








-
With rapid urbanization and increasing traffic density, road infrastructure faces unprecedented challenges. Asphalt pavements, as an essential component of the transportation system, directly affect driving safety and the service life of roads. Cracks, as one of the common ailments of asphalt pavements, not only affect the appearance of the roads but also accelerate the destruction of the roadbed through rainwater infiltration, thereby affecting the integrity and safety of the road structure. Therefore, timely and accurate detection of pavement cracks has become an important task in road maintenance management[1].
Traditional crack detection methods primarily rely on manual visual inspection, which is not only time-consuming but also significantly influenced by the inspectors' experience and subjective judgment, making it difficult to meet the demands of rapid and large-scale road detection. With the advancement of computer vision technology, machine vision-based crack detection technology for asphalt pavements has rapidly developed[2]. These technologies utilize digital image processing and pattern recognition techniques to automate crack detection, significantly enhancing the speed and accuracy of the detection process[3]. The introduction of deep learning technology has further enhanced the ability to process complex image data, making crack detection under various lighting conditions and complex backgrounds possible[4].
The core purpose of this review article is to comprehensively examine the recent methods for asphalt pavement crack detection using machine vision technology, and delve into the latest advancements, technical advantages, and challenges faced by these technologies. The article first categorizes asphalt pavement crack detection technologies (as shown in Fig. 1), primarily into two main categories: one based on digital image processing and the other based on machine learning for asphalt pavement crack detection. In conducting a detailed comparison and analysis of these technologies, the article aims to evaluate their application advantages, limitations, and suitability under different detection environments and requirements. By exploring the practical application effects of various technologies, the article will assess their suitability in engineering practice and attempt to predict future development trends. Additionally, the article is dedicated to exploring how technology integration and innovation can overcome the limitations of existing methods, aiming to provide more efficient and reliable solutions for road crack detection. This not only contributes to the optimization of road maintenance strategies but also drives the development and application of related technologies, with significant theoretical and practical significance. Through these studies, it is expected to provide stronger safeguards for road safety, ensuring the efficiency and foresight of road maintenance work.
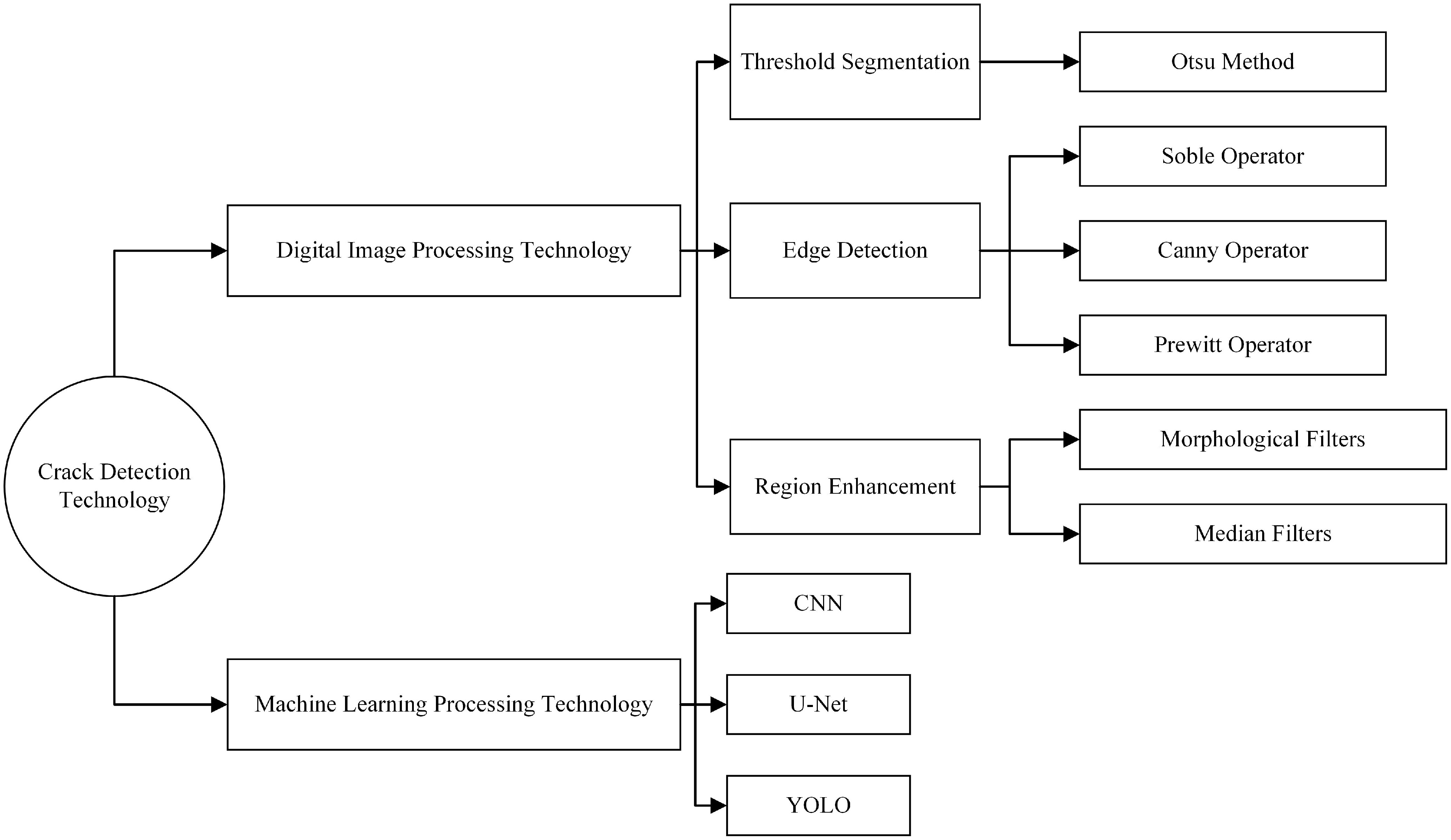
Figure 1.
Classification of asphalt pavement crack detection techniques.
-
Firstly, the article will introduce the asphalt pavement crack detection technology based on digital image processing. This section will elaborate on the key technologies and commonly used algorithms from the steps of image acquisition, preprocessing, feature extraction to crack identification. Additionally, it will discuss the effectiveness and challenges encountered in practical applications of these technologies, such as environmental interference, processing speed, and accuracy issues. Subsequently, the article will explore machine learning-based asphalt pavement crack detection technology, particularly the extensive application of deep learning in recent years. This part will cover the core aspects of data collection, model training, feature learning, and crack classification. It will also assess the advantages of deep learning technology in handling complex images and big data environments and discuss the main challenges it faces, such as high resource consumption and reliance on a large amount of annotated data. Finally, the article will compare the applicability and performance of these two technologies, analyzing their potential points of integration and complementarity in actual road maintenance work. Through comparative analysis, the aim is to provide road maintenance departments and researchers with strategic choices and technical improvement suggestions for practical applications. Furthermore, it will discuss potential future research directions and technological development trends to promote further optimization and innovation in asphalt pavement crack detection technology.
Based on digital image processing technology
-
Crack detection based on image processing technology relies on image or visual data to detect and locate cracks or fractures in various materials or structures. This method uses computer algorithms and methods to analyze visual information captured through images, and then determine the existence, size, shape, and location of cracks within materials or objects. Image processing methods mainly include three major categories: threshold segmentation[5], edge detection[6], and region enhancement[7]. Threshold segmentation methods separate image pixels into several categories by setting appropriate pixel intensity thresholds, thereby separating the target cracks from the background, such as the Otsu method[8]. Edge detection typically uses edge detection operators such as the Sobel operator[9], Prewitt operator[10], and Canny operator[11] to detect the edges of road cracks. Region-growing methods describe specific information within the cracks by assembling pixels with similar features into a region[12]. Model-based on local information uses various filters, such as morphological filters[13], median filters, multi-scale line filters with Hessian matrix[14], and so on (as shown in Fig. 2).
