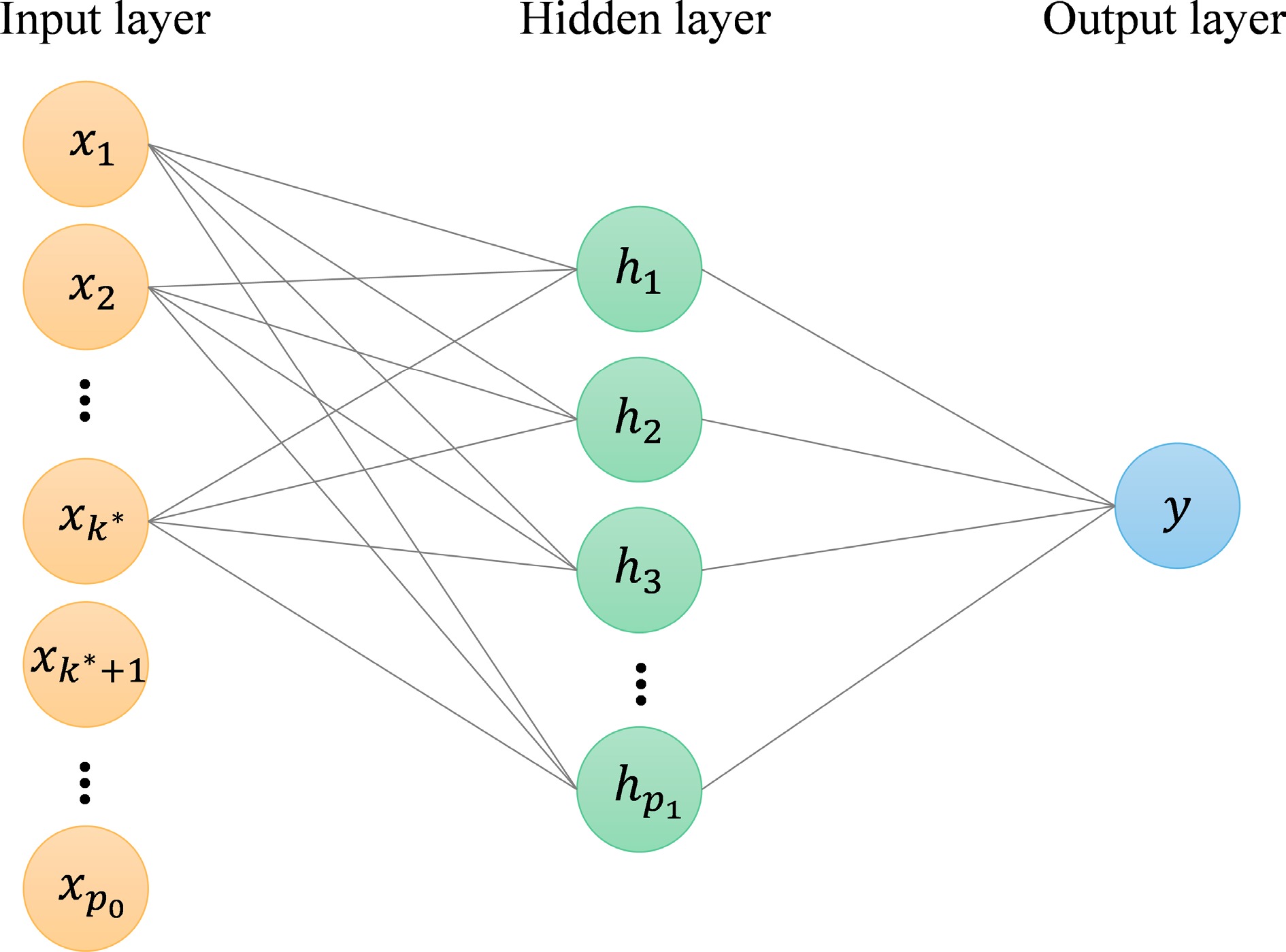
Figure 1.
The architecture of a one-hidden-layer neural network derived using the group $ \ell_0 $ penalty is illustrated. For simplicity, the bias terms are omitted. The figure shows that there are no edges between the input nodes $ {x_{k^*+1}, \cdots , x_{p_0}} $ and the neurons in the hidden layer, indicating that the $ (k^*+1) $-th to $ p_0 $-th column vectors of $ {\bf{W}}_1 $ are zeros. This sparsity pattern is induced by the group $ \ell_0 $ penalty.
We now delineate the notations used throughout the paper. Vectors are denoted by lowercase bold letters, such as
$ {\bf{x}} \in \mathbb{R}^d $ $ x \in \mathbb{R} $ $ {\bf{w}}_1, {\bf{w}}_2, \ ... $ $ w_j $ $ {\bf{M}} \in \mathbb{R}^{d \times d} $ $ {{\boldsymbol{\gamma}}} = (\gamma_1, \gamma_2, \cdots, \gamma_n)^{\top} \in \mathbb{R}^n $ $ \| {{\boldsymbol{\gamma}}}\|_1 = \sum_{i=1}^{n} |\gamma_i| $ $ \| {{\boldsymbol{\gamma}}}\|_2 = \sqrt{\sum_{i=1}^{n} \gamma_i^2} $ $ \| {{\boldsymbol{\gamma}}}\|_0 = \#\{i : \gamma_i \neq 0\} $ -
In the section "Setting and notation," we introduce the feature selection problem and derive the corresponding constrained optimization problem (Eq. [3]) using a one-hidden-layer neural network as a surrogate model. In this section, we propose two variable selection methods within a multistage stochastic learning framework to solve the constrained optimization problem (Eq. [3]). To mitigate the risk of gradient descent converging to local optima, we first extend the IHT algorithm[31,32] to a multistage StoIHT algorithm[38] to train a one-hidden-layer neural network. Next, we develop a variant of StoIHT that uses an annealing strategy for variable selection, known as feature selection with annealing (FSA). Compared with the existing IHT method, the proposed multistage StoIHT and multistage FSA methods show a superior overall performance on regression and classification tasks, as validated by numerical experiments.
Multistage stochastic IHT
-
We begin by introducing the multistage stochastic learning framework. In the stochastic algorithm, each iteration operates on only a mini-batch of the data set, dividing the training process into distinct stages, each comprising several iterations. This staged training structure enables the use of different learning rates and other hyperparameters across stages. The output of the current training stage is used as the initial value for the subsequent stage. In neural network training, a stage can naturally correspond to a single epoch.
Then, we introduce the StoIHT algorithm within a multistage framework. The algorithm consists of Niter stages. In each stage, the stochastic gradient descent (SGD) algorithm updates model parameters using only a mini-batch of data per iteration, thereby introducing randomness into the parameter updates. Consequently, applying a hard-thresholding operator immediately after each iteration may yield poor variable selection performance[39]. To address this issue, we apply the hard-thresholding operator after all the SGD iterations within a stage are complete, thereby stabilizing the variable selection procedure. Recall that the hard-thresholding operator selects the top-k column vectors of the weight matrix
$ {\bf{W}}_1 $ $ \ell_2 $ Table 1. Multistage StoIHT algorithm.
Input: Standardized training data $ \{( {\bf{x}}_i,y_i)\}_{i=1}^n $, initial learning rate $ \eta_0 $, sparse level k, and total iteration times $ N_{iter} $. Output: Trained weights $ {\bf{W}}_1 $, $ {\bf{b}}_1 $, $ {{\boldsymbol{\omega}}}_2 $ and $ b_2 $. Initialize $ {\bf{W}}_1^{(1, 1)} $, $ {\bf{b}}^{(1, 1)}_1 $, $ {{\boldsymbol{\omega}}}^{(1, 1)}_2 $, $ b^{(1, 1)}_2 $. for $ t = 1 $ to $ N_{iter} $ do Shuffle the training data $ \{( {\bf{x}}_i,y_i)\}_{i=1}^n $, and relabel $ i = 1, 2, \cdots, n $. for $ i = 1 $ to n do $ {{\boldsymbol{\omega}}}^{(t,i+1)}_2 \leftarrow {{\boldsymbol{\omega}}}^{(t,i)}_2 - \eta_t\dfrac{\partial \ell(y_i, f( {\bf{x}}_i;\cdots))}{\partial {{\boldsymbol{\omega}}}_2} $, $ b^{(t,i+1)}_2 \leftarrow b^{(t,i)}_2 - \eta_t\dfrac{\partial \ell(y_i, f( {\bf{x}}_i;\cdots))}{\partial b_2} $, $ {\bf{W}}^{(t,i+1)}_1 \leftarrow {\bf{W}}^{(t,i)}_1 - \eta_t\dfrac{\partial \ell(y_i, f( {\bf{x}}_i;\cdots))}{\partial {\bf{W}}_1} $, $ {\bf{b}}^{(t,i+1)}_1 \leftarrow {\bf{b}}^{(t,i)}_1 - \eta_t\dfrac{\partial \ell(y_i, f( {\bf{x}}_i;\cdots))}{\partial {\bf{b}}_1} $, end for Let $ {\bf{W}}^{(t)}_1 = {\bf{W}}^{(t,n+1)}_1 $. Denote $ {\bf{w}}^{(t)}_{\cdot j} $ as the j-th column for $ {\bf{W}}^{(t)}_1 $. Ranking $ \{\| {\bf{w}}^{(t)}_{\cdot j}\|_2\} $ in descending order, and retaining the index set $ \hat{S}^{(t)} $ corresponding to top-k largest values of $ \{\| {\bf{w}}^{(t)}_{\cdot j}\|_2\} $. Keep the $ {\bf{w}}^{(t)}_{\cdot j} $ for $ j \in \hat{S}^{(t)} $ and set $ {\bf{w}}^{(t)}_{\cdot j} = \bf{0} $ for all others $ j \notin \hat{S}^{(t)} $. Set $ {\bf{W}}^{(t+1, 1)}_1 = {\bf{W}}^{(t)}_1 $, $ {\bf{b}}^{(t+1, 1)}_1 = {\bf{b}}^{(t,n+1)}_1 $, $ {{\boldsymbol{\omega}}}^{(t+1,1)}_2 = {{\boldsymbol{\omega}}}^{(t,n+1)}_2 $, and $ b^{(t+1, 1)}_2 = b^{(t,n+1)}_2 $. end for Multistage FSA
-
In this section, we present the proposed multistage FSA method. As the true variables may not reveal their significance early in an iterative algorithm, the
$ \ell_2 $ $ \| {\bf{w}}_{\cdot j}\|_2 $ To address the abovementioned challenge and enhance the selection accuracy, we propose a variable selection method that incorporates an annealing strategy. After all iterations in a given stage are completed, we retain only those variables whose
$ \ell_2 $ $ \|{\bf{w}}^{(t)}_{\cdot j}\|_2 $ $ M_t $ $ \|{\bf{w}}^{(t)}_{\cdot j}\|_2 $ $ M_t $ $ M_t=k+(p_0-k)\max\left\{0,\dfrac{N_{iter}-t}{N_{iter}+t\mu}\right\},\quad\ \ \ \ t=1,\ 2,\ ...,\ N_{iter},\ $ where,
$ p_0 $ $ N_{iter} $ Figure 2 illustrates the annealing schedule for various annealing parameters
$\mu $ $\mu $ $ M_t $ $\mu $ 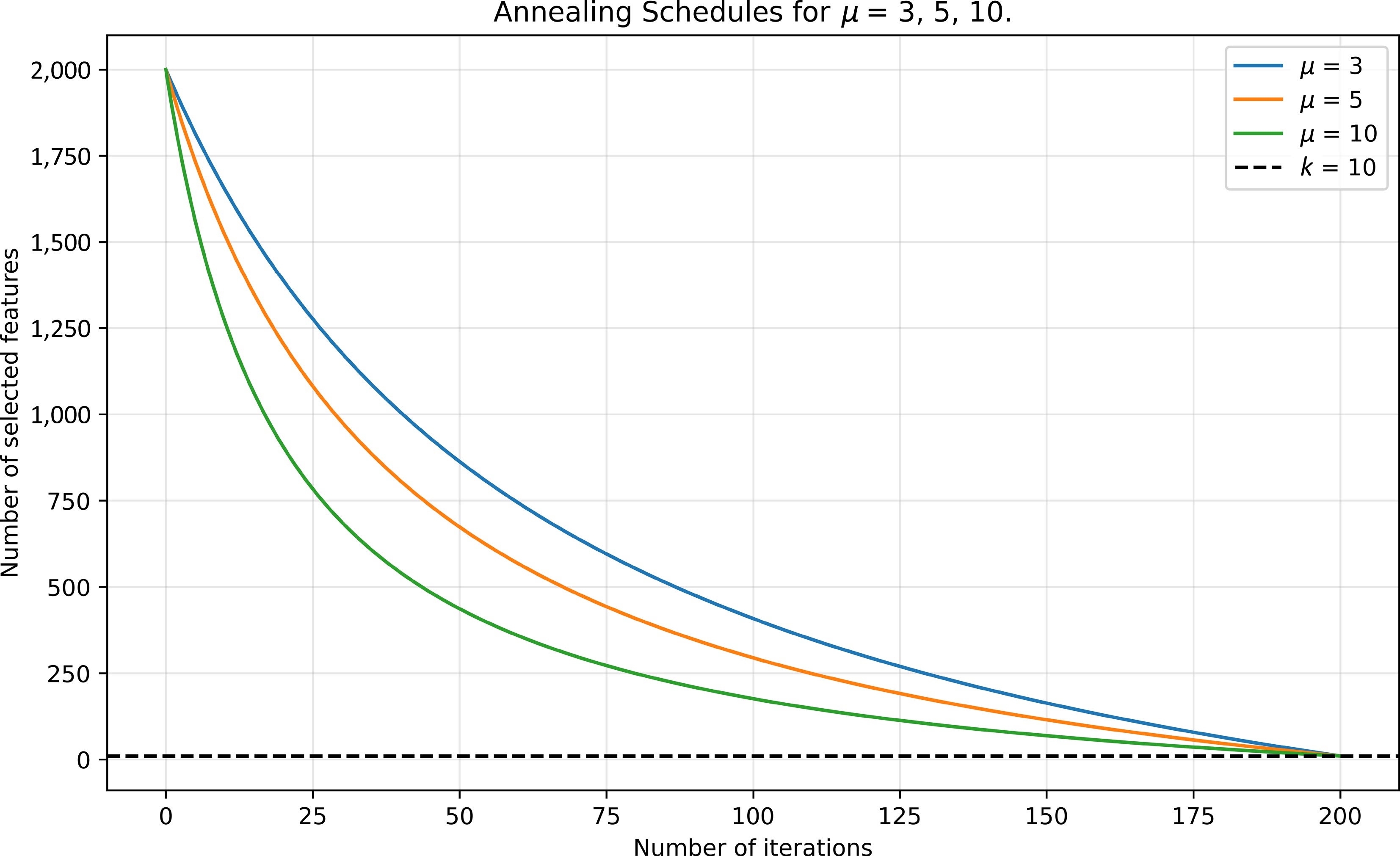
Figure 2.
Annealing schedule for p0 = 2,000, k = 10, Niter = 200, and multiple annealing parameters $ \mu $ = 3, 5, and 10.
Table 2. Multistage FSA algorithm.
Input: Standardized training data $ \{( {\bf{x}}_i,y_i)\}_{i=1}^n $, initial learning rate $ \eta_0 $, sparse level k, annealing parameter μ, and total iteration times $ N_{iter} $. Output: Trained weights $ {\bf{W}}_1 $, $ {\bf{b}}_1 $, $ {{\boldsymbol{\omega}}}_2 $ and $ b_2 $. Initialize $ {\bf{W}}_1^{(1, 1)} $, $ {\bf{b}}^{(1, 1)}_1 $, $ {{\boldsymbol{\omega}}}^{(1, 1)}_2 $, $ b^{(1, 1)}_2 $. for $ t = 1 $ to $ N_{iter} $ do Shuffle the training data $ \{( {\bf{x}}_i,y_i)\}_{i=1}^n $, and relabel $ i = 1, 2, \cdots, n $. for $ i = 1 $ to n do $ {{\boldsymbol{\omega}}}^{(t,i+1)}_2 \leftarrow {{\boldsymbol{\omega}}}^{(t,i)}_2 - \eta_t\dfrac{\partial \ell(y_i, f( {\bf{x}}_i;\cdots))}{\partial {{\boldsymbol{\omega}}}_2} $, $ b^{(t,i+1)}_2 \leftarrow b^{(t,i)}_2 - \eta_t\dfrac{\partial \ell(y_i, f( {\bf{x}}_i;\cdots))}{\partial b_2} $, $ {\bf{W}}^{(t,i+1)}_1 \leftarrow {\bf{W}}^{(t,i)}_1 - \eta_t\dfrac{\partial \ell(y_i, f( {\bf{x}}_i;\cdots))}{\partial {\bf{W}}_1} $, $ {\bf{b}}^{(t,i+1)}_1 \leftarrow {\bf{b}}^{(t,i)}_1 - \eta_t\dfrac{\partial \ell(y_i, f( {\bf{x}}_i;\cdots))}{\partial {\bf{b}}_1} $, end for Let $ {\bf{W}}^{(t)}_1 = {\bf{W}}^{(t,n+1)}_1 $. Denote $ {\bf{w}}^{(t)}_{\cdot j} $ as the j-th column for $ {\bf{W}}^{(t)}_1 $. Ranking $ \left\{\| {\bf{w}}^{(t)}_{\cdot j}\|_2\right\} $ in descending order, and retaining the index set $ \hat{S}^{(t)} $ corresponding to top-$ M_t $ largest values of $ \left\{\| {\bf{w}}^{(t)}_{\cdot j}\|_2\right\} $. Keep the $ {\bf{W}}^{(t)}_1 = [ {\bf{w}}^{(t)}_{\cdot j}] $ for $ j \in \hat{S}^{(t)} $ and remove $ {\bf{w}}^{(t)}_{\cdot j} $ for all others $ j \notin \hat{S}^{(t)} $. Set $ {\bf{W}}^{(t+1, 1)}_1 = {\bf{W}}^{(t)}_1 $, $ {\bf{b}}^{(t+1, 1)}_1 = {\bf{b}}^{(t,n+1)}_1 $, $ {{\boldsymbol{\omega}}}^{(t+1,1)}_2 = {{\boldsymbol{\omega}}}^{(t,n+1)}_2 $, and $ b^{(t+1, 1)}_2 = b^{(t,n+1)}_2 $. end for Given that the neural network models are trained with SGD per epoch, backpropagation is performed accordingly. As a result,
$ {{\boldsymbol{\omega}}}_2 $ $ b_2 $ $ {\bf{W}}_1 $ $ {\bf{b}}_1 $ $ M_{t} $ $ M_t $ The BIC for neural network models
-
Since the true number of features
$ k^* $ $ \text{BIC} = -2\log(\text{likelihood})/n + k \cdot p_1 \cdot \log(n)/n, $ (4) where, p1 denotes the width of the hidden layer, k is the selected number of variables, and n is the sample size. Eq. (4) is based on the fact that the number of free parameters in a one-hidden-layer neural network satisfying the sparsity constraint in Eq. (3) is of order
$ O(k \cdot p_1) $ However, in the high-dimensional scenario with sample size n < p0, an increase in the number of parameters k causes the penalty term
$ k \cdot p_1 \cdot \log(n)/n $ $ \text{HD-BIC}=-2\log(\text{likelihood})/n+k\cdot\log(p_1)\cdot\log(n)/n\ . $ (5) Here, we modify the penalty term in Eq. (4) to
$ k \cdot \log(p_1) \cdot \log(n)/n $ A comparison of existing feature selection methods in neural networks
-
The methods introduced in this paper, regardless of the specific algorithmic details, can be broadly classified as nonparametric feature selection techniques. In these approaches, surrogate models are employed to approximate the underlying model. The index set
$ S^{*} $ In the literature of the latest method[41], the authors estimate the index set of the nonzero columns of
$ {\bf{W}}_1 $ In works featuring Deep Feature Selection[29] and LassoNet[30], the sparsity constraint is imposed on
$ {\bf{W}}_1 $ -
In this section, we describe the evaluation of the proposed variable selection methods using a one-hidden-layer neural network. First, we present the simulation results for a high-dimensional linear regression model as an initial example. Next, we evaluate the performance of the proposed variable selection methods on the nonlinear regression model using large-scale data sets. We then extend the nonlinear regression model to the nonlinear logistic regression model. In addition, we tackle a particularly challenging Exclusive OR (XOR) problem[42]. Finally, we present the results of the real-data analysis. Each simulation setting is repeated 100 times using independently generated data sets, and the cosine-annealing method is used to schedule the learning-rate decay. Since initializing neural network parameters to zero leads to symmetry issues during training, we adopt randomized initialization schemes proposed in the literature[43]. The number of hidden-layer nodes is set to 128 for all experiments, except for the XOR problem, where it is increased to 256. All simulations are performed on a desktop equipped with an AMD Ryzen 9 9950X3D CPU running at 4.30 GHz and 64 GB of memory.
High-dimensional linear regression case
-
Here, we present the results of a numerical experiment for a high-dimensional linear regression model. The samples
$ {\bf{x}}_i \in \mathbb{R}^{p_0} $ $ i = 1, 2, \cdots, n $ $ {{\boldsymbol{\Sigma}}} $ $ \boldsymbol{\Sigma}_{i,j}=\left\{\begin{array}{*{20}{l}}\rho^{|i-j|}, & \text{ if }|i-j|\le2,\ \ \ \ i,\ j=1,\ 2,\ ...,\ p_0\ \ \\ 0, & \text{others}\end{array}\right. $ The response
$ y_i $ $ y_i = {\bf{x}}^{\top}_i {{\boldsymbol{\beta}}}^* + \epsilon_i, \ \epsilon_i \sim {\cal{N}}(0, 1), $ where, the parameter vector β* = (2, −2, 2, 3, 3, −2, 3, 3, −3, 2, 0, 0, ..., 0)T
$ \in \mathbb{R}^{p_0} $ $ \epsilon_i $ In this simulation, we compare the performance of the proposed multistage StoIHT method with the multistage FSA method. We also include the IHT method as a baseline[31]. First, we consider the case in which the number of variables
$ k^* $ $ k^* $ $ \mathrm{FSR}=\dfrac{|\hat{S}\backslash S^*|}{|\hat{S}|}\ \text{ and }\ \mathrm{NSR}=\dfrac{|S^*\backslash\hat{S}|}{|S^*|}, $ where,
$ S^* $ $ \hat{S} $ Table 1. Comparison of the proposed multistage FSA, multistage StoIHT, and IHT methods for the high-dimensional linear regression model with the sample size n = 1,000, 1,500, and 3,000 and p0 = 2,000.
Sample
sizeParameter Multistage FSA Multistage StoIHT IHT − HD-BIC BIC − HD-BIC BIC − HD-BIC BIC n = 1,000 Model size† 10 (0) 11.67 (1.556) 6 (0) 10 (0) 11.99 (1.972) 6 (0) 10 (0) 10.91 (1.167) 6 (0) FSR† 0.091 (0.071) 0.207 (0.113) 0 (0) 0.185 (0.074) 0.284 (0.135) 0 (0) 0.075 (0.099) 0.141 (0.120) 0 (0) NSR† 0.091 (0.071) 0.089 (0.073) 0.4 (0) 0.185 (0.074) 0.165 (0.077) 0.4 (0) 0.075 (0.099) 0.072 (0.094) 0.4 (0) RMSE† 1.745 (0.510) 1.743 (0.533) 3.333 (0.142) 2.353 (0.461) 2.234 (0.499) 3.222 (0.101) 1.520 (0.617) 1.492 (0.593) 3.197 (0.095) Time‡ 2.972 34.27 32.63 11.58 128.1 130.0 2.017 22.01 23.17 n = 1,500 Model size† 10 (0) 10.43 (0.711) 7.160 (1.815) 10 (0) 10.41 (0.861) 6.040 (0.398) 10 (0) 10.43 (0.778) 6 (0) FSR† 0.022 (0.044) 0.061 (0.075) 0.006 (0.024) 0.013 (0.034) 0.041 (0.068) 0 (0) 0.073 (0.094) 0.090 (0.106) 0 (0) NSR† 0.022 (0.044) 0.025 (0.048) 0.290 (0.173) 0.013 (0.034) 0.007 (0.026) 0.396 (0.040) 0.073 (0.094) 0.056 (0.089) 0.4 (0) RMSE† 1.192 (0.343) 1.228 (0.400) 2.802 (1.054) 1.119 (0.270) 1.075 (0.205) 3.206 (0.236) 1.467 (0.563) 1.368 (0.538) 3.179 (0.097) Time‡ 4.551 51.80 52.55 17.22 192.0 192.8 3.183 34.48 36.30 n = 3,000 Model size† 10 (0) 10.02 (0.140) 10 (0) 10 (0) 10.35 (0.921) 10 (0) 10 (0) 10.51 (0.877) 10.34 (0.681) FSR† 0 (0) 0.002 (0.013) 0 (0) 0 (0) 0.028 (0.067) 0 (0) 0.070 (0.094) 0.089 (0.100) 0.081 (0.098) NSR† 0 (0) 0 (0) 0 (0) 0 (0) 0 (0) 0 (0) 0.070 (0.094) 0.048 (0.083) 0.053 (0.085) RMSE† 1.192 (0.343) 1.228 (0.400) 2.802 (1.054) 1.119 (0.270) 1.075 (0.205) 3.206 (0.236) 1.467 (0.563) 1.313 (0.506) 1.347 (0.525) Time‡ 4.551 51.80 52.55 17.22 192.0 192.8 3.183 56.24 59.04 All experiments are conducted on 100 independent data sets. † Average FSR, NSR, and RMSE of test data are presented; ‡ average computational time (s). From Table 1, we observe that the performances of the multistage StoIHT and multistage FSA methods are similar in this high-dimensional linear regression setting. Specifically, in the high-dimensional scenario with n = 1,000 and p0 = 2,000, the multistage FSA outperforms the multistage StoIHT and the IHT when using the proposed HD-BIC. As the sample size n increases, the multistage StoIHT performs slightly better than the multistage FSA. When the sample size n is sufficiently large, for example, n = 3,000, the results obtained with the conventional BIC are better than those obtained with the HD-BIC. We also conclude that multistage FSA and multistage StoIHT outperform the IHT method in the large-n case.
Nonlinear regression case
-
The numerical results for the nonlinear regression model are presented in this section. The predictors
$ {\bf{x}}_i \in \mathbb{R}^{p_0} $ $ i = 1, 2, \cdots, n $ $ {{\boldsymbol{\Sigma}}} $ $ y_i $ $ y_i = \dfrac{6x_{i2}}{1 + x^2_{i1}} + 5\sin(x_{i3}x_{i4}) + 4x_{i5} - 5x_{i6} + 0 \cdot x_{i7} + \cdots + 0\cdot x_{ip_0} + \epsilon_i, \ \epsilon_i \sim {\cal{N}}(0, 1). $ In this case, we set p0 = 1,000 and n = 104, 2 × 104, 3 × 104 as a large-scale data set, and compare the multistage FSA, multistage StoIHT, and IHT under the conditions of known and unknown
$ k^* $ Table 2. Comparison of the multistage FSA, multistage StoIHT, and IHT methods for the nonlinear regression model with the sample size n = 104, 2 × 104, 3 × 104 , and p0 = 1,000.
Sample
sizeParameter Multistage FSA Multistage StoIHT IHT − HD-BIC BIC − HD-BIC BIC − HD-BIC BIC n = 104 Model size† 6 (0) 8.270 (1.399) 5.850 (0.766) 6 (0) 7.810 (1.270) 6.120 (0.325) 6 (0) 7.640 (1.797) 5.120 (1.283) FSR† 0.100 (0.082) 0.309 (0.142) 0.070 (0.090) 0 (0) 0.212 (0.126) 0.017 (0.046) 0.275 (0,128) 0.401 (0.164) 0.172 (0.175) NSR† 0.100 (0.082) 0.077 (0.083) 0.102 (0.081) 0 (0) 0 (0) 0 (0) 0.275 (0,128) 0.278 (0.106) 0.323 (0.099) RMSE† 2.518 (0.176) 2.453 (0.168) 2.543 (0.222) 1.506 (0.084) 1.531 (0.082) 1.519 (0.082) 2.888 (0.207) 2.943 (0.183) 3.020 (0.198) Time‡ 23.78 195.6 192.8 27.75 223.5 219.7 10.80 83.04 89.33 n = 2 × 104 Model size† 6 (0) 8.150 (1.352) 6.350 (0.684) 6 (0) 8.180 (1.403) 6.090 (0.286) 6 (0) 7.740 (1.659) 6.510 (1.895) FSR† 0.015 (0.048) 0.257 (0.125) 0.059 (0.094) 0 (0) 0.243 (0.139) 0.013 (0.041) 0.282 (0.122) 0.406 (0.164) 0.291 (0.205) NSR† 0.015 (0.048) 0.017 (0.050) 0.013 (0.045) 0 (0) 0 (0) 0 (0) 0.282 (0.122) 0.267 (0.139) 0.283 (0.130) RMSE† 2.110 (0.150) 2.087 (0.159) 2.076 (0.159) 1.408 (0.075) 1.393 (0.083) 1.390 (0.083) 2.906 (0.210) 2.885 (0.280) 2.943 (0.308) Time‡ 47.67 379.9 386.5 55.51 457.8 446.5 18.11 156.6 162.2 n = 3 × 104 Model size† 6 (0) 7.790 (1.409) 6.610 (0.937) 6 (0) 7.760 (1.556) 6.020 (0.140) 6 (0) 7.660 (1.589) 6.590 (1.650) FSR† 0.007 (0.033) 0.209 (0.148) 0.080 (0.113) 0 (0) 0.195 (0.159) 0.003 (0.020) 0.252 (0.124) 0.388 (0.159) 0.296 (0.180) NSR† 0.007 (0.033) 0.007 (0.033) 0.003 (0.023) 0 (0) 0 (0) 0 (0) 0.252 (0.124) 0.252 (0.119) 0.267 (0.120) RMSE† 1.823 (0.149) 1.816 (0.143) 1.800 (0.130) 1.357 (0.080) 1.358 (0.069) 1.354 (0.067) 2.859 (0.242) 2.852 (0.246) 2.876 (0.241) Time‡ 72.70 587.9 586.0 82.18 682.6 670.2 33.98 264.8 268.5 All experiments are conducted on 100 independent data sets. †Average FSR, NSR, and RMSE of the test data are presented; ‡average computational time (s). From Table 2, we can conclude that the performance of the multistage StoIHT slightly outperforms that of the multistage FSA when the sample size n is large, regardless of whether
$ k^* $ Nonlinear logistic regression case
-
We extend the nonlinear regression model to the nonlinear logistic regression model. The instances
$ {\bf{x}}_i \in \mathbb{R}^{p_{0}} $ $ i = 1, 2, \cdots, n $ $ y_i $ $ y_i = \mathbb{I}\left(2\exp(x_{i1}) + 3x^2_{i2} + 5\sin(x_{i3}x_{i4}) - 4x_{i5} - 3x_{i6} + 0 \cdot x_{i7} + \cdots + 0 \cdot x_{ip_0} \geq \epsilon_i\right), $ where
$ \mathbb{I}(\cdot) $ $ \epsilon_i $ $ k^* $ Table 3. Comparison of the multistage FSA, multistage StoIHT, and IHT methods for the nonlinear logistic regression model with the sample size n = 104, 2 × 104, 3 × 104, and p0 = 1,000.
Sample
sizeParameter Multistage FSA Multistage StoIHT IHT − HD-BIC BIC − HD-BIC BIC − HD-BIC BIC n = 104 Model size† 6 (0) 6.530 (0.830) 4.680 (0.760) 6 (0) 5.450 (1.982) 4.020 (0.140) 6 (0) 7.500 (1.825) 4.040 (0.196) FSR† 0.072 (0.118) 0.135 (0.161) 0.021 (0.069) 0.650 (0.065) 0.580 (0.131) 0.497 (0.088) 0.330 (0.023) 0.411 (0.146) 0.248 (0.010) NSR† 0.072 (0.118) 0.073 (0.134) 0.238 (0.125) 0.650 (0.065) 0.652 (0.075) 0.663 (0.058) 0.330 (0.023) 0.305 (0.071) 0.493 (0.033) AUC† 0.960 (0.008) 0.959 (0.011) 0.942 (0.021) 0.903 (0.015) 0.903 (0.016) 0.902 (0.015) 0.933 (0.009) 0.936 (0.013) 0.904 (0.013) Time‡ 24.22 201.6 196.3 44.29 365.7 375.2 12.23 105.1 101.6 n = 2 × 104 Model size† 6 (0) 7.460 (1.315) 5.890 (0.467) 6 (0) 6.880 (1.856) 4.310 (0.523) 6 (0) 7.670 (1.750) 5.190 (0.674) FSR† 0.013 (0.056) 0.175 (0.138) 0.005 (0.027) 0.512 (0.114) 0.505 (0.159) 0.317 (0.157) 0.330 (0.023) 0.426 (0.133) 0.219 (0.065) NSR† 0.013 (0.056) 0.003 (0.023) 0.023 (0.078) 0.512 (0.114) 0.468 (0.112) 0.515 (0.100) 0.330 (0.023) 0.302 (0.073) 0.332 (0.029) AUC† 0.967 (0.007) 0.967 (0.006) 0.956 (0.049) 0.915 (0.016) 0.918 (0.018) 0.915 (0.017) 0.934 (0.009) 0.938 (0.013) 0.934 (0.009) Time‡ 50.43 398.4 397.6 88.29 711.3 750.4 22.64 198.6 189.5 n = 3 × 104 Model size† 6 (0) 8.810 (1.102) 5.970 (0.386) 6 (0) 4.710 (1.458) 4.050 (0.218) 6 (0) 7.640 (1.616) 5.450 (1.117) FSR† 0.008 (0.036) 0.309 (0.100) 0.008 (0.033) 0.350 (0.055) 0.150 (0.173) 0.075 (0.112) 0.332 (0.017) 0.431 (0.119) 0.244 (0.097) NSR† 0.008 (0.036) 0.003 (0.023) 0.013 (0.061) 0.350 (0.055) 0.367 (0.067) 0.377 (0.073) 0.332 (0.017) 0.303 (0.080) 0.330 (0.053) AUC† 0.967 (0.007) 0.968 (0.006) 0.962 (0.034) 0.936 (0.008) 0.935 (0.008) 0.934 (0.009) 0.933 (0.008) 0.938 (0.014) 0.935 (0.012) Time‡ 73.86 592.2 592.6 124.3 1069 1138 33.84 256.8 250.2 All experiments are conducted on 100 independent data sets. † Average FSR, NSR, and AUC for test data are presented; ‡ average computational time (s). From Table 3, we observe that the multistage FSA significantly outperforms the multistage StoIHT and IHT methods in both variable selection and prediction, regardless of whether
$ k^* $ XOR problem
-
In this section, we present numerical results on the challenging XOR problem for the proposed multistage FSA and multistage StoIHT methods. The IHT method is also included as a baseline for comparison. The XOR problem is a binary classification task. The
$ p_0 $ $ {\bf{x}}_i \in \mathbb{R}^{p_0} $ $ {\cal{U}}(-1,1) $ $ y_i $ $ y_i = \mathbb{I}\left( \prod\limits_{j=1}^{k^*} x_{ij} \gt 0 \right), $ where,
$ \mathbb{I}(\cdot) $ $ k^* $ Table 4 shows that the performance of all methods is relatively poor, attributed to the XOR problem being particularly challenging. Nevertheless, compared with the multistage StoIHT and IHT methods, the multistage FSA achieves better variable selection and prediction performance when using the HD-BIC.
Table 4. Comparison of the multistage FSA, multistage StoIHT, and IHT methods for the XOR model with sample size n = 3,000 and p0 = 20.
Parameter Multistage FSA Multistage StoIHT IHT − HD-BIC BIC − HD-BIC BIC − HD-BIC BIC k* = 3 Model size† 3 (0) 3.580 (0.982) 1 (0) 3 (0) 6.940 (0.276) 1 (0) 3 (0) 1.160 (0.913) 1 (0) FSR† 0.277 (0.430) 0.333 (0.405) 0.250 (0.433) 0.870 (0.199) 0.834 (0.117) 0.880 (0.325) 0.997 (0.033) 0.887 (0.313) 0.890 (0.313) NSR† 0.277 (0.430) 0.253 (0.419) 0.750 (0.144) 0.870 (0.199) 0.613 (0.274) 0.960 (0.108) 0.997 (0.033) 0.957 (0.112) 0.963 (0.104) AUC† 0.848 (0.227) 0.856 (0.225) 0.501 (0.020) 0.505 (0.053) 0.522 (0.110) 0.500 (0.019) 0.500 (0.009) 0.500 (0.000) 0.500 (0.000) Time‡ 2.378 18.58 19.81 2.833 22.64 23.22 4.458 17.71 17.59 k* = 4 Model size† 4 (0) 6.130 (1.101) 1 (0) 4 (0) 7 (0) 1 (0) 4 (0) 1 (0) 1 (0) FSR† 0.290 (0.396) 0.473 (0.260) 0.320 (0.466) 0.840 (0.175) 0.786 (0.132) 0.880 (0.325) 1 (0) 0.850 (0.357) 0.850 (0.357) NSR† 0.290 (0.396) 0.223 (0.337) 0.830 (0.117) 0.840 (0.175) 0.625 (0.230) 0.970 (0.081) 1 (0) 0.963 (0.089) 0.963 (0.089) AUC† 0.812 (0.231) 0.823 (0.221) 0.497 (0.018) 0.498 (0.019) 0.506 (0.050) 0.497 (0.020) 0.498 (0.010) 0.500 (0.001) 0.500 (0.001) Time‡ 2.615 20.51 20.47 2.788 24.52 24.50 4.611 17.46 17.43 k* = 5 Model size† 5 (0) 6.590 (0.750) 1 (0) 5 (0) 7 (0) 1 (0) 5 (0) 1 (0) 1 (0) FSR† 0.636 (0.313) 0.624 (0.264) 0.610 (0.488) 0.792 (0.160) 0.734 (0.146) 0.830 (0.376) 0.998 (0.020) 0.820 (0.384) 0.820 (0.384) NSR† 0.636 (0.313) 0.512 (0.325) 0.922 (0.098) 0.792 (0.160) 0.628 (0.204) 0.966 (0.075) 0.998 (0.020) 0.964 (0.077) 0.964 (0.077) AUC† 0.573 (0.166) 0.598 (0.185) 0.500 (0.019) 0.503 (0.020) 0.508 (0.048) 0.500 (0.017) 0.498 (0.011) 0.500 (0.000) 0.500 (0.000) Time‡ 2.616 20.88 20.97 2.828 25.30 23.83 4.618 17.37 17.57 All experiments are conducted on 100 independent data sets. † Average FSR, NSR, and AUC for test data are presented; ‡ average computational time (s). Real-data analysis
17-AAG data set
-
We apply the proposed multistage FSA, multistage StoIHT, and IHT methods to the 17-AAG data set from the Cancer Cell Line Encyclopedia (CCLE) to identify genes associated with sensitivity to 17-AAG. The CCLE data set comprises 8-point dose–response curves for 24 chemical compounds, measured across more than 400 cancer cell lines, and is publicly available at
www.broadinstitute.org/ccle . For each cell line, gene expression levels of 18,926 genes are recorded. We use the area under the dose–response curve as the response variable to quantify drug sensitivity[47]. Specifically, for the 17-AAG data set, our objective is to apply the proposed variable selection methods to identify genes associated with sensitivity to 17-AAG.First, we apply the proposed HD-BIC to the entire data set to select important variables. Figure 3 presents the BIC values for different numbers of selected variables k. We observe that when k = 2, the BIC value is minimal. The essential variable, NQO1, is selected using the multistage FSA method when k = 3 and k = 4.
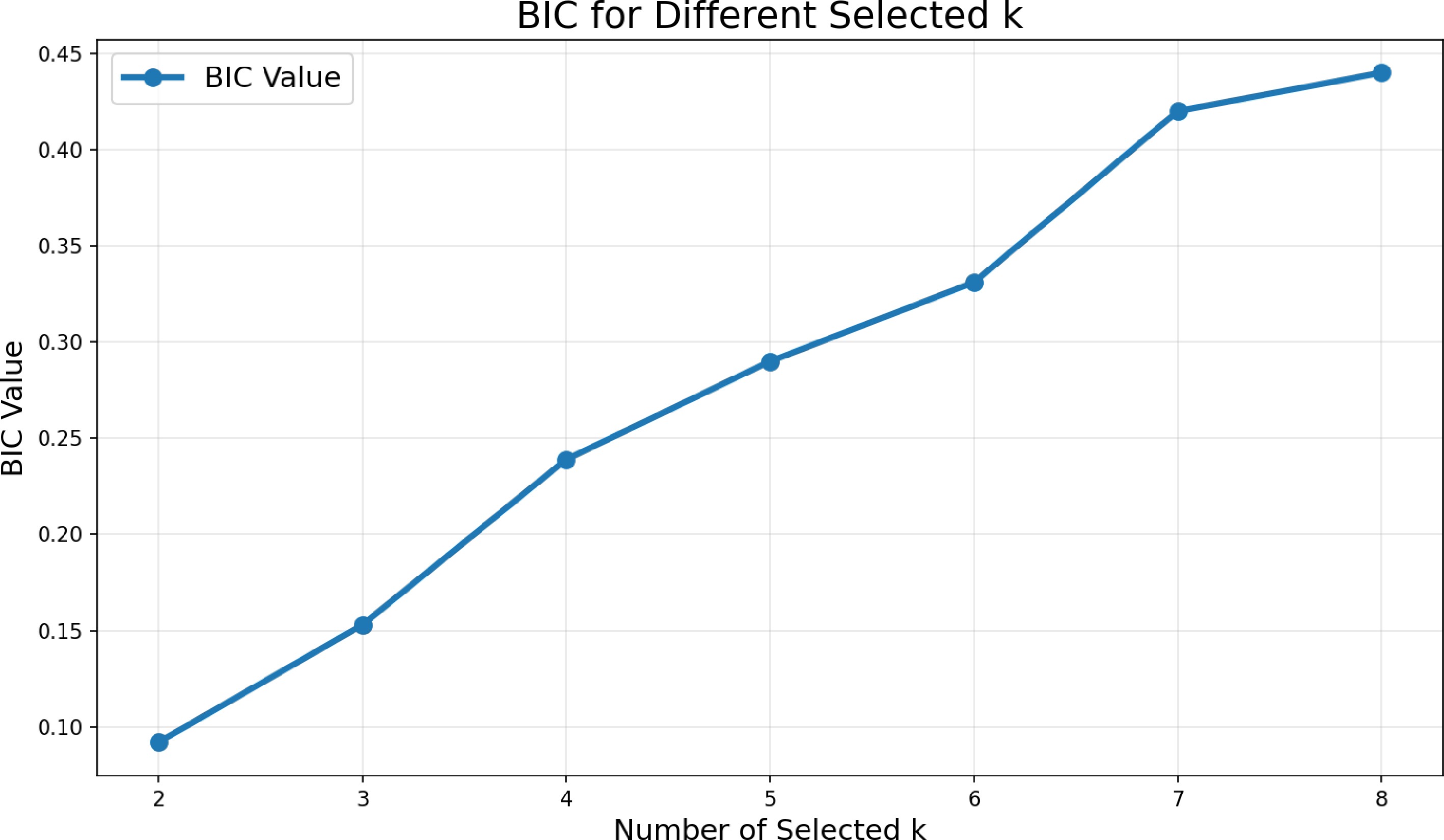
Figure 3.
BIC values for multiple selected k.
We then randomly split the data set into training and validation sets, with 400 samples in the training set and 76 samples in the validation set. This procedure is repeated 20 times. The training data are used to fit the model, and the performance is evaluated on the validation data. We select k = 2, 3, 4 variables and compare the multistage FSA with the multistage StoIHT and IHT methods. The results are presented in Table 5.
The variable NQO1 selected by the multistage FSA method has been identified in the existing literature as the most important biomarker associated with sensitivity to 17-AAG[47,48]. From Table 5, we observe that, across multiple choices of the selected number k, the multistage FSA achieves a smaller predicted RMSE on the validation data compared with the multistage StoIHT and IHT methods.
Table 5. Comparison of the multistage FSA, multistage StoIHT, and IHT methods for 17-AAG data set.
Number of selected variables Multistage FSA Multistage StoIHT IHT k = 2 0.991 (0.064) 0.991 (0.064) 0.991 (0.065) k = 3 0.988 (0.065) 0.992 (0.062) 0.993 (0.056) k = 4 0.987 (0.065) 0.994 (0.062) 0.989 (0.059) The RMSE values for validation data are presented. Madelon data set
-
The Madelon data set is an artificial data set designed for variable selection and classification[49]. This data set consists of data points grouped into 32 clusters at the vertices of a five-dimensional hypercube, with labels assigned at random to +1 or −1 (relabeled as +1 or 0 in this paper). This data set contains k* = 20 informative features, including 5 original features and their 15 linear combinations. In addition, this data set includes 480 irrelevant features with no predictive power, bringing the total to 500. The data set has a sample size of 2,600. The Madelon data set is publicly available at
https://archive.ics.uci.edu/dataset/171/madelon . We train shallow neural networks on the training data and report the performance on the validation data in Table 6.Table 6. Comparison of the multistage FSA, multistage StoIHT, and IHT methods for the Madelon data set.
Multistage FSA Multistage StoIHT IHT Lasso k* Known 0.642 (0.021) 0.535 (0.029) 0.534 (0.040) 0.608 (0.013) BIC 0.656 (0.022) 0.533 (0.062) 0.522 (0.040) 0.610 (0.011) HD-BIC 0.651 (0.029) 0.532 (0.049) 0.519 (0.039) − The average AUC values for validation data are presented. We randomly split the data set into training and validation sets 20 times, with 2,000 samples in the training set and 600 samples in the validation set each time. The training data are used to fit the model, while the performance is evaluated on the validation set. We compare the performance of the proposed multistage FSA, multistage stochastic IHT, and IHT methods. In addition, the classical
$ \ell_1 $ $ \ell_1 $ -
This article proposes two novel stochastic algorithms for nonlinear variable selection via shallow neural networks. The first proposed algorithm is the multistage StoIHT algorithm, a stochastic version of the IHT algorithm[31,32]. The second proposed algorithm is the multistage FSA algorithm, a variable selection method that employs an annealing strategy with the multistage StoIHT. After a comprehensive evaluation in both regression and classification settings, we conclude that the proposed multistage FSA and multistage StoIHT methods slightly outperform the IHT method in the numerical experiments presented in this paper. Furthermore, in the high-dimensional setting (large-p–small-n setting), the proposed HD-BIC outperforms the conventional BIC for variable selection. In contrast, in the low-dimensional setting (large-n–small-p setting), the conventional BIC performs better for variable selection.
Although the proposed methods exhibit strong empirical performance, they have several limitations. First, this study focuses primarily on numerical investigations, with rigorous theoretical analysis left for future research. Unlike parameter learning in linear regression, which involves only the estimation error, training a neural network model requires accounting for both estimation and approximation errors[14]. As a result, the theoretical analysis of variable selection consistency for neural network models is substantially more complicated than that for linear regression models. Second, the present study is limited to nonlinear variable selection using shallow neural networks, and the performance of the proposed methods in the deep neural network setting remains unexplored. We will focus on these issues in our future research.
-
This work was collaboratively conducted by Li X, Zhang C, Sun L, Meng Z, and Zhang H. Li X and Zhang C contributed equally to this paper. The contributions of each author are as follows: Li X, Zhang C, and Sun L contributed to the study's conception and design. Li X and Zhang C conducted coding preparation, data collection, and analysis. Sun L wrote the first draft of the manuscript and revised it. Meng Z and Zhang C contributed to the final version of the manuscript through critical revisions. All authors reviewed the manuscript and approved the final version for submission.
-
The real data sets used in this paper are publicly available as specified in the section "Simulation". The code will be made publicly available on https://github.com/lizhesun0507 upon acceptance of the paper.
-
Lizhe Sun's research was partially supported by the National Social Science Fund of China grant 24&ZD183.
-
The authors declare that they have no conflict of interest.
-
# Authors contributed equally: Xinglei Li, Chenlu Zhang
- Copyright: © 2026 by the author(s). Published by Maximum Academic Press, Fayetteville, GA. This article is an open access article distributed under Creative Commons Attribution License (CC BY 4.0), visit https://creativecommons.org/licenses/by/4.0/.
-
About this article
Cite this article
Li X, Zhang C, Sun L, Meng Z, Zhang H. 2026. Feature selection with annealing for shallow neural networks using the multistage stochastic algorithm. Statistics Innovation 3: e008 doi: 10.48130/stati-0026-0008 

Feature selection with annealing for shallow neural networks using the multistage stochastic algorithm
- Received: 30 December 2025
- Revised: 20 March 2026
- Accepted: 08 April 2026
- Published online: 31 May 2026
Abstract: Feature selection is a fundamental challenge in statistics and machine learning, playing a critical role in improving prediction accuracy and enhancing model interpretability. It is widely applied across various scientific and practical domains. However, most existing variable selection methods are developed within the framework of linear and generalized linear models, which limit their applicability to more complex data structures. In this article, we introduce two novel nonlinear variable selection approaches that integrate an iterative hard-thresholding operator into stochastic training of shallow neural networks. The proposed methods help to simultaneously identify important features and build a predictive model based on the selected subset using shallow neural networks. Furthermore, we propose a new Bayesian information criterion that can facilitate effective model selection in the high-dimensional setting. Extensive numerical experiments on both simulated and real-world data sets demonstrated that the proposed methods show remarkable performance compared with the classical approaches in the literature.