








-
Global food security faces unprecedented challenges as the World Food Programme (WFP) projects that 343 million people across 74 countries will experience acute food insecurity by 2025. Rice, a staple crop supporting over half of the world's population, stands at the forefront of agricultural research[1]. Current estimates indicate a 130% surge in global rice consumption from 2010 levels by 2035, necessitating an additional 30 million tons annually to meet escalating demand[2].
The genus Oryza includes two cultivated rice species, Asian rice (Oryza sativa) and African rice (O. glaberrima), along with over 20 wild relatives[3], collectively representing a vast genetic repository shaped by divergent evolutionary histories. Maintained by the International Rice Research Institute (IRRI), the International Rice Genebank holds more than 132,000 available accessions as of December 2019 with O. sativa dominating agricultural systems through its subdivision into the japonica and indica subspecies. Together, these species represent an evolutionary mosaic of phylogenetic diversity, offering untapped reservoirs of stress tolerance and adaptive traits forged across diverse agroecological niches[4,5].
Advances in sequencing technologies and genome assembly algorithms have revolutionized rice genomics, enabling high-resolution exploration of its genetic architecture[6]. To date, researchers have generated chromosome-level or even complete genome assemblies for hundreds of rice varieties[7], while large-scale resequencing efforts have characterized genetic diversity across diverse germplasm collections. These endeavors have culminated in the development of pan-genomes spanning intervarietal and even intragenus boundaries, capturing structural variations (SVs)[8], single nucleotide polymorphisms (SNPs), and insertions/deletions (InDels) at unprecedented scales. Such resources are critical for identifying rare alleles, beneficial natural variants, and novel haplotype combinations that underpin agronomic traits. Because of low sequencing depth, merely at 1×, structural resolution and causal gene identification remained elusive. Besides, sequencing data often show overlaps.
Concurrently, the exponential growth of rice genomic data has driven the creation of specialized platforms, including Rice Variation Map v2.0 (RiceVarMap2)[9,10], Rice Super Pan-genome Information Resource Database (RiceSuperPIRdb)[11], and the Rice Pan-genome Browser (RPAN)[12], which integrate multidimensional datasets with analytical tools to facilitate gene discovery and breeding applications. Modern plant breeding harnesses cutting-edge GS platforms like CropGS-Hub[13], BreedingAIDB[14], and Smart Breeding Platform[15]. These tools combine the power of machine learning (ML) and deep learning (DL) to analyze genetic and phenotypic data, significantly speeding up the breeding process.
However, rice population genomics now confronts dual frontiers, managing petabyte-scale data challenges and harnessing AI-driven insights across multi-omics layers. While cloud architectures address storage and computational bottlenecks posed by sequencing over 10,000 accessions, critical gaps persist in interpreting nonlinear genotype-environment interactions—a limitation exacerbated by the 'black box'[16] nature of DL models like AgroNT[17], despite their success in predicting cis-regulatory elements. Simultaneously, spatial genomics maps 3D chromatin interactions to resolve noncoding structural variants' roles in stress adaptation, yet scalable 3D omics technologies remain nascent[18]. Through federated learning frameworks and equitable data sharing, the integration of these domains will define the next decade of breeding innovation, balancing computational scalability with biological interpretability to accelerate climate-resilient cultivar development.
This review synthesizes advances in rice population genomics, focusing on the integration of large-scale resequencing data and pan-genome frameworks, the interrogation of genomic diversity to decode domestication and adaptation mechanisms, and the translation of these insights into precision breeding strategies. We further explore challenges in data harmonization and the ethical implications of genomics-driven agriculture.
-
The nascent era of rice population genomics (2010−2015) was characterized by pioneering yet depth-constrained studies, where seminal efforts laid the groundwork despite technical limitations[19]. In 2010, a pioneering study of 517 Chinese landraces established an integrative approach combining second-generation sequencing at merely 1× depth and genome-wide association studies (GWAS)[20], demonstrating its utility as a complementary strategy to classical biparental mapping for dissecting complex agronomic traits. By 2012, this methodology had been scaled to analyze 950 worldwide cultivars at the same depth, identifying 32 novel loci associated with flowering time and grain morphology[21], thereby expanding the scope of rice genetic architecture exploration from regional landraces to global diversity. Low sequencing depth underscored both the potential and constraints of early next-generation sequencing (NGS) frameworks, enabling broad variant surveys, yet structural resolution and causal gene identification remained elusive.
These foundational efforts culminated in 2018 with the landmark 3,000 Rice Genomes Project (3K-RG)[22], which resequenced 3,010 Asian cultivars to delineate subpopulation structures and provide evidence for multiple domestication origins. While this initiative cataloged 29 million SNPs and 90,000 structural variants (SVs), only 430 accessions exceeded 20× coverage, and reliance on short-read sequencing inherently limited SV detection, particularly in complex genomic regions[23], particularly those spanning complex genomic regions (Table 1).
Table 1. Summary of landmark rice population genomics studies.
Rice type Number of accessions Sequencing method Key results Sparking point Ref. Published year 129 O. rufpogon and 16 O. sativa 145 ONT (103×), PacBio HiFi (24×) and NGS 69,531 pan-genes, with 28,907 core genes and 13,728 wild-rice-specific genes Supports Asian rice's monophyletic origin from Or-IIIa (japonica ancestor) [33] 2025 Chinese cultivars 6,044 NGS (31×) 3,131 QTLs for 53 traits; cloned OsGL3.6 regulating grain length Unprecedented QTL scale with direct breeding applications [32] 2025 Asian cultivars 18,421 ONT (69×) and NGS (100×) on founders and NGS (0.3×) on F2 1,207 QTLs for 16 traits; validated OsMADS22 and OsFTL1 Hybrid sequencing resolves QTL-phenotype causality [34] 2024 73 Asian rice and two wild relatives 75 Pacbio HiFi (18×) 1,769 large inversions (≥ 100 bp) in pan-genome First pan-genome landscape defining and validating inversion dynamics in rice [31] 2024 Inbred lines 12 PacBio HiFi (30×) 47,490 gene families, 489,713 genes and heterosis of 17 agronomic traits SV-heterosis mechanism bridge structural and regulatory evolution [35] 2024 Wild rice 17 PacBio HiFi (60×) and NGS (100×) 101,723 gene families including 63,881 gene families absent in cultivated Loss of some resistance genes in cultivated rice during domestication and artificial selection [30] 2024 2,839 hybrid cultivars and 9,839 F2 12,678 NGS (F1 35×; F2 0.2×) 5.2 million SNPs, 1.7 million InDels and 22,555 SV Heterosis decoded and developed a genomic model [36] 2023 11 wild, 51 cultivated and 12 weedy rice 74 PacBio HiFi (32×) 175,528 syntelog groups in a syntelog-based pangenome with putative introgression regions Constructed syntelog-based pangenome [29] 2023 Northeast Asian cultivars 546 NGS (10×) 111 known QTLs genotyped and novel GWAS-QTLs Summarized a rice breeding principle [37] 2023 Indian rice landraces 108 ONT (20×) and NGS (67×) 7415 and 131 differentially expressed transcripts and miRNAs Identified miRNAs and their target genes in regulating anthocyanin biosynthesis [38] 2022 Asian and African rice 251 ONT (100×) and NGS (65×) 1.52 Gb non-redundant DNA sequences in pan-genome Revealed extensive SVs associated with grain weight and gene PAV [39] 2022 O. sativa and wild relatives 111 ONT (68×) and NGS (69×) 879 Mb novel sequences and 19,000 novel genes in the rice pan-genome New pan-genome construction method for long-read data [28] 2022 32 O. sativa and 1 O. glaberrima 33 PacBio (60×), and NGS (20×) 171,072 SVs and 25,549 gCNVs underlying environmental adaptation SV-adaptation nexus across species boundaries [27] 2021 299 papers published from 1995 to 2020 / / 562 alleles in 225 QTGs and 348 QTNs A comprehensive QTN map and genome navigation systemin of rice [40] 2021 Chinese cultivars 1,275 NGS (7×) 143 association loci, including three new genes, control heading date or amylose content GWAS-powered gene prioritization framework [41] 2020 53 O. sativa and 13 O. rufipogon 66 NGS (115×) 23 million sequence variants include many known QTNs Variant-to-QTN translation bridges genomics and breeding [42] 2018 Asian cultivars 3,010 NGS (18×) 29 million SNPs, 2.4 million indels, and over 90,000 SVs Domestication model challenger via population structure [22] 2018 10,074 F2 lines from 17 hybrid rice crosses 10,074 NGS (0.2×) A dense genotype map with 347,803 recombination events; 74 QTLs for seven yield traits Dominance theory revived in hybrid rice [43] 2016 Hybrid rice (F1) 1,495 NGS (2×) 38 agronomic traits and 130 associated loci Hybrid trait architecture blueprint [44] 2015 Asian cultivars and landraces 1,479 NGS (3×) 6,428,770 SNPs total and 200 selected regions between IndI and IndII Breeding signatures between IndI and IndII including loci associated with agronomic traits [45] 2015 446 O. rufipogon and 1,083 cultivated varieties 1,529 NGS (2×) 5,037,497 non-singleton SNPs and 55 selective sweeps Domestication geography redefined [46] 2012 Worldwide cultivars 950 NGS (1×) 32 new loci associated with flowering time and with ten grain-related traits Extend to a larger and more diverse sample of rice varieties [21] 2012 Chinese landraces 517 NGS (1×) GWAS of 14 traits via 3.6M SNPs in 517 indica landraces Complex trait genomics and GWAS on crop pioneer [20] 2010 The advent of third-generation sequencing (TGS) technologies catalyzed a paradigm shift in rice genomics, enabling the de novo assembly of gap-free genomes[24−26] and the systematic exploration of SVs at population scales. In 2021, a study of 33 O. sativa and O. glaberrima accessions systematically identified over 170,000 SVs[27], linking these genomic rearrangements to environmental adaptation. This milestone laid the groundwork for the first comprehensive rice pangenome in 2022, which integrated 111 high-quality genomes, including wild relatives, and uncovered 879 Mb of non-redundant sequences enriched with stress-responsive genes[28]. Wild rice contributions, particularly long terminal repeat (LTR) retrotransposons, highlighted their role in shaping adaptive diversity.
Subsequently, the field witnessed a surge in super-pangenome initiatives. By 2023, a global consortium analyzed 10,548 accessions using multi-platform sequencing[11], cataloging rare alleles and establishing a framework for trait mining across agroecological zones. Concurrently, a synteny-based super-pangenome of 74 wild[29], cultivated, and weedy rice strains resolved introgression events and domestication signatures, demonstrating a single origin of japonica followed by adaptive hybridization. Wild rice genomes were further prioritized, and an analysis of 17 wild accessions revealed extensive subgenomic exchanges and regulatory variations that underpin stress resilience[30].
These resources have transitioned from structural catalogs to functional breeding tools. In 2024, haplotype-resolved assemblies of 75 Asian rice and wild relatives pinpointed large inversions (≥ 100 bp) as drivers of heterosis[31], while a 2025 analysis of 6,044 Chinese cultivars linked 3,131 QTLs to 53 agronomic traits[32], enabling the cloning of grain-length regulator OsGL3.6. Resequencing data in genomic databases often shows overlap, meaning some data is sequenced multiple times across different studies. Based on the information provided, it seems likely that there are 57 instances where the current 6,044 data duplicates earlier efforts compared to an initial set of 517 datasets. Additionally, other research efforts also exhibit similar overlaps, but these newer datasets have significantly deeper sequencing, which can improve accuracy and detail in digging target QTLs.
-
The rapid expansion of rice genomic resources has spurred the development of specialized databases that harmonize large-scale data storage with analytical functionalities (Table 2). Leading these efforts, RiceVarMap[9,10] serves as a cornerstone platform, integrating high-quality genotypes, GWAS linkages, and variant annotations for 4,726 cultivars, enabling trait dissection at unprecedented resolution. At the scale frontier, RiceSuperPIRdb[11] aggregates reference-grade assemblies from 10,904 wild and cultivated rice accessions, constructing a super pan-genome that captures structural diversity across subpopulations. Complementing these resources, RPAN[12] consolidates 3,010 accessions with pan-genome annotations, presence-absence variations (PAVs), and expression datasets, while RiceAtlas[47] bridges phenotypic and genomic heterogeneity across 3,733 germplasms through ML datasets. Notably, the Rice Gene Index[48] (RGI) pioneers multi-accession gene relational networks, mapping transcriptome dynamics across tissues and developmental stages, a critical resource for evolutionary and functional studies. These platforms collectively address three bottlenecks: standardization of heterogeneous data types (SNPs, SV, epigenetics), visualization of complex pan-genome architectures, and democratization of computational tools for non-specialists.
Table 2. Databases for rice population genomics data storage with online visualization function.
Database Number of cultivars Description Ref. URL RiceVarMap 4,726 High quality and complete genotype data; Comprehensive annotations of genomic variations; Phenotype data and GWAS results and tools [9,10] https://ricevarmap.ncpgr.cn/ RiceSuperPIRdb 356 (TGS),
10,548 (NGS)The super pan-genome based on reference-quality de novo long-read assemblies accessions [11] http://ricesuperpir.com/ RGI 16 Establishes gene relationships between different accessions and contains transcriptomes across different accessions and tissues [48] https://riceome.hzau.edu.cn/ RPAN 3,010 Consolidates 3,010 accessions, pan-genome annotations, PAVs, expression data, and analytical tools [12] https://cgm.sjtu.edu.cn/3kricedb/ RiceAtlas 3,733 Integrates large-scale rice phenotypic, genomic variation, and germplasm information [47] http://60.30.67.242:18076/#/home Rice Genome Hub 32 Reference genomes of 10 species in Oryza / https://rice-genome-hub.southgreen.fr/ OryzaGenome 466 A collection of short reads from 217 accessions covering 19 Oryza species and 446 O. rufipogon SNP viewer [49,50] http://viewer.shigen.info/oryzagenome21detail/ RiceRc 33 Integrates a genome browser and a BLAST function and includes the ancestral allele data for SNP/Indels [21] http://ricerc.sicau.edu.cn/ RAP-DB 685 Facilitates a comprehensive analysis of the genome structure and function of rice on the basis of the annotation [54,55] https://rapdb.dna.affrc.go.jp/ MBKbase-rice 137,796 Integrates rice germplasm information, reference genomes with gene loci, phenotypic and gene expression data [56] https://www.mbkbase.org/rice Rice3KGS 3K LGBMY GS model with a dataset of 56 trait phenotypes and seven genotype datasets. [57] http://101.201.107.228:8002/#/Rice3KGS/home/ AutoGP / A dataset of 143,477 rice G2P paired data for 41traits [58] http://autogp.hzau.edu.cn CropGS-Hub 2,578 Over 224 billion genotype data and 434 thousand phenotype data generated from >30 000 individuals belonging to 7 major crop species [13] https://iagr.genomics.cn/CropGS/#/ BreedingAIDB 415 129,449 rice genome-to-phenotype paired data [14] http://ibi.zju.edu.cn/BreedingAIDB/ Smart Breeding Platform / Various statistical analyses, GWAS and GS using both classical ML and DL models [15] https://sbp.ibreed.cn/#/ Emerging niche repositories further enrich this ecosystem. The Rice Genome Hub (RGH) provides evolutionary context through 32 reference genomes spanning 10 Oryza species, enabling comparative genomics at taxonomic depth. OryzaGenome[49,50] specializes in SNP discovery across 466 accessions from 19 wild relatives, featuring allele effect predictors for adaptive trait mining. For translational research, Rice Resource Center (RiceRc)[21] offers ancestral allele reconstruction across 33 cultivars, aiding the identification of domestication signatures and breeding targets. Future iterations must prioritize Findable, Accessible, Interoperable, Reusable (FAIR)[51] data principles and cloud-native architectures to enable federated queries across these distributed resources.
Modern plant breeding harnesses advanced GS platforms, such as CropGS-Hub[13], with its six ML models (BayesCπ, Bayesian Lasso, Bayesian Regression, GBLUP, RR-BLUP, and LightGBM)[52,53], BreedingAIDB[14] for boosting-type algorithms, and the Smart Breeding Platform[15] combining ML and DL to streamline trait optimization and breeding cycles. By integrating genotype-to-phenotype workflows, breeders can rapidly engineer climate-resilient crops, exemplified by drought-tolerant rice development. Starting with 500 rice accessions phenotyped for drought-related traits (e.g., root depth) and resequencing data uploaded to platforms like Smart Breeding Platform, automated SNP calling, and GWAS pinpoint loci linked to drought adaptation, while GS models predict progeny performance, enabling strategic crosses and early-generation selection of high-scoring individuals. Iterative genomic filtering across generations concentrates favorable alleles, minimizing field trialing of low-potential lines and compressing breeding timelines by ~50%, with elite drought-tolerant varieties advancing to multi-environment testing within 3–4 years. Such platforms democratize precision breeding, merging computational power with biological insight to address global agricultural challenges.
-
Advances in rice population genomics have systematically decoded the genetic architecture of agronomic traits through large-scale sequencing and multi-omics integration[59]. By analyzing global germplasm spanning wild, landrace, and modern cultivated rice, researchers identified key loci governing critical traits (Fig. 1). In 2016, GWAS using a high-density rice array (HDRA) of 700,000 SNPs identified OsSPL13 as a key gene simultaneously enhancing grain length, panicle grain number, and yield[60], while subsequent work in 2018 revealed OsSAP16 as a critical regulator of low-temperature germination, expanding the molecular toolkit for stress-resilient rice breeding[61]. Recent advances in GWAS have integrated multi-omics approaches, including transcriptome-wide (TWAS), proteome-wide (PWAS), and metabolome-wide (MWAS) association analyses—to pinpoint target traits for precision breeding. For instance, a landmark study combining GWAS with TWAS and methylome profiling deciphered the genetic architecture underlying rice glycemic index (GI), identifying OsAmy3D[62] as a key amylase gene regulating starch digestion rates. Similarly, volatilome-based GWAS revealed OsWRKY19 and OsNAC021[63] as master regulators of 2-acetyl-1-pyrroline biosynthesis, the compound responsible for aromatic fragrance in premium rice varieties. This shift from simplex to multi-omics and data-driven strategies has significantly accelerated the development of high-yielding, stress-resilient varieties.
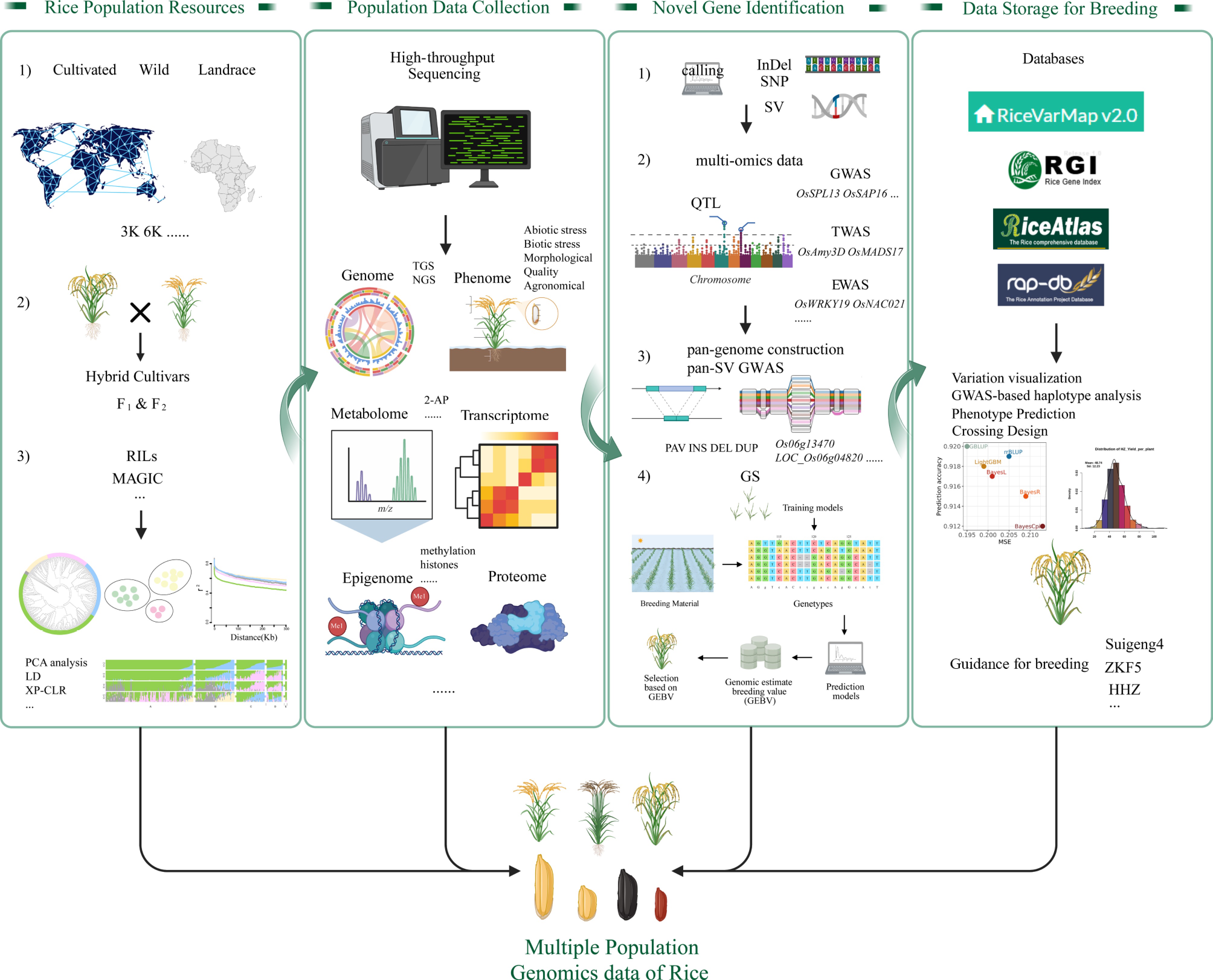
Figure 1.
The integrative framework of population genomics and multi-omics approaches for advancing rice breeding. Key components include: (1) Rice population resources, encompassing cultivated varieties, wild relatives, landraces, hybrid cultivars (F1/F2), recombinant inbred lines (RILs), multi-parent advanced generation inter-cross (MAGIC) populations, and so on. (2) High-throughput data collection across genomic, phenomic, transcriptomic, epigenomic, proteomic, and metabolomic layers. (3) Novel gene discovery strategies, leveraging pan-genome analyses (SNPs, InDels, structural variations), genome-wide association studies (GWAS), and genomic selection (GS). (4) Data storage and breeding applications featuring databases (RiceVarMapv2.0, RGI) that guide cultivar development (e.g., ZKF5, HHZ, Sujgeng4). Collectively, this big data-driven paradigm accelerates the identification of agronomically vital traits and informs precision breeding strategies to enhance global rice productivity and resilience.
While single-gene discoveries provide foundational insights, the phenotypic manifestation of traits is often shaped by intricate epistatic interactions and genetic background dependencies. A 2024 analysis of 18,421 rice lines uncovered 70 significant locus pairs with additive effects[34], illustrating how genes like the semi-dwarf Sd1 modulate eight distinct traits through context-dependent interactions. Similarly, Ghd8 was shown to influence grain protein content only in specific haplotypes of Ehd1, underscoring the limitations of reductionist approaches. Population genomics addresses this complexity by mapping genome-wide interaction networks, empowering breeders to select germplasm with compatible genetic backgrounds. This paradigm ensures stable trait expression, mitigating risks of allele dilution or pleiotropic trade-offs in diverse environments. While integrative pan-genome, GWAS, and GS approaches may not directly identify novel genes, they systematically uncover pleiotropic functions in previously characterized loci. For example, Ghd7[64], initially recognized as a heading date regulator, has been shown through population allele mining to coordinate yield-related traits, including plant height and panicle architecture, demonstrating how multi-trait optimization emerges from revisiting 'known' genes.
While traditional analyses primarily rely on population SNPs or small InDels, TGS of rice populations now enables comprehensive characterization of SVs, including gene presence/absence polymorphisms that are often undetectable with NGS. The first TGS-based pan-genome, distinct from earlier approaches like the 3K-RG project that mapped short reads to reference genomes, was constructed by comparing 12 high-quality de novo genome assemblies generated from PacBio long-read data (> 100× coverage). Subsequent TGS pan-genomes, such as the 33-TGSRG and 251-TGSRG, have revealed SVs with direct agronomic relevance. For example, a 987-bp LTR insertion upstream of Os06g13470[27] was linked to premature leaf senescence, while SV-based GWAS identified a 4-kb insertion disrupting LOC_Os06g04820[39] function, reducing grain length. These advancements underscore the critical role of SVs in bridging genomic diversity to trait improvement.
Decoding population structure for elite germplasm utilization
-
Classified into nine subpopulations, including four indica clusters and three japonica clusters, the 3K-RG accessions bring more resolution to the within-species diversity of large numbers of SNPs, InDels, and SVs. This granular stratification not only clarifies the monophyletic origin of Asian rice but also pinpoints underutilized rare alleles in peripheral groups, such as drought-responsive OsNAC6[65] haplotypes unique to the aus subpopulation. Leveraging inbreeding coefficient profiles and homozygous genomic blocks, breeders can now avoid parental combinations with excessive genetic similarity (> 85% identity-by-descent), mitigating inbreeding depression risks in hybrid programs. Population differentiation analyses such as FST further dissected ecological adaptation mechanisms, a photoperiod sensitivity gene divergently selected in low-latitude (high-temperature) versus high-latitude (short-day) ecotypes.
A comprehensive study of 6,044 Chinese rice accessions delineated five major growing regions: Southern China (SC), Central China (CC, subdivided into CC-I and CC-J), Southwest China (SW, with SW-I and SW-J), Northern China (NC), and Northeast China (NE)[32]. This diversity panel uncovered distinct genomic backgrounds associated with regional adaptation, including localized selection for key agronomic traits such as heading date, biotic/abiotic stress resistance, and grain morphology—critical factors in matching crop performance to environmental constraints and consumer demands.
Leveraging big data to build predictive breeding models
-
Building on these genomic insights, the integration of AI has ushered in a transformative era of predictive breeding[66]. GS models, trained on vast datasets of hybrid and inbred lines[67], now forecast trait performance with unprecedented accuracy. Furthermore, DL-based models have shown competitive or even better capability than traditional models. According to model architectures and various development strategies, three advancements can be categorized: CNN-based architectures (DeepGS[68], DNNGP[69], Foundations[70], and SoyDNGP[71]); transformer-based architectures (GPformer[72] and Cropformer[73]; automated frameworks (Auto-GS[74] and AutoGP[58]), and others (TrG2P[75] and DEM[76]).
In 2024, a maize breeding initiative enhanced yield optimization across 64,620 potential hybrid candidates through ML[77], which has since been extensively applied to wheat[78] and soybean[71] breeding programs, as well as resistance gene research in Spartina alterniflora[79]. In addition, DeepCCR[70] , tailored to Chinese rice population data, demonstrates robust capability in predicting phenotypic traits and identifying ecological regions optimal for cultivation. The growing availability of multi-omics datasets in rice research is poised to further advance the development of refined ML frameworks. Beyond trait prediction, AI-driven tools decode nonlinear relationships between structural variations and phenotypes, enabling the deployment of rare alleles, such as anthocyanin biosynthesis regulators from stress-adapted landraces, into elite backgrounds. This synergy of genomics and computational intelligence not only refines directional breeding but also pioneers climate-smart crop design, where adaptive traits are engineered through iterative modeling.
-
Despite substantial progress, significant challenges persist in this field. The foremost challenge in crop genomics lies in managing the exponentially growing data lifecycle, from collection and sequencing to storage, transmission, and interpretation. Establishing comprehensive germplasm repositories faces inherent logistical barriers, particularly for acquiring rare wild rice varieties and landraces essential for biodiversity preservation. Modern sequencing efforts now routinely generate petabyte-scale datasets, exemplified by recent studies producing 60.78 Tb of 150-bp paired-end reads from 5,164 rice accessions[32]. Storing such Oryza genomic resources would require over 300 3TB hard drives (occupying about 15 m²), while transferring these datasets at 50 Mb/s bandwidth demands > 200 d—challenges dwarfed by polyploid species like Brassica napus (AACC, 1.1 Gb genome size)[80] and Triticum aestivum (AABBDD, 16 Gb genome size)[81], where sequencing complexity escalates exponentially. Traditional analysis frameworks, reliant on local data transfers and on-premise computation, falter under such scales. Cloud-based architectures address these limitations by enabling direct data access and scalable computational resources. A key innovation lies in the automated management of intermediate files, which are systematically purged during virtual machine termination. This approach not only reduces physical infrastructure burdens but also standardizes data hygiene, enhancing reproducibility across studies.
Current pan-genomic studies, encompassing thousands of rice accessions, have cataloged vast structural and allelic variations linked to stress resilience, grain quality, and yield. Integrating transcriptomic, epigenomic, and metabolomic datasets will enable precise annotation of cryptic genes and their interaction networks, moving beyond static variant catalogs to dynamic functional insights. Emerging single-cell sequencing technologies further promise to resolve spatiotemporal gene expression patterns, unraveling the genetic regulation of complex traits such as root architecture or drought-responsive metabolic pathways.
Integrating AI and GS with multiscale genomic data
-
AI and GS models are poised to revolutionize rice breeding paradigms. The rapid evolution of AI technology has established large language models (LLMs) as a pivotal, transformative force within the AI domain. The rapid development of plant-specialized LLMs, including Genomic Pre-trained Network (GPN)[82], GPN-MSA (GPN with multiple-sequence alignment)[83], AgroNT (1 billion parameters)[17], FloraBERT[84], and Plant DNA LLMs (PDLLM)[85] are revolutionizing genomic interpretation through their capacity to decode complex biological patterns. Among these, AgroNT stands out by establishing new benchmarks in predicting cis-regulatory elements (promoters/terminators), tissue-specific transcriptional dynamics, and functional variant prioritization. This computational capacity aligns strategically with the explosive growth of rice population genomics data, where traditional methods struggle to scale. By pre-training on terabase-scale genomic sequences, these LLMs systematically uncover nonlinear relationships and epigenetic dependencies that govern trait formation, a capability critical for annotating millions of rice genomic variants with functional impact scores. Such genome-to-phenome predictive frameworks could transform genetic resource utilization, enabling targeted screening of agriculturally valuable alleles while reducing experimental validation costs. However, significant challenges impede the effective application of LLMs in rice genomics. The field's characteristic 'big data' challenges, which include enormous data volumes, high dimensionality, and intricate biological complexity, create unprecedented computational and storage demands. Moreover, the inherent opacity of DL architectures presents a critical bottleneck. While these models demonstrate impressive predictive accuracy across multiple tasks, their decision-making processes remain largely opaque 'black boxes', severely limiting biological interpretability and hindering researcher trust. This interpretability crisis persists despite model performance improvements, creating a fundamental barrier to translating computational predictions into actionable biological insights.
GS, initially developed for livestock breeding in 2001, has transformed plant breeding through methodologies such as genomic best linear unbiased prediction (GBLUP) and ridge regression BLUP (rrBLUP). Platforms like AutoGP[58] harness large-scale rice genotype-to-phenotype (G2P) datasets, comprising 143,477 accessions and 41 agronomic traits of rice, to refine breeding value prediction. Multispecies frameworks such as CropGS-Hub[13] integrate ML with genomic data, optimizing crossbreeding strategies and allele prioritization in key crops. Future advancements require overcoming critical challenges: cost-effective genotyping arrays for underrepresented germplasm, high-throughput phenotyping systems with micron-level precision, computational efficiency in model training, and adaptive parameter optimization to address nonlinear genotype-environment interactions. Addressing these hurdles will catalyze next-generation breeding frameworks, enabling the systematic development of climate-resilient cultivars through predictive genotype-environment models.
Blueprints of population spatial genomics
-
The integration of three-dimensional chromatin architecture and population-scale genomic data is transforming rice genomics by bridging structural, functional, and evolutionary insights[86]. Spatial chromatin interaction maps enable functional annotation of noncoding structural variants, revealing their roles in disrupting regulatory circuits at domain boundaries or driving adaptive chromatin states linked to stress resilience. Evolutionary constraints identified through conserved chromatin hubs and plasticity hotspots offer critical design principles for breeding, distinguishing immutable genomic regions from dynamic targets for trait optimization. Overcoming barriers in scalable 3D omics technologies, multidimensional data integration, and equitable data sharing will unlock 'structural intelligence' breeding, precisely editing spatial interaction modules to engineer climate-resilient rice while minimizing unintended pleiotropic effects. This paradigm shift promises to accelerate the development of adaptive crop varieties tailored to future agricultural challenges.
Looking ahead, the integration of these frontiers will catalyze a shift from reactive to anticipatory crop improvement.
-
The authors confirm contribution to the paper as follows: study conception and design: Zhou Y; draft manuscript preparation: Zhou Y; writing - review and editing: Zhou Z. Both authors reviewed the draft manuscript and approved the final version of the manuscript.
-
Data sharing is not applicable to this article as no datasets were generated or analyzed in this review.
-
The authors declare that they have no conflict of interest.
-
# Authors contributed equally: Yuhan Zhou, Ziqi Zhou
- Copyright: © 2025 by the author(s). Published by Maximum Academic Press, Fayetteville, GA. This article is an open access article distributed under Creative Commons Attribution License (CC BY 4.0), visit https://creativecommons.org/licenses/by/4.0/.
-
About this article
Cite this article
Zhou Y, Zhou Z. 2025. Unlocking rice's genetic potential: big data-driven insights from population genomics. Genomics Communications 2: e012 doi: 10.48130/gcomm-0025-0012 

Unlocking rice's genetic potential: big data-driven insights from population genomics
- Received: 06 April 2025
- Revised: 16 May 2025
- Accepted: 26 May 2025
- Published online: 26 June 2025
Abstract: Rice, a cornerstone of global food security, faces escalating demand amidst climate-driven agricultural challenges. By integrating data from over 10,000 cultivated and wild rice accessions, researchers have resolved structural variations, domestication trajectories, and adaptive alleles critical for stress resilience and yield improvement. From five major rice-growing regions in China, the newly expanded 6K genomic atlas revealed 3,131 quantitative trait loci associated with 53 phenotypes across 212 datasets under various environmental conditions. Platforms like RiceSuperPIRdb and RiceAltas integrate multidimensional datasets with visualization tools, bridging genetic discovery to breeding applications. Artificial intelligence (AI) models trained on 12,678 hybrid profiles predict heterosis with > 85% accuracy, while platforms such as AutoGP integrate genotype extraction, phenotypic extraction, and genomic selection (GS) models to halve breeding cycles. Yet, petabyte-scale data from initiatives challenge traditional storage and analysis frameworks, necessitating cloud-based architectures and interpretable AI to resolve nonlinear genotype-phenotype relationships. Single-cell multi-omics and 3D genome mapping now dissect spatiotemporal gene regulatory networks, transforming empirical breeding into a predictive science despite enduring bottlenecks in data standardization and equitable resource sharing. This synthesis underscores the pivotal role of population genomics in harnessing rice's evolutionary legacy to meet twenty-first-century food security imperatives.
-
Key words:
- Rice genome /
- Population genomics /
- Crop breeding