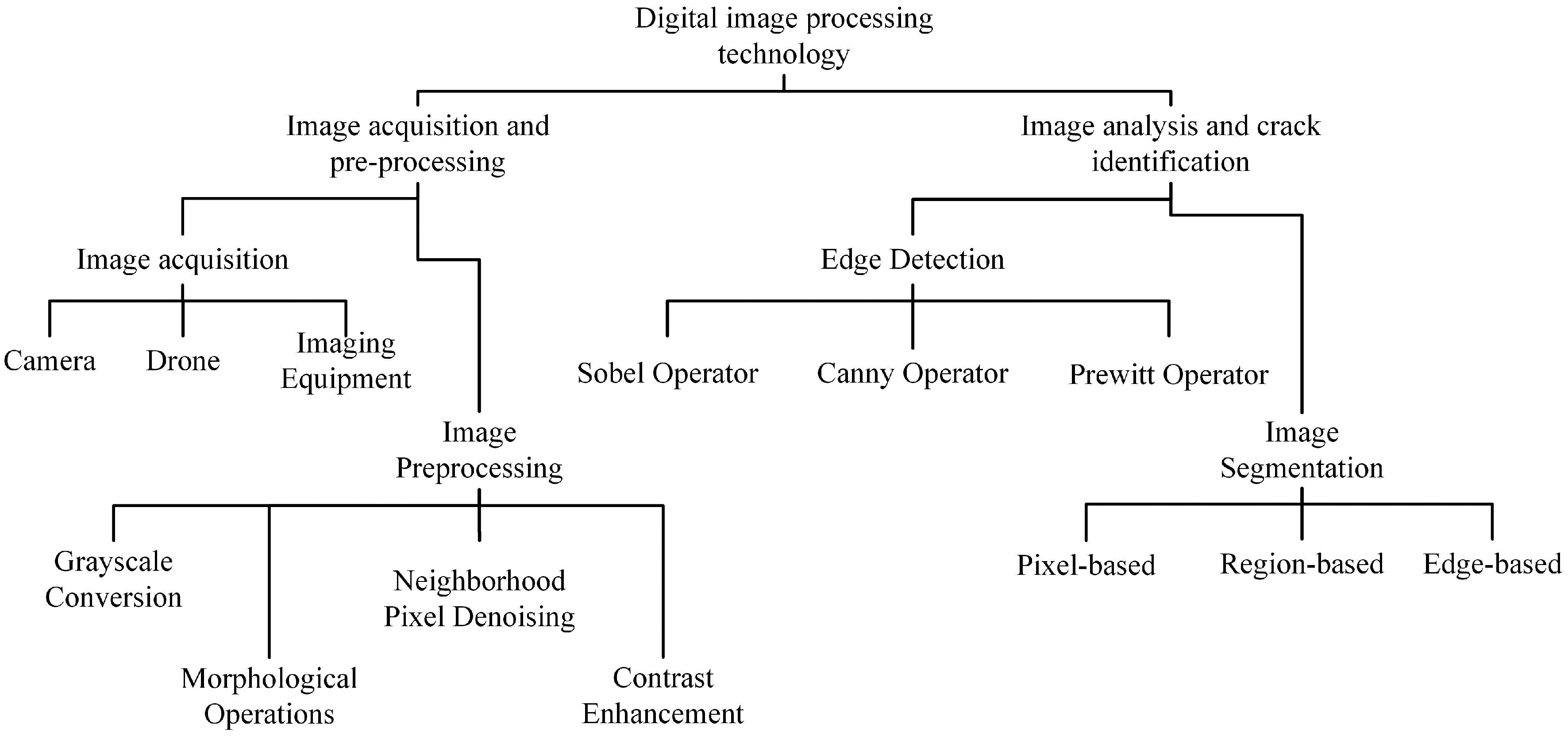
Figure 2.
Overview of digital image processing techniques.
Image acquisition and preprocessing
Image acquisition
-
The process of collecting or obtaining digital images from various sources, such as cameras, drones, or other imaging devices, is called image acquisition. This process aims to transform visual information from the real world into a digital format that computers can process[15]. Depending on the equipment used, various factors can be adjusted during the image capture process, such as exposure time, focus, resolution, and color settings. After the images are captured, they can be stored, analyzed, and optimized using a series of image-processing techniques. For urban streets with low traffic volume, drones equipped with high-definition cameras are often used to capture road surface images[16,17],By limiting the flight height and speed, clear road surface images can be obtained. For highways or smaller areas, cameras or smartphones can be used to manually capture and collect crack images (as shown in Fig. 3).
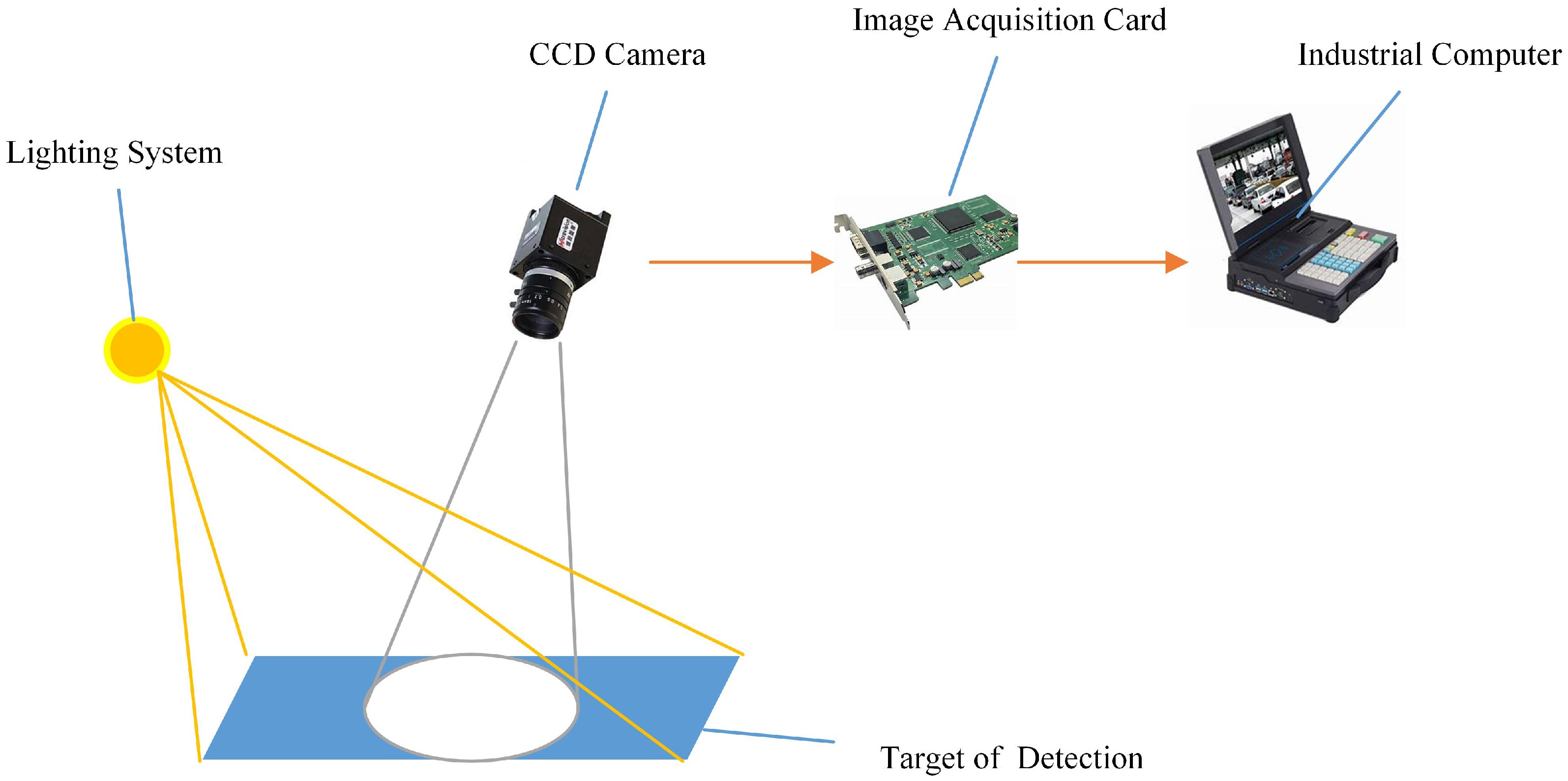
Figure 3.
Image acquisition using a CCD camera.
They can also be installed on mobile platforms such as vehicles and drones or on vehicle dashboards to capture road surface images[3,18,19]. Thermal imaging sensors[20], and ground-penetrating radar[21] have also been used to detect cracks, leveraging the differences in signals returned from normal and damaged road surfaces. Embedded fiber optic sensors[22] are also an emerging technology for detecting road fatigue. Each method has its advantages and limitations, and the choice of method depends on specific application scenarios, the required image accuracy, cost, and ease of operation. For example, drones and vehicle-mounted measuring vehicles are suitable for large-scale road surface detection, while digital cameras and smartphones are more suitable for small-scale or specific area detection. As shown in Fig. 4, there are different devices for image acquisition.
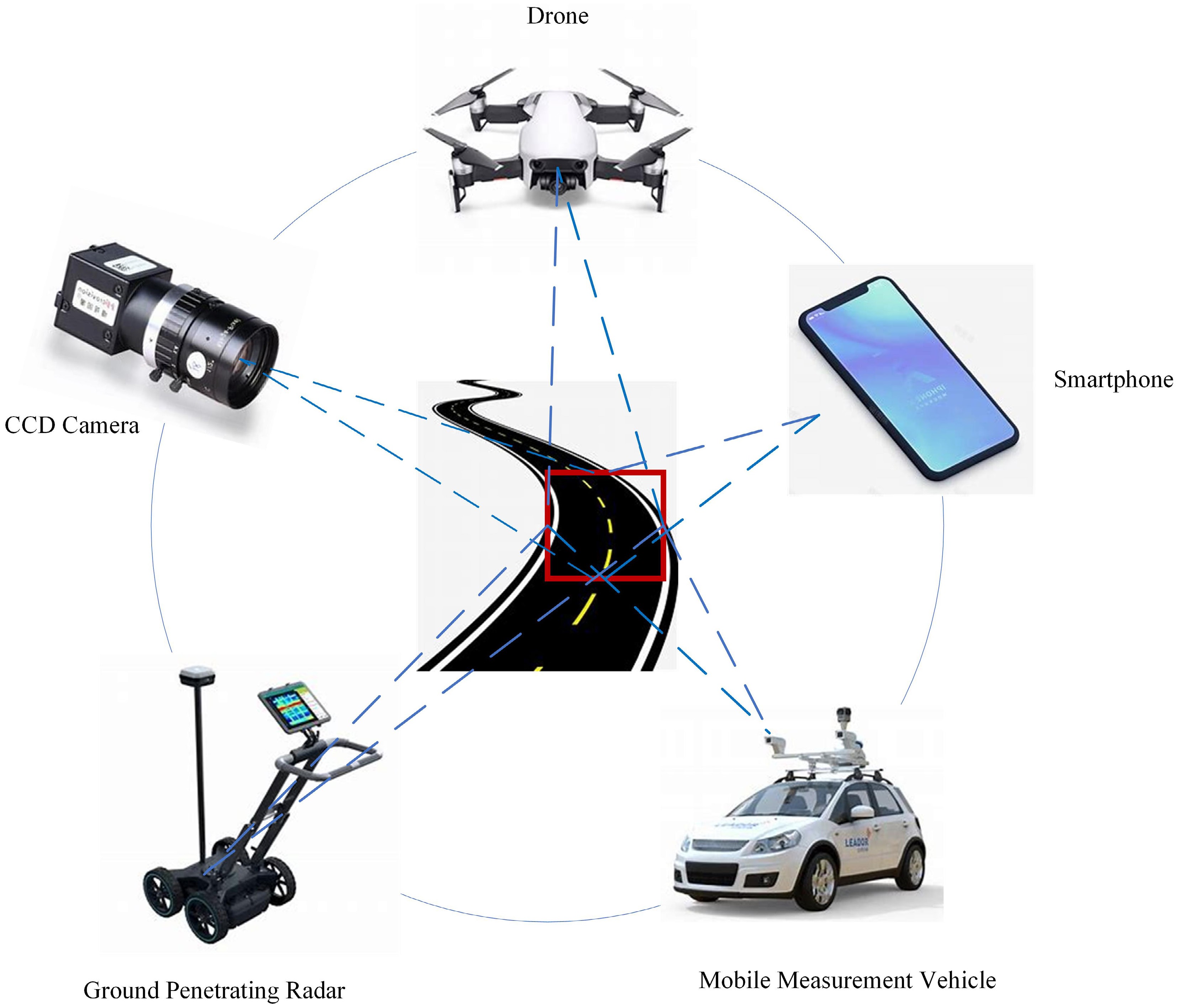
Figure 4.
Different devices for image acquisition.
Image preprocessing
-
Image preprocessing is a crucial step in enhancing the accuracy of crack identification, to eliminate or mitigate various interfering factors present in the images. Asphalt pavement images are not captured under the same conditions, and some images contain unwanted objects, such as random particle textures, unevenness[23], uneven illumination and road surface irregularities[24], shadows[25], water, tire marks, oil leaks[26], etc. Image denoising is an important step in image preprocessing, which improves image quality by removing noise and artifacts that may obscure or distort the appearance of cracks, making them more clearly visible. Commonly used methods for image denoising include Gaussian filters, median filters, Wiener filters[18,27−29], etc. (as shown in Fig. 5), in addition to which, Hu et al.[30] used grayscale correction and morphology for image denoising. Li & Yang[19] used the Neigh Shrink algorithm for denoising the acquired images. Another important step in image preprocessing is image enhancement, which includes brightness and contrast adjustment, color correction, filtering, frequency domain techniques, etc.[31−33] Li et al.[34] use gray entropy for road image enhancement, and simulation results show that the proposed method is more effective than traditional algorithms. Yao et al.[35] developed a new imaging system (APDS) that can scan the road surface without the use of any artificial illumination. The system consists of a dual-line scanning camera, and the cameras are set with different exposure devices that can eliminate the interference of shadows. Cropping is also a common process in image preprocessing, which involves removing unnecessary outer areas from the image[36−38]. This can be used to reduce accidental waste, improve image composition, change perspective, focus on specific features, or isolate the subject from its surrounding environment.
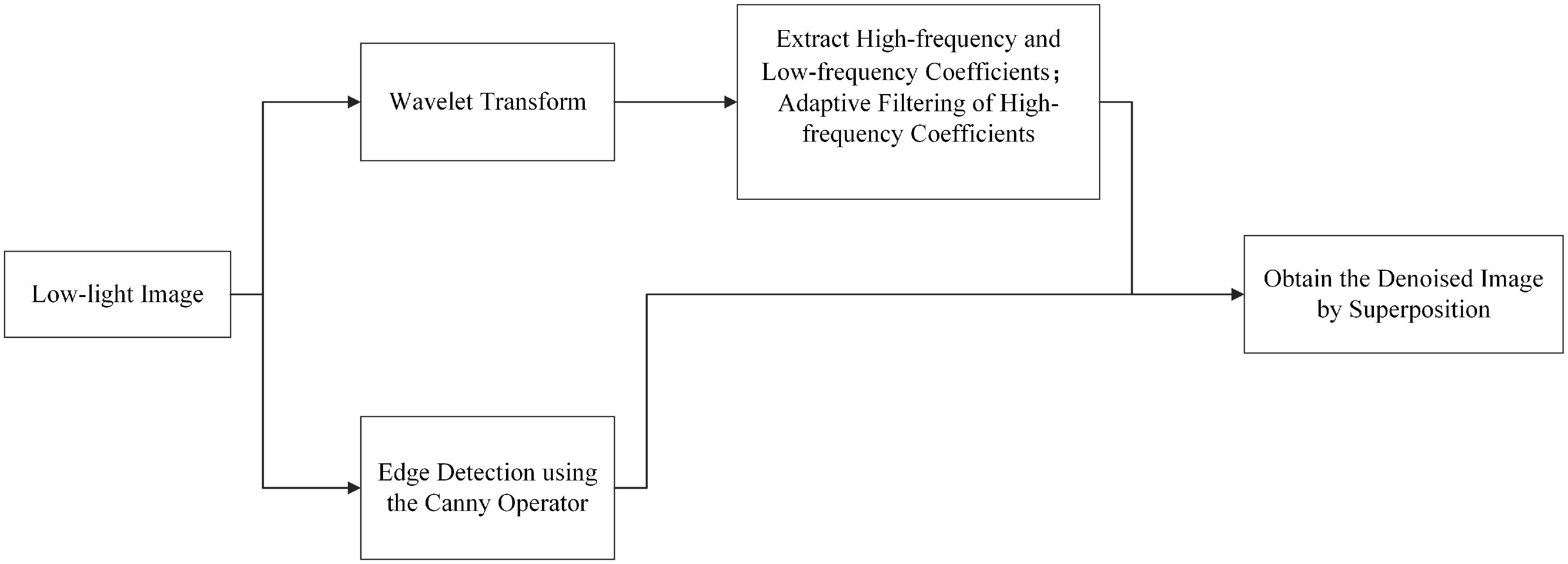
Figure 5.
Flowchart of image denoising using filtering.
The common goal of preprocessing steps is to enhance the recognizability of crack images, thereby providing clearer and more accurate image data for subsequent crack detection algorithms. However, each preprocessing method has its specific parameter settings, which have a decisive impact on the quality of the final image. For instance, the selection of segmentation points in grayscale stretching, the threshold setting in wavelet denoising, and the degree of sharpening in the Laplacian operator all require careful adjustment based on the specific image characteristics and crack features. If the parameters are set improperly, it may lead to loss of image details, enhancement of noise, or deformation of crack features, thereby affecting the accuracy of crack detection.
Image analysis and crack identification
Edge detection
-
Image analysis plays a crucial role in crack detection, which typically includes key steps such as feature extraction, image segmentation, and crack identification. Edge detection, as one of the techniques, is responsible for identifying the boundaries of cracks from preprocessed images and quantifying their characteristics. However, in practical applications, many road surface images may not contain damage. If crack detection is performed on these images, it will not only increase unnecessary workload but also reduce detection efficiency. Therefore, optimizing the image processing workflow and reducing the detection of undamaged images is crucial for improving the speed and accuracy of crack detection. There are many common edge detection operators, such as the Sobel operator, Canny operator, and Prewitt operator. These commonly used detection algorithms are based on the grayscale value of the original image, detecting edges based on the grayscale changes in a certain neighborhood of each pixel.
Starting with the Sobel algorithm[39], edge detection algorithms based on differentiation have become very popular. The Sobel operator is a discrete differential operator used for edge detection, which detects edges by calculating the approximate value of the first-order derivative of the image's grayscale function. The Sobel operator mainly consists of two 3 x 3 convolution kernels, one for the horizontal direction and one for the vertical direction, to calculate the spatial gradient of image brightness. The horizontal Sobel operator (Gx) and the vertical Sobel operator (Gy) are defined as follows:
$ {G}_{x}=\left(\begin{array}{ccc}-1& 0& 1\\ -2& 0& 2\\ -1& 0& 1\end{array}\right),\;\;{G}_{y}=\left(\begin{array}{ccc}-1& -2& -1\\ 0& 0& 0\\ 1& 2& 1\end{array}\right) $ After applying these two convolution kernels to the image, the gradient values in the horizontal and vertical directions of the image can be obtained. Then, the gradient magnitude and direction for each pixel in the image can be calculated using the following formulas:
Gradient Magnitude: G =
$ \sqrt{{G}_{x}^{2}+{G}_{y}^{2}} $ $ {G}_{x}|+|{G}_{y}| $ Gradient Direction:
$ \theta =arctan\dfrac{{G}_{y}}{{G}_{x}} $ In 1980, Marr & Hildreth[40] proposed a Gaussian Laplacian method for detecting edge contours, which marked the beginning of edge detection algorithms based on second-order derivatives. The formula for the LoG operator combines a Gaussian function with the second-order derivative. For a two-dimensional LoG function centered at 0 with a Gaussian standard deviation of σ. In 1986, Canny[41] proposed an edge detection algorithm based on the first-order derivative, which calculates the gradient magnitude and direction of an image by applying the Sobel operator or other gradient operators.
Gradient Magnitude: M (x, y) =
$ \sqrt{{G}_{x}^{2}(x,\;y)+{G}_{y}^{2}(x,\;y)} $ Gradient Direction:
$ \theta =arctan\dfrac{{G}_{y}(x,\;y)}{{G}_{x}(x,\;y)} $ The Canny technique is an important method for detecting image edges, which involves isolating noise from the image before detecting edges. It allows for the application of trends to find the critical values of edges and thresholds without affecting the characteristics of the edges in the image[42]. Subsequently, many researchers have made improvements based on existing algorithms[43−46], Ma et al.[47] introduced a method based on FDWT (fractional differential and wavelet transform). This method effectively enhances high-frequency and mid-frequency signals, and nonlinearly retains low-frequency signals. The FDWT is compared with other operators such as Sobel, Prewitt, and LoG to prove its performance[48]. Even in noisy images, this procedure is effective for different road crack images. Min[49] used new templates in the direction of 67.5° and 112.5°, called the improved Sobel template, to obtain the image edge after image preprocessing. Wang et al.[50] designed a local adaptive algorithm for Otsu threshold segmentation, and combined it with the improved Sobel operator to remove isolated noise points, thereby extracting crack edge information and improving the positioning accuracy of the crack boundary. Zhao et al.[51] used the Mallat transform to enhance unclear edges, and used GA to obtain a better adaptive threshold Canny algorithm. Huang et al.[52] used statistical filtering to solve the problem of blurred image edges; then based on the operator's 3 × 3 gradient template, the gradient magnitude and direction of the pulse string image were calculated. The image threshold is obtained using a natural iterative method, and the discontinuous edges are repaired using morphological closing operations and thinning operators to obtain the final detected edges. In response to the phenomenon of false edges or missing edges in image edge detection operators, an improved Canny operator edge detection method is used. Figure 6 is a development chart of edge detection technology.
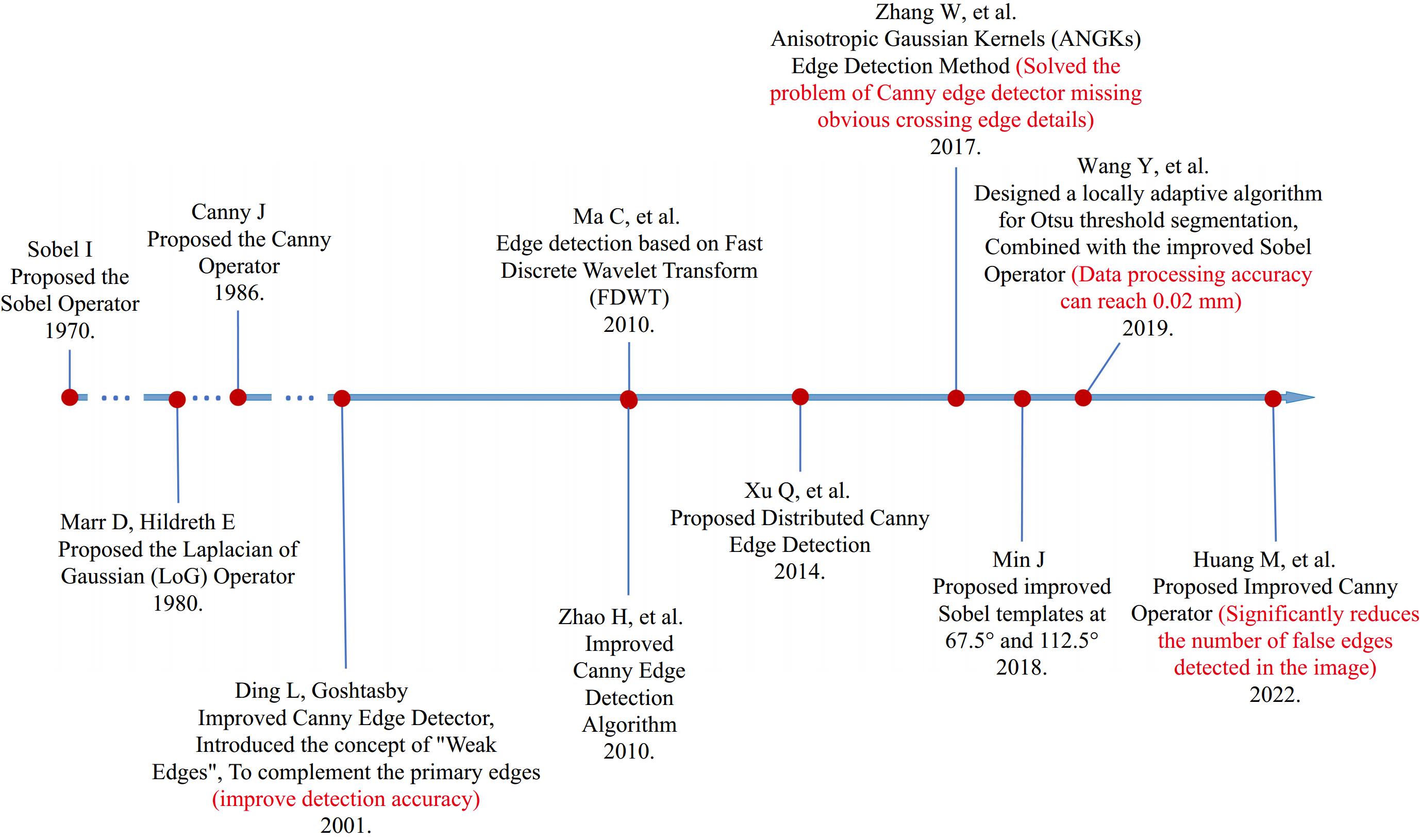
Figure 6.
Development of edge detection technology.
Image segmentation
-
Image segmentation is a key step in the fields of image processing and computer vision[17], to divide an image into multiple regions or objects for further analysis and processing[53]. The goal of image segmentation is to identify different objects and boundaries within an image, which serves as the foundation for applications such as image recognition, image understanding, and scene reconstruction. Salari & Bao[54] used a novel color segmentation method based on a feedforward neural network to separate the road surface from the background. They also used a probability relaxation-based threshold method to separate cracks from the road surface. Huang & Tsai[55] proposed a fast road crack segmentation algorithm based on dynamic programming (DP-based). The proposed method combines DP with grid cells. Based on this hybrid approach, the inhomogeneous background illumination based on regions is removed, and the preprocessed image is divided into grid cells. Experimental results show that the hybrid method is three times faster than the single DP-based method. Shao et al.[56] used a threshold segmentation method based on hybrid particle swarm optimization to segment crack images, calibrate the physical size of pixels, and extract crack feature parameters. Their experimental results indicate that this method can effectively and accurately extract cracks, with the detected linear crack width values having a relative error of less than 3% compared to actual measurements. This study demonstrates the potential of digital image processing technology in road crack detection, especially in terms of improving detection accuracy. Basavaprasad[57] studied image segmentation techniques and categorized segmentation into different groups: pixel-based, edge-based, and region-based, evaluating the complexity and effectiveness of segmentation. They concluded that there is no universal segmentation method suitable for all types of images, but some techniques perform better on specific types of images, and better performance can be achieved by selecting the appropriate algorithm or combining the right techniques. Zhao et al.[58] proposed a crack segmentation method based on a morphological processing network, which utilizes the U-Net network to enhance the recognition ability of cracks at different resolutions and solves the problem of inaccurate crack segmentation at a single scale through a multi-level loss function fusion mechanism. This method excels in processing complex cracks, especially showing its advantages in multi-scale analysis. Vivekananthan et al.[18] successfully detected objects in the image by combining the OTSU method and gray level discrimination method, achieving a maximum crack detection accuracy of up to 95%. Texture-based features have been used to identify cracks in asphalt pavements. They segmented the image[59], using a set of region pixels with coherent texture, and divided the obtained superpixels into cracked or uncracked using multi-instance learning.
Machine learning-based techniques
-
In recent years, machine learning-based asphalt pavement crack detection technology has been widely researched and applied in the field of road maintenance management. This technology assesses road conditions by automatically recognizing and quantifying road cracks, providing important support for timely and effective road maintenance. A successful crack detection system heavily relies on high-quality datasets for model training, and the quality of the data directly affects the performance and generalization ability of the model. Many researchers have explored pavement crack detection technology using Convolutional Neural Networks (CNN)[60−62] Convolutional Neural Networks are a DL-based architecture designed to process data that appears in the form of multiple arrays, used for detecting structural defects[63−65], and have been proven to be very effective.
Data collection and preprocessing
Data collection strategies
-
Datasets are an essential factor affecting the performance and accuracy of models when training and testing cracked images. Data collection is time-consuming and costly. Therefore, many researchers and institutions use devices such as GPR equipment, laser cameras, drones, digital cameras, and smartphones to capture road surface images, with the simplest road measurement device being the smartphone.
Maeda et al.[66] collected road images using a smartphone mounted on the dashboard of a regular car for application in crack detection. Yusof et al.[67] captured higher resolution 16-megapixel images with a Nikon digital camera for training a deep CNN to detect cracks in asphalt streets. The study by Satnami[68] is composed of images captured by drone devices for real-time road crack mapping. The disadvantage of these methods is that they cannot measure sidewalks at night. Additionally, there are some drawbacks to using regular cameras, such as noise, time surveys, and low resolution. Therefore, Yusof et al.[69] proposed a 2D laser camera for measuring road surfaces and obtained binary image results. Tsai et al.[70] used 3D laser road data from a 3D laser camera (laser crack measurement system) to determine road surface cracks.
In addition to relying on various devices to collect data directly, we can also obtain many important datasets through online channels. These datasets are crucial for the training and evaluation of deep learning models, as they can significantly enhance the accuracy and efficiency of road extraction tasks. By leveraging these ready-made data resources, researchers and developers can quickly train and optimize their models without the need to collect data themselves, thereby accelerating the development process and improving work efficiency. As shown in Table 1, common online public datasets.
Table 1. Common online public datasets.
Dataset name Description Application in literature Massachusetts dataset Contains 1,711 road images and 151 building images, used for road and building extraction Wei et al.[71] optimized CNN models to extract road categories from aerial images. Alshehhi et al.[72] implemented a patch-based CNN model to extract roads and building parts from remote sensing images. TerraSAR-X dataset Used for road extraction in SAR images, with 20% for testing and 80% for training Henry et al.[73] used DeepLabV3+ and Deep Residual U-Net to extract road parts from SAR images. DeepGlobe dataset Contains 622 test images, 622 validation images, and 4,971 training images Xie et al.[74] applied a new global perception framework based on higher-order spatial information (HsgNet) for road extraction. Google Earth dataset Contains 567 test images and 2,213 training images Cheng et al.[75] proposed the CasNet deep learning model to detect road categories and extract road centerlines. Shi et al.[76] implemented GAN models using data augmentation procedures to generate high-resolution segmentation maps. DigitalGlobe dataset Collected by DigitalGlobe satellite, contains 6,226 images Zhou et al.[77] introduced the D-LinkNet model for road semantic segmentation in remote sensing images. Doshi[78] used a ResNet-based ensemble model to extract roads from satellite images. Data augmentation and preprocessing
-
Data augmentation and preprocessing are necessary steps for formatting images before training and inference of object detection models. This step involves various operations such as scaling, orienting, cropping, histogram equalization, and color correction to improve the quality and consistency of input data[36]. One of the common techniques used in image preprocessing is histogram equalization, which is used to adjust the contrast of an image. This method achieves this by redistributing the intensity values in the image, thereby enhancing overall discrimination, especially in images with low-intensity illumination[79]. Pitas & Kiniklis[80] proposed a method for jointly equalizing the intensity and saturation components. Buzulois et al.[81] proposed an adaptive neighborhood histogram equalization algorithm. Trahanias & Venetsanopoulos[82] proposed a 3D histogram specification algorithm that outputs a uniformly distributed histogram in the RGB color cube. Yang & Rodríguez[83] proposed two hue-preserving techniques, namely scaling and shifting, for processing the brightness and saturation components. Later, the same authors developed a clipping technique[84] for enhancing values that exceed the RGB color space range. This is also one of the other commonly used techniques in image preprocessing in recent years, namely the clipping technique.
Model training and crack identification
-
Deep learning models excel in this task because they can learn complex features from a large amount of image data, thereby effectively identifying and classifying cracks. Commonly used models include Convolutional Neural Networks (CNN), U-Net, YOLO, etc.
Overview of deep learning models
-
Convolutional Neural Networks (CNN) are one of the most used models in deep learning, especially suitable for image processing tasks. The CNN architecture typically consists of multiple convolutional blocks and a fully connected layer. Each convolutional block is composed of a convolutional layer, activation units, and a pooling layer[85]. Cha et al.[65] designed a deep CNN architecture that can automatically extract local and global features in the image through a combination of convolutional layers, pooling layers, and fully connected layers. It utilizes multiple convolutional layers to automatically extract features, with each layer comprising a series of filters designed to capture local characteristics within images. The advantage of Convolutional Neural Networks (CNN) is their powerful feature extraction capability, which eliminates the need for manual feature engineering. They are capable of learning complex patterns from large datasets but are prone to overfitting with small datasets. Training times are long, requiring a significant amount of annotated data and substantial computational resources.
Recurrent Neural Networks (RNN) are neural networks designed for processing sequential data, and capturing dynamic features within time series. They pass information from previous time steps through recurrent connections, allowing the utilization of historical information in the computation of the current time step. RNN are capable of capturing long-term dependencies, making them suitable for time series data processing, such as the progression of cracks over time. However, they struggle with long sequences, are susceptible to vanishing gradient problems, and have low computational efficiency, making parallel processing difficult. For non-sequential image data, RNN are less effective than CNN.
U-Net[86] is a convolutional neural network architecture for image segmentation that has been widely used in crack identification. The characteristic of U-Net is its U-shaped network structure, which includes an encoder and decoder part. By using skip connections, it retains more spatial information and can generate precise segmentation maps. By detecting the crack areas in the image through the segmentation map and classifying the detected cracks (such as transverse cracks, longitudinal cracks, etc.). U-Net possesses formidable image segmentation capabilities, particularly suitable for medical imaging and crack detection. The skip connections aid in restoring precise positional information in the output. However, the model structure is complex, leading to high training costs and the requirement for a substantial amount of annotated data.
YOLO[61] is a real-time object detection algorithm that transforms the object detection task into a regression problem, achieving fast detection speed. YOLO can be used for real-time monitoring and detection of cracks in structures, issuing timely warnings. The detected cracks are classified by generating bounding boxes to accurately locate the position of the cracks. Its advantage lies in its real-time detection capability and speed. The entire network only requires a single forward propagation, which is computationally efficient. However, it has a weaker detection capability for small objects because it relies on grid cells to predict bounding boxes. Finetuning of the network structure is necessary to adapt to different detection tasks. Figure 7 shows the development history chart of deep learning models.
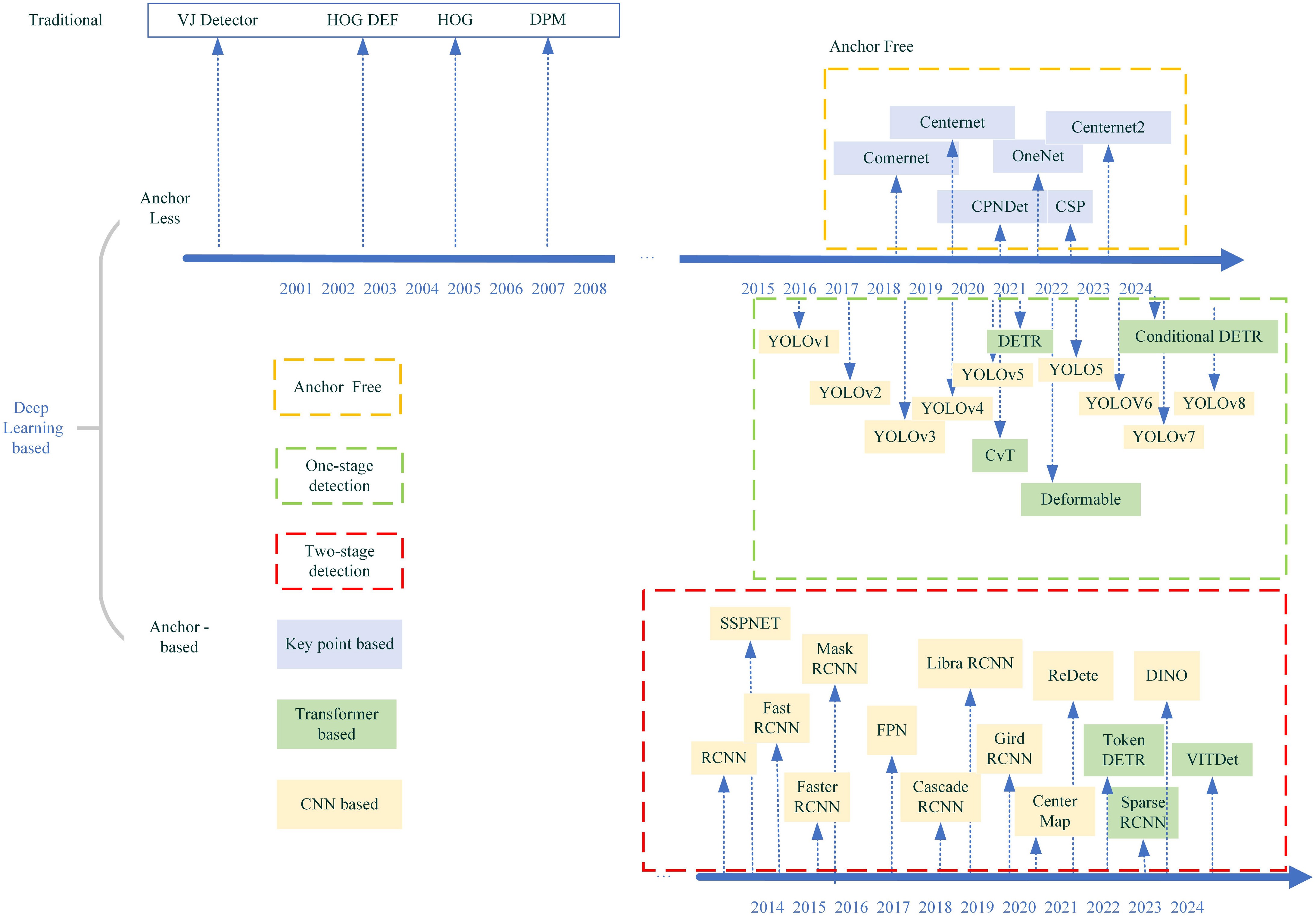
Figure 7.
Evolution history chart of deep learning models.
Crack classification and detection
-
Crack classification and detection are two key tasks in crack identification, aimed at automatically extracting crack features from images and classifying and locating them. Deep learning models such as Convolutional Neural Networks (CNN), U-Net, and YOLO have achieved automatic feature extraction, crack detection, classification, and generation of precise segmentation maps from images through different architectures and algorithms. Wang & Hu[87] trained images sized 32 × 32 and 64 × 64, whereas CNN only included two convolutional layers and two max-pooling layers for detecting cracks and non-cracks. Then, they classified three types of cracks (i.e., transverse cracks, longitudinal cracks, and fatigue cracks). Their model achieved high precision for transverse cracks, medium precision for longitudinal cracks at 0.97, and fatigue cracks at 0.90. Ahmed et al.[88] proposed a two-step process: the first step used CNN and VGG16 to determine crack or non-crack; in the second step, cracks were classified as minor or severe cracks using high-precision long short-term memory, with an accuracy of 0.9766. Xu et al.[89] proposed an end-to-end context-aware convolutional network architecture that utilizes large-area contextual information by expanding the receptive field, thereby helping to classify the central region and enhancing robustness to image noise. This method not only surpasses traditional methods in accuracy but also demonstrates the potential of deep learning in processing complex road images. Cha et al.[65] designed a deep CNN architecture trained with 40,000 cropped images of 256 × 256 pixel resolution, achieving an accuracy of about 98%, tested on 55 high-resolution images from different structures to verify the robustness and adaptability of the CNN method under different conditions (such as strong light, shadows, and very fine cracks). The performance was compared with traditional Canny and Sobel edge detection methods, and the results showed that CNN performed better in actual crack detection, effectively avoiding false contours caused by lighting factors, and more accurately and delicately detecting the edges of real agricultural products while improving resistance to noise interference.
Additionally, object detection algorithms, such as Faster R-CNN and YOLO, are used to identify the location and bounding boxes of cracks in images to locate the specific position of cracks in the image. Yang et al.[90] studied a deep data-driven model-based method for detecting asphalt pavement cracks and sealed cracks. The study created a dataset containing 10,400 images, using k-fold cross-validation (k = 3) to evaluate the model, we employed the Adam optimization algorithm and adjusted model parameters based on the changes in Precision, Recall, and F1 scores, and developed a dense and redundant crack annotation method, significantly improving the accuracy and efficiency of annotation. Experimental results showed that the YOLOv5 series model performed excellently in detection efficiency and accuracy, especially the YOLOv5s model, with an F1-score of 86.79% and an inference time of 14.8 ms. Although detection efficiency has been improved, further optimization is still needed to reduce the consumption of computing resources when processing large-scale datasets. Han et al.[91] proposed a visual crack detection method based on a deep convolutional neural network (CNN). The method trained the CNN model using the TensorFlow framework to directly learn crack features from images without preprocessing. The study uses Grid Search and Random Search to find the optimal combination of hyperparameters. The Adam optimization algorithm is used for optimization, and the best model is evaluated and selected by comparing the precision, recall, and F1 scores of different models. After training on a dataset of 240 images, the model was tested on 40 unseen images, achieving an accuracy rate of 96%. This method demonstrates the potential of deep learning in detecting cracks under complex road conditions. Jiang et al.[92] adopted a method combining infrared thermography technology with deep learning, proposing a model named GSkYOLOv5. This method effectively reduces the impact of environmental interference such as shadows and reflections by processing infrared images. A dataset containing 2,400 infrared images was constructed in the study, and samples were balanced through generative adversarial networks (GAN). Experimental results showed that GSkYOLOv5 improved detection accuracy and recall rate by 4.7% and 1.3% over YOLOv5s, respectively, demonstrating its superior performance in complex environments. Han and Jiang's[91,92] methods may be affected by lighting changes and shadows when dealing with crack detection under complex environmental conditions. Yang et al.[93] proposed a three-stage pavement crack localization and segmentation algorithm based on digital image processing and deep learning technology. In the crack disease localization stage, an improved YOLOv7 network structure was used, combined with the parameter-free attention module SimAM and Transformer encoder, as well as the SIoU loss function. The Adam algorithm was used for optimization, and parameters were fine-tuned by comparing the impact of different attention mechanisms and loss functions on the performance of the YOLOv7 network (precision, recall, etc.). The method enhances the ability to identify and locate cracks by improving the quality of pavement distress images, while reducing computational effort and improving the accuracy of crack contour extraction. This study provides a new solution for highway crack detection, demonstrating the broad application prospects of deep learning in road maintenance. Liu et al.[86] were the first to use U-Net to detect concrete cracks. The focal loss function was chosen as the evaluation function, and the Adam algorithm was applied for optimization. The trained U-Net was able to identify crack locations from the input raw images under various conditions (such as lighting, cluttered backgrounds, crack width, etc.), proving highly effective, and robust. As shown in Fig. 8 is the development process flowchart of object detection technology based on deep learning.
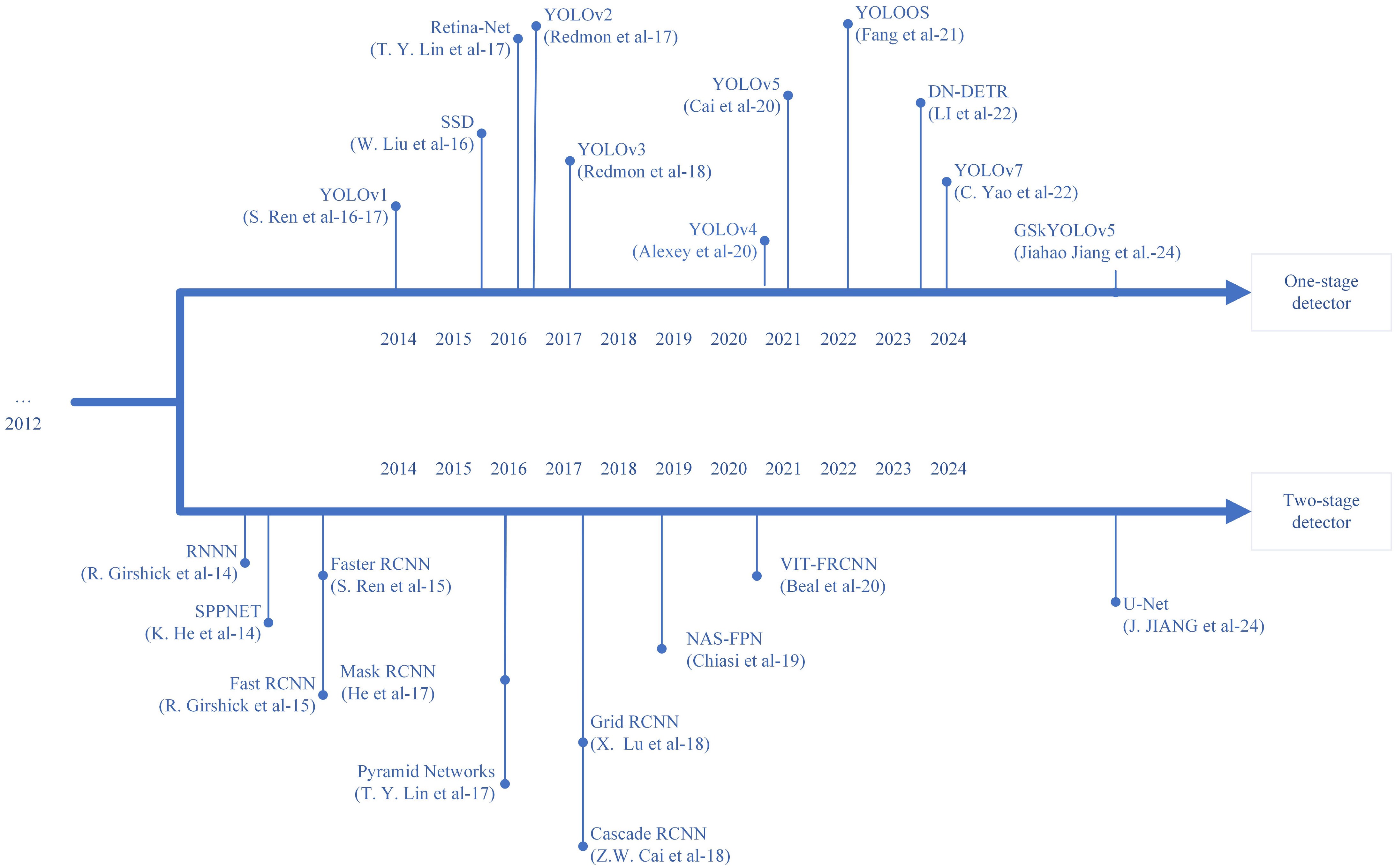
Figure 8.
Development process flowchart of object detection technology based on deep learning.
-
Asphalt pavement crack detection involves two technologies: digital image processing and machine learning. Digital image processing technology, which began in the 1960s, detects cracks through steps such as image acquisition, preprocessing, segmentation, feature extraction, and crack identification. Its preprocessing can eliminate interfering factors, segmentation methods are diverse, and feature extraction often uses edge detection operators, which can improve detection efficiency and accuracy but are affected by the complexity of road images. Machine learning technology collects data using a variety of devices, including smartphones, cameras, laser cameras, etc. It goes through data preprocessing, crack classification, object detection, segmentation, and model evaluation. Crack classification often uses CNN, object detection employs object detection algorithms, and evaluation has clear indicators. Both technologies have their characteristics; digital image processing technology has a longer history, while machine learning technology demonstrates the advantages of deep learning but face different challenges in practical applications.
Technologies based on digital image processing mainly rely on steps such as image preprocessing, feature extraction, and crack identification. The advantage of this method is its low computational cost, no need for a large number of sample training, and it can quickly classify cracks automatically. For example, morphological filters[13] and improved Canny algorithms[51,52] can effectively remove noise and preserve crack edges. In addition, constructing directional templates[49] and image smoothing preprocessing algorithms can better highlight the directionality of crack linear features. Machine learning-based technologies identify cracks by training models, can handle more complex road conditions, and their recognition accuracy will gradually improve with the increase of data volume[65]. However, the computational cost of crack recognition will also increase accordingly. For example, Convolutional Neural Networks (CNN) can automatically learn crack features from images, achieving high-precision crack identification[87]. Machine learning methods usually have an advantage in accuracy because they can improve recognition rates by learning from a large number of sample data.
In response to the high computational costs associated with machine learning-based crack detection, researchers have adopted various strategies to optimize and reduce these costs. By reducing the number of network layers or the number of neurons per layer[94], the number of model parameters can be significantly decreased, thereby reducing the computational load. For instance, networks such as MobileNets[95] or ShuffleNets[96] are specifically designed to minimize computational requirements while maintaining high accuracy. Pre-trained models on large datasets can also be fine-tuned for crack detection tasks, avoiding the need to train models from scratch and greatly reducing computational demands[97]. Additionally, data diversity can be increased through rotation, scaling, and cropping, reducing reliance on large amounts of real data[98]. Optimizers such as Adam and RMSprop[90] can accelerate model convergence and reduce the number of training iterations. Through these methods, it is possible to effectively reduce computational costs while maintaining the accuracy of crack detection, making machine learning-based crack detection methods more practical and efficient.
In summary, machine learning-based methods may be more effective in dealing with complex and variable road conditions but require sufficient training data and computational resources. Digital image processing methods have the advantage of computational efficiency and are suitable for rapid deployment and real-time detection. In practical applications, the appropriate technology can be selected according to specific needs and conditions. As shown in Table 2, the technical developments in crack detection are presented.
Table 2. The development of technology in crack detection.
Key technology Main contribution Performance index Ref. CNN model optimized based on road structure Combined fusion and deconvolution layers to obtain structured output, proposed a road structure-based
loss functionF1 Score: 66.2%; recall: 72.9%; precision: 60.6%; accuracy: 92.4% Wei et al.[71] A novel architecture based on FCN, called U-shaped FCN Proposed U-shaped FCN model, data augmentation
to improve training efficiencyF1 Score: 89.6%; recall: 86.8%; precision: 92.5%; accuracy: 95.2% Kestur et al.[99] U-Net fully convolutional network First use of U-Net for detecting concrete cracks,
U-Net is superior to DCNN in robustness,
effectiveness, and accuracyF1 Score: 90%; recall: 91%; precision 90% Zhenqing Liu[86] Technology based on improved deep encoder-decoder neural networks networks Enhanced model, using ELU function and
LM method to improve overall output accuracyF1 Score: 85.7%; recall: 86.1%; precision: 85.4% Panboonyuen et al.[100] CNN-based automatic bridge crack detection model Using an end-to-end model, parallel use of three Atrous convolutions to reduce computational complexity F1 Score: 87.7%; precision: 78.1%; accuracy: 98.4% Xu & Xu[101] To comprehensively evaluate and compare the performance of different models and training strategies, and to ensure the robustness and credibility of the research results, researchers typically employ a suite of assessment metrics that include standard deviation. This approach enhances the credibility of the research findings. In the study by Yu et al.[102], a deep learning model named Cracklab was proposed based on the Deeplabv3+ framework. During the training process, to enhance the model's recognition of complex background images, the authors conducted an in-depth experimental comparison of three loss functions—cross-entropy loss (CEL), focal loss (FL), and Dice loss (DL). By introducing standard deviation as a supplementary metric alongside multiple experiments of different training strategies, and in conjunction with the experimental outcomes, the authors ultimately selected focal loss (FL) as the loss function for the model, due to its superior performance in terms of stability and convergence. This choice helps to improve the model's performance in crack detection tasks, especially when dealing with complex backgrounds.
Application case analysis
Practical application
-
In the field of crack identification, technologies based on digital image processing and deep learning have achieved significant success in practical applications. Pauly et al.[103] designed a deeper neural network architecture specifically for road crack detection. The dataset used included 500 RGB road images[104] each with a resolution of 3264 x 2448 pixels. Each image was divided into 99 x 99 pixel image patches, which were labeled as cracked or non-cracked by multiple annotators. Subset 1 contained 20,000 cracked and non-cracked image patches as the training set and 200,000 image patches as the test set. Subset 2's training set included 40,000 image patches, and the test set included 60,000 image patches, with the test set images coming from a different location than the training set to introduce environmental variations. Deep Convolutional Neural Networks (CNNs) were used, employing categorical cross-entropy loss function and Stochastic Gradient Descent (SGD) algorithm, with 80 and 40 epochs of training for experiments 1 and 2, respectively. The experimental results indicated that increasing the network depth could improve the accuracy and recall rate of crack detection. However, when the training and testing datasets were from different locations, the network's performance declined, indicating that location variance is a significant hurdle for implementing a universal automatic crack detection system.
Liu et al.[86] were the first to adopt U-Net for detecting concrete cracks. The study utilized 84 images with a resolution of 512 × 512, 57 of which were used for model training and 27 for testing. These images encompassed various conditions, such as illumination, background interference, and crack width, with manual labeling of crack locations. The study compared the performance of U-Net and Cha's CNN under different conditions, including images under ideal conditions, images with significant background interference, images with thin cracks, and images under low-light conditions. The Focal loss function was used to address class imbalance issues. The Adam algorithm was employed with an initial learning rate of η = 0.0001, an exponential decay rate for the first moment estimate of β1 = 0.9, and for the second moment estimate of β2 = 0.999. Each training randomly selected two images as a mini-batch. A 3-fold cross-validation was used, with each fold utilizing 38 images for training and 19 for validation. After 80 epochs of training, the precision, recall, and F1 scores on the validation set stabilized at approximately 0.90, 0.91, and 0.90, respectively. U-Net outperformed Cha's CNN on the test set, especially under conditions of background interference, thin cracks, and low light, demonstrating better robustness and accuracy. Despite this, there is still much room for improvement in engineering applications, including algorithm improvements to accommodate more input sizes, hyperparameter tuning, and maintaining a larger dataset to train more robust models.
Li et al.[105] focused on the water leakage detection technology for tunnel asphalt pavements, proposing a computation method for water leakage area images based on deep learning and digital image processing. Their research results showed that the Efficient Net model achieved recognition accuracies of 99.85% and 97.53% on the training and validation sets, respectively, which is a 2.76% improvement over traditional methods. This finding not only validates the effectiveness of deep learning in water leakage detection but also provides new technical support for road maintenance. Overall, these studies demonstrate the significant advantages of deep learning in pavement crack detection, especially in enhancing detection accuracy and handling complex images. However, despite their excellent performance in laboratory environments, these methods still face some challenges in practical applications.
Limitations and challenges
-
Crack detection is quite challenging due to its irregular shapes and lack of fixed sizes, making it difficult to effectively identify through preset methods. This article reviews two major areas of crack detection and identification: technology based on digital image processing and technology based on machine learning. Although both types of methods perform well in specific contexts, they still face significant challenges in accurately detecting cracks. Crack classification is mentioned less in the text, yet it is crucial for revealing the nature, cause, and severity of cracks. More research is urgently needed to develop crack classification methods so that systems can recognize crack types and optimize maintenance strategies.
Digital image processing technology has given satisfactory performance on custom datasets constructed by researchers. However, these methods depend on lighting conditions, image resolution, and the level of noise present in the images[35,106]. Moreover, asphalt pavements have different textures when subjected to external disturbances, and even if they are made of the same material, they may not have the same texture. Therefore, when new images with different textures, brightness, resolution, or noise levels are inputted, they may not yield such good results. Additionally, the accuracy of transverse crack detection is not enough compared to longitudinal measurements. This difference in directional measurement could be an issue when establishing a relationship between the width and longitude of cracks. Thus, the practical applicability of using image processing-based methods remains unclear[107,108].
On the other hand, machine learning methods also present some limitations to researchers. An increase in processing time has been observed in many methods. Many methods require manual setting of model parameters, which limits the full automation of crack detection methods. To avoid model overfitting, it is necessary to train models with large datasets. These methods require extensive labeling of data images. In practical scenarios, the selection of labels is also limited, so obtaining labels can be a daunting task[90]. Different algorithms may be needed to accurately detect cracks due to varying surface conditions. Moreover, crack detection is performed offline, hence the real-time detection performance is poor. Therefore, there is a need to improve the performance of algorithms and detection accuracy. In addition, deep learning methods can be applied to unsupervised tasks, using small datasets that do not require extensive data labeling, thereby reducing time and costs[59].
The presence of noise, shadows, blemishes, and other disturbances in images is a common problem that researchers face when using image processing and machine learning methods[23,47,86]. Therefore, more research is needed to develop methods that can remove noise and other irregularities in images[109].
Scope of technical application
-
Crack detection technology does indeed exhibit significant differences in performance under various environmental conditions, primarily influenced by environmental factors, crack characteristics, and the type of technology employed. In environments with good lighting conditions (outdoors, well-lit indoors), high contrast and clear images aid traditional image processing techniques in accurately identifying crack edges and textures. In environments with poor lighting conditions (tunnels, nighttime, shady areas), deep learning models that integrate image enhancement and segmentation algorithms[86,93] Can be trained to adapt to different lighting conditions, enabling the detection of cracks that would otherwise be difficult to discern. In complex background environments (rough surfaces, intricate textures), advanced image processing algorithms are typically employed[58,89], such as techniques based on local binary patterns or filters, which can highlight crack features and effectively detect cracks even on surfaces with complex or uneven textures.
Additionally, different types of cracks pose different requirements for detection technology, mainly because each type of crack has unique morphology, causes, and severity levels, necessitating targeted detection methods and techniques for accurate identification and assessment. Transverse cracks are relatively easier to detect, while longitudinal cracks pose a greater challenge. Wang & Hu[87] used CNN for detecting cracks and non-cracks. They classified three types of cracks, achieving high precision for transverse cracks, medium precision for longitudinal cracks at 0.97, and fatigue cracks at 0.90. Crack detection technology needs to be optimized for different types of cracks[88]. Surface cracks, which are typically shallow and distributed in a linear or reticular pattern, require higher image resolution and precision in image processing algorithms. Deep cracks, which may originate on the surface and extend inward, necessitate more penetrating detection techniques, such as ultrasonic or electromagnetic detection. The selection and application of crack detection technology should consider the type, characteristics, environmental conditions, and detection objectives of the cracks. By employing appropriate detection methods and equipment, cracks can be effectively identified and assessed, ensuring the integrity and safety of structures. As technology advances, future crack detection techniques are likely to become more intelligent, automated, and capable of adapting to a wider and more complex range of detection needs.
-
Future crack detection technology needs to be integrated with road maintenance strategies, where detailed crack data obtained through crack detection technology will be directly used in the formulation of road maintenance strategies. This data includes parameters such as the location, length, width, and depth of cracks, providing a scientific basis for maintenance decisions. For instance, deep learning-based crack detection systems can automatically measure these parameters, providing data support for maintenance teams to choose the most appropriate repair materials and methods. The integration of crack detection technology with road maintenance strategies helps optimize the allocation of maintenance resources. By analyzing the distribution and severity of cracks, it is possible to determine which areas need priority maintenance, allocate maintenance personnel, equipment, and materials rationally, and improve maintenance efficiency.
The future development trend of crack detection technology will focus on the in-depth application of multimodal data fusion, which integrates different types and sources of data to enhance the accuracy, efficiency, and reliability of crack detection. For instance, by combining image and thermal data, we can leverage the complementary advantages of visible light images and infrared thermographic data to more accurately identify cracks[92]. In difficult situations where surfaces are covered with dirt or paint, thermographic technology can reveal temperature differences caused by cracks, while visible light images provide rich detailed information. Jiang et al.[92] adopted a method combining infrared thermography technology with deep learning, proposing a model named GSkYOLOv5. This method processes infrared images, effectively reducing the impact of environmental interferences such as shadows and reflections. The experimental results showed an improvement of 4.7% in detection accuracy and 1.3% in recall rate. Moreover, the integration of drone and ground detection technology, by combining cameras mounted on drones and ground detection equipment[16,17,68], allows for crack detection from different angles and distances. Drones provide a broad perspective and access to hard-to-reach areas, while ground detection offers close-up detailed inspection, and their combination achieves comprehensive and meticulous monitoring of cracks.
In response to the rising cost of data acquisition, semi-supervised learning, and unsupervised learning methods will become new hotspots in research. In the field of crack detection, models can first be trained using a small number of professionally labeled crack images and then incorporate unlabeled image data. In this way, the model can enhance the accuracy of crack identification by learning common features of images. Semi-supervised learning enhances model performance by combining a small amount of labeled data with a large amount of unlabeled data for model training, leveraging the inherent structure of unlabeled data[110,111]. Unsupervised learning, on the other hand, does not rely on labeled data and directly mines patterns and structures from unlabeled data, widely applied to tasks such as clustering and association rule learning[37,63]. In crack detection, it can be used to recognize patterns of cracks in images, achieve automatic clustering of crack images, or reveal potential associations between cracks and other image features.
This approach of integrating multiple data and technologies not only enhances the capabilities of crack detection but also brings significant benefits to fields such as materials science and pavement engineering. It promotes technological innovation and knowledge integration, providing solid technical support for a sustainable future.
The potential for interdisciplinary collaboration
-
Through close collaboration with materials science, we can delve into how the microstructure, mechanical properties, and chemical composition of materials affect the initiation and propagation of cracks. This understanding allows us to tailor detection algorithms based on the characteristics of the materials, significantly enhancing the accuracy and efficiency of crack detection. Furthermore, studying the mechanisms of crack formation during material aging and damage not only helps us assess the overall health of materials through crack detection but also enables the development of predictive models to forecast the trajectory of crack growth and the remaining service life of the materials.
In the field of pavement monitoring and maintenance, applying crack detection technology to real pavement monitoring allows for the real-time assessment of pavement conditions and guides necessary maintenance and repair work, thereby improving the efficiency and effectiveness of pavement maintenance and effectively extending the service life of the pavement. Additionally, studying the behavior of cracks in pavements under different environmental conditions, such as temperature changes, humidity, and traffic loads, enables us to develop crack detection technologies that adapt to various environmental conditions. Utilizing this data feedback, we can also optimize pavement structural design, enhance the overall performance of the pavement, and reduce the occurrence of cracks.
This interdisciplinary collaboration not only enables crack detection technology to better adapt to diverse application scenarios, improving detection accuracy and efficiency, but also allows the fields of materials science and pavement engineering to significantly benefit from advancements in crack detection technology, achieving smarter, more economical, and more environmentally friendly solutions. Moreover, this collaboration promotes technological innovation and knowledge integration in related fields, providing strong support for sustainable development in the future.
-
This article reviews two main asphalt pavement crack detection technologies—digital image processing-based technology and machine learning-based technology. We have analyzed in detail the working principles, advantages, and challenges faced by each technology in practical applications.
Detecting cracks in asphalt pavement is a critical task to ensure the safety and service life of our roads. In this study, we reviewed the application of various image processing techniques and deep learning models in pavement crack detection. The conclusion drawn from the research is that deep learning-based methods used for crack image classification, localization, and segmentation show better performance than traditional computer vision techniques. Traditional image processing techniques work well in identifying cracks against simple backgrounds. However, road image data collected through cameras, drones, and other means may have many noise points, including uneven lighting, lanes, and stains. Therefore, it requires preprocessing operations such as grayscale conversion, histogram equalization, filtering, and morphological operations. Although this process can be time-consuming, obtaining high-quality data for effective crack detection is necessary. In terms of deep learning techniques, they show great superiority in handling large-scale data and diverse road conditions. However, they require substantial computing resources and ample datasets. To address this issue, one can start with the model's architecture, improving the model's processing capabilities for image data by changing the backbone network or optimizing the loss function. In addition to this, for crack datasets, selecting a feasible dataset for model training remains a significant challenge to be solved. Most researchers prefer to build their own datasets for research, enabling them to capture the specific requirements of the crack detection algorithms they use. High-quality and publicly available crack datasets are relatively scarce. Moreover, cracks are three-dimensional shapes with length, width, and depth. Researchers mostly focus on studying surface cracks of the road, and there is also a lack of research on detecting 3D crack datasets.
Digital image processing-based technologies are widely used in preliminary crack detection due to their relative maturity and lower implementation costs. These technologies perform well in identifying cracks under simple scenarios and standard conditions but are often sensitive to complex backgrounds and varying lighting conditions, with room for improvement in terms of automation and precision. On the other hand, machine learning-based technologies, especially those based on deep learning, have shown tremendous potential in handling complex images and automating the learning of crack features. Although these technologies require substantial computational resources and data, they offer significant advantages in accuracy and adaptability, particularly in environments that require processing large-scale data and diverse road conditions.
Future research should focus on several directions: first, developing more efficient data collection and processing technologies to reduce reliance on high-performance computing resources while optimizing algorithms to improve operation efficiency in resource-constrained environments. Second, exploring multimodal data fusion technologies that combine traditional image data with other sensor data (such as infrared, acoustic, etc.) to enhance the accuracy and robustness of crack detection. Additionally, research should intensify the development of semi-supervised and unsupervised learning methods to overcome the difficulty of obtaining large-scale annotated data. Lastly, interdisciplinary collaboration will be key to advancing this field, combining the latest research findings from materials science, pavement engineering, and artificial intelligence to provide more comprehensive and effective solutions for road maintenance and safety management. Through these efforts, there is hope to achieve smarter and more automated road maintenance systems, providing a safer and more reliable driving environment for road users.
This research was supported by the National Natural Science Foundation of China (52208424); the Natural Science Foundation of Chongqing Municipality (2022NSCQ-MSX1939); Chongqing Municipal Education Commission Foundation (KJQN202200745, KJQN202300728); Technology Innovation and Application Development Special Foundation of Chongqing (CSTB2022TIAD-GPX0083); the China Postdoctoral Science Foundation (2022M710545); and Chongqing Transport Bureau; Chongqing Jiaotong University, China. The authors gratefully acknowledge their financial support.
-
The authors confirm contribution to the paper as follows: study conception and design: Huang S, Bi Y; data collection: Chen H, Yan L; analysis and interpretation of results: Huang S, Zou X; draft manuscript preparation: Huang S, Li B. All authors reviewed the results and approved the final version of the manuscript.
-
All data generated or analyzed during this study are included in this published article. The raw data and processed datasets are available from the corresponding author on reasonable request.
-
The authors declare that they have no conflict of interest.
- Copyright: © 2025 by the author(s). Published by Maximum Academic Press, Fayetteville, GA. This article is an open access article distributed under Creative Commons Attribution License (CC BY 4.0), visit https://creativecommons.org/licenses/by/4.0/.
-
About this article
Cite this article
Huang S, Chen H, Yan L, Zou X, Li B, et al. 2025. A review of the progress in machine vision-based crack detection and identification technology for asphalt pavements. Digital Transportation and Safety 4(1): 65−79 doi: 10.48130/dts-0025-0006 

A review of the progress in machine vision-based crack detection and identification technology for asphalt pavements
- Received: 15 October 2024
- Revised: 08 January 2025
- Accepted: 05 February 2025
- Published online: 31 March 2025
Abstract: With the aging of transportation infrastructure and the increasing frequency of use, the detection and identification of cracks in asphalt pavements are crucial for ensuring road safety and maintenance efficiency. Traditional manual inspection methods are not only inefficient and limited in accuracy but also susceptible to subjective factors and environmental conditions. In contrast, machine vision-based crack detection technology enhances the efficiency and reliability of detection through automated image acquisition and analysis processes. This article reviews the latest advancements in machine vision-based crack detection technology for asphalt pavements, with a particular focus on the applications of digital image processing and deep learning. Although image processing-based methods perform well in detecting cracks against simple backgrounds, they exhibit poor robustness under complex lighting and background conditions. On the other hand, deep learning-based methods, while effectively handling complex image data, rely on large amounts of annotated data and significant computational resources. Through critical analysis, the article evaluates the strengths and weaknesses of existing technologies and looks forward to future research directions that integrate multiple sensing data and automated data annotation tools, aiming to further advance and innovate road maintenance technology